目录
一.
BeautifulSoup 是什么?
解析和提取网页中的数据:
解析数据
:把服务器返回来的 HTML 源代码翻译为我们能理解的方式;
提取数据:
把我们需要的数据从众多数据中挑选出来;
1.1
BeautifulSoup 安装
win:pip install BeautifulSoup4;
Mac:pip3 install BeautifulSoup4;
1.2
BeautifulSoup 解析数据

bs对象 = BeautifulSoup(要解析的文本,’解析器’)
括号中,要输⼊两个参数:
- 第 0 个参数是要被解析的⽂本(必须是字符串)
- 第 1 个参数⽤来标识解析器,我们要⽤的是⼀个Python内置库:html.parser。(不是唯⼀的解析器)
import requests
from bs4 import BeautifulSoup
#引入BS库
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
res = requests.get('https://localprod.pandateacher.com/python- manuscript/crawler-html/spider-men5.0.html')
html = res.text
soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象
1.3
BeautifulSoup 提取数据

1)
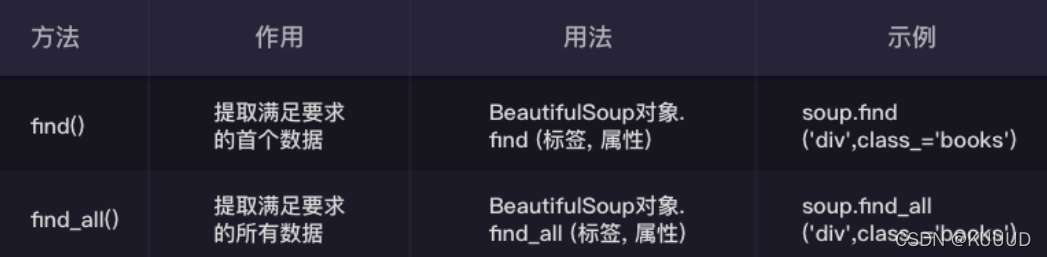
find() 与 find_all()的用法:
find() 与 find_all() 是 BeautifulSoup 对象的两个方法,它们可以匹配 html 的标签和属
性,把 BeautifulSoup 对象里符合要求的数据都提取出来
:
-
find()只提取首个满足要求的数据:
import requests
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
res = requests.get (url)
soup = BeautifulSoup(res.text,'html.parser')
item = soup.find('div') #使用find()方法提取首个<div>元素,并放到变量item里。
print(item) #打印item
#结果:<div>大家好,我是一个块</div>-
find_all()提取出的是所有满足要求的数据:
import requests
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
res = requests.get (url)
soup = BeautifulSoup(res.text,'html.parser')
items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
print(items) #打印item
#结果:<div>大家好,我是一个块</div>, <div>我也是一个块</div>, <div>我还是一个块</div>]
注意:
find() 或 find_all() 括号中的参数:标签和属性可以任选其⼀,也可以两个⼀起使⽤,这取决于我们要在网页中提取的内容。
中括号里的class_,这⾥有⼀个下划线,是为了和python语法中的类 class区分,避免
程序冲突。当然,除了⽤class属性去匹配,还可以使⽤其它属性,比如style属性等;
只用其中⼀个参数就可以准确定位的话,就只⽤⼀个参数检索。如果需要标签和属性同
时满足的情况下才能准确定位到我们想找的内容,那就两个参数⼀起使用;
# 调用requests库
import requests
# 调用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 返回一个Response对象,赋值给res
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 把Response对象的内容以字符串的形式返回
html = res.text
# 把网页解析为BeautifulSoup对象
soup = BeautifulSoup( html,'html.parser')
# 通过匹配标签和属性提取我们想要的数据
items = soup.find_all(class_='books')
print(items) # 打印items
二.
简析对象
2.1
Tag 对象
Tag 对象的三种常用属性和方法:

import requests # 调用requests库
from bs4 import BeautifulSoup # 调用BeautifulSoup库
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
res =requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 返回一个response对象,赋值给res
html=res.text
# 把res解析为字符串
soup = BeautifulSoup( html,'html.parser')
# 把网页解析为BeautifulSoup对象
items = soup.find_all(class_='books') # 通过匹配属性class='books'提取出我们想要的元素
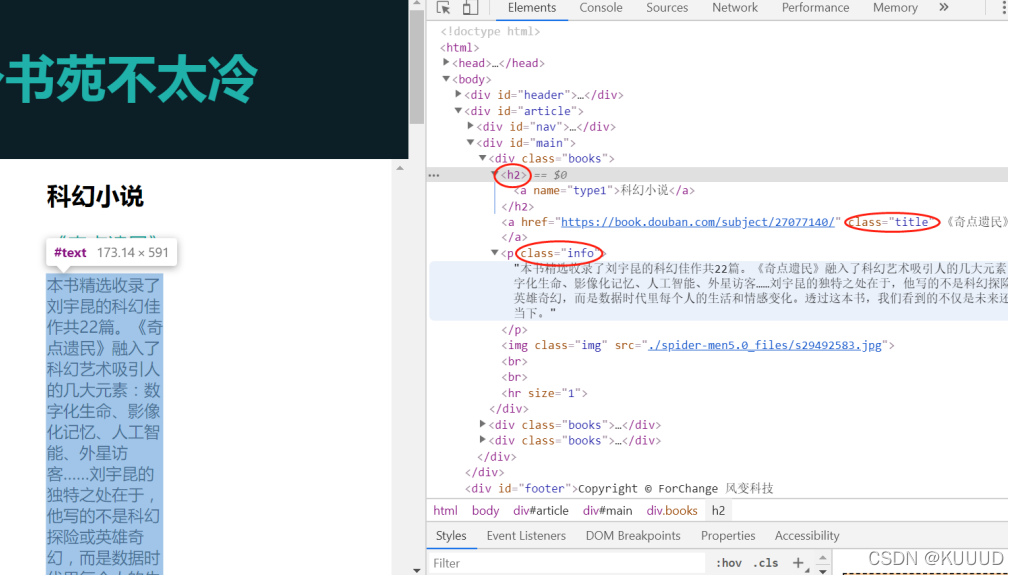
for item in items: # 遍历列表items
kind = item.find('h2') # 在列表中的每个元素里,匹配标签<h2>提取出数据
title = item.find(class_='title') # 在列表中的每个元素里,匹配属性class_='title'提取出数据
brief = item.find(class_='info') # 在列表中的每个元素里,匹配属性class_='info'提取出数据
print(kind.text,'\n',title.text,'\n',title['href'],'\n',brief.text) #打印书籍的类型、名字、链接和简介的文字
2.2
对象的变化过程
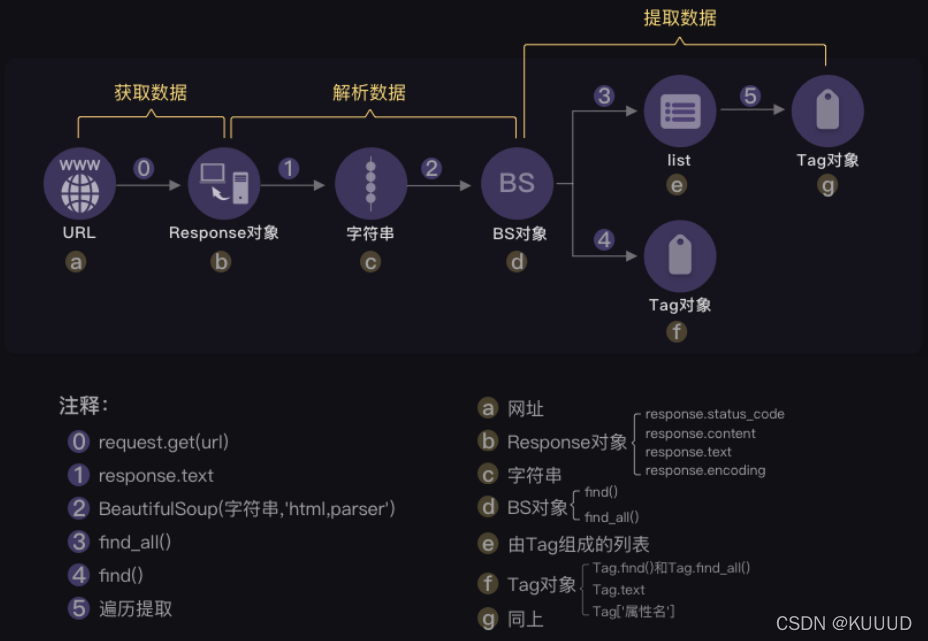
对象操作:Response对象——
字符串
——
BS对象
:
⼀条是
BS对象
——
Tag对象
;
另⼀条是
BS对象
——
列表
——
Tag对象;
三.
BeautifulSoup 实践
目标网站:
http://www.xiachufang.com/explore/
网站协议:
http://www.xiachufang.com/robots.txt (
目标网站 + robots.txt 可查看目标网站的页面爬取许可
)
;
项目目标:爬取热门菜谱清单,内含:菜名、原材料、详细烹饪流程的URL;
3.2
过程分析
1)
确定数据位置:
菜名、所需材料、和菜名所对应的详情⻚URL均在 html ⻚⾯上;
获取数据⽤ requests.get() ;
解析数据⽤ BeautifulSoup;

2)
提取数据:
windows:
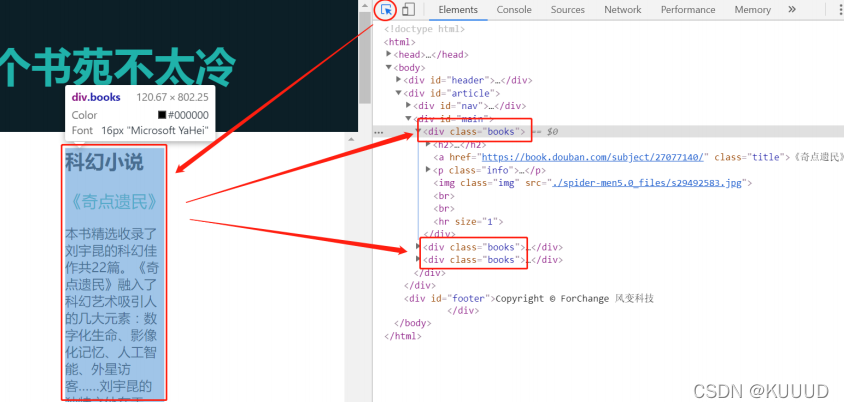
在网页的空白处点击右键,然后选择“检查”(快捷方式是ctrl+shift+i),再在 Elements 页⾯按 ctrl+f;
mac:
在网页的空白处点击右键,然后选择“检查”(快捷键 command + option + I(大写i));
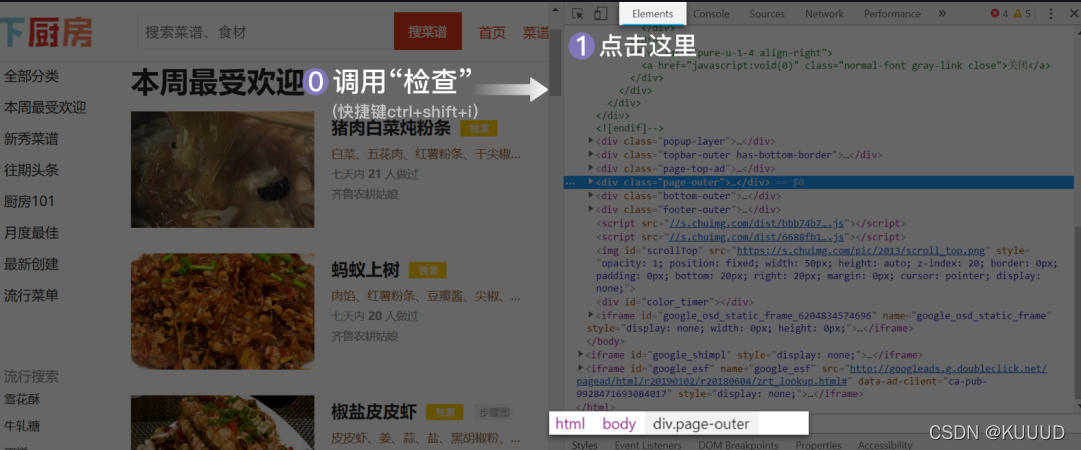
点击【检查】页面左上角的 “⿏标” 按钮,再点击后右侧想要获取的内容可以定位到该内容对应的标签;

四.
代码实现
4.1
数据获取
requests.get() 获取数据,BeautifulSoup 解析数据:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/', headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 打印解析结果
print(bs_foods)
4.2
提取最小父级标签
根据我们【过程分析】中所有菜谱的共同标签 class_=’info pure-u’,我们⽤ find_all 获取所有菜谱(find_all 获取后返回的是⼀个列表),下面我们提取出第0个⽗级标签中的第0个<a>标签,并输出菜名和URL:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 打印最小父级标签
print(list_foods)
1)
提取菜名:
依旧是根据我们的内容定位我们的标签,可以找到菜名是在我们的标签 a 中,再用text 取到该标签对应的菜名。
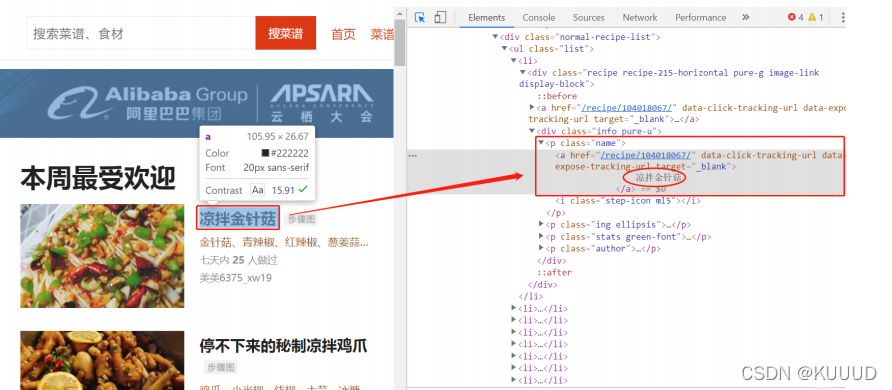
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 提取第0个父级标签中的<a>标签
tag_a = list_foods[0].find('a')
# 输出菜名,使用strip()去掉了多余的空格
print(tag_a.text.strip())
2)
提取 URL:
我们发现在标签 a 后⾯的 href 有我们需要的链接,但是不完整,所以需要拼接后才能得到我们要的菜谱 URL:
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 提取第0个父级标签中的<a>标签
tag_a = list_foods[0].find('a')
# 输出菜名,使用strip()去掉了多余的空格
print(tag_a.text.strip())
# 输出URL
print('http://www.xiachufang.com'+tag_a['href'])
3)
提取食材:
我们可以看到我们的⻝材是在 p 中,但是只靠这个是不够的的,所以我们要精确取值,
可以看到⻝材对应的 class 属性为
ing ellipsis:
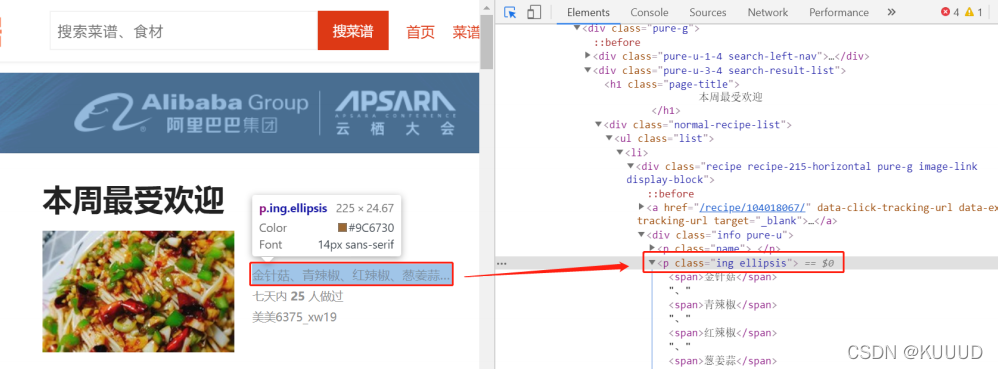
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 提取第0个父级标签中的<a>标签
tag_a = list_foods[0].find('a')
# 菜名,使用strip()函数去掉了多余的空格
name = tag_a.text.strip()
# 获取URL
URL = 'http://www.xiachufang.com'+tag_a['href']
# 提取第0个父级标签中的<p>标签
tag_p = list_foods[0].find('p',class_='ing ellipsis')
# 食材,使用strip()函数去掉了多余的空格
ingredients = tag_p.text.strip()
# 打印食材
print(ingredients)
4.3
写循环,存列表
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 创建一个空列表,用于存储信息
list_all = []
for food in list_foods:
tag_a = food.find('a')
# 菜名,使用strip()函数去掉多余的空格
name = tag_a.text.strip()
# 获取URL
URL = 'http://www.xiachufang.com'+tag_a['href']
tag_p = food.find('p',class_='ing ellipsis')
# 食材,使用strip()函数去掉多余的空格
ingredients = tag_p.text.strip()
# 将菜名、URL、食材,封装为列表,添加进list_all
list_all.append([name,URL,ingredients])
# 打印
print(list_all)
4.4 代码总结
# 引用requests库
import requests
# 引用BeautifulSoup库
from bs4 import BeautifulSoup
# 为躲避反爬机制,伪装成浏览器的请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
# 获取数据
res_foods = requests.get('http://www.xiachufang.com/explore/',headers=headers)
# 解析数据
bs_foods = BeautifulSoup(res_foods.text,'html.parser')
# 查找包含菜名和URL的<p>标签
tag_name = bs_foods.find_all('p',class_='name')
# 查找包含食材的<p>标签
tag_ingredients = bs_foods.find_all('p',class_='ing ellipsis')
# 创建一个空列表,用于存储信息
list_all = []
# 启动一个循环,次数等于菜名的数量
for x in range(len(tag_name)):
# 提取信息,封装为列表。
list_food = [tag_name[x].text.strip(),tag_name[x].find('a')['href'],tag_ingredients[x].text.strip()]
# 将信息添加进list_all
list_all.append(list_food)
# 打印
print(list_all)
# 以下是另外一种解法
# 查找最小父级标签
list_foods = bs_foods.find_all('div',class_='info pure-u')
# 创建一个空列表,用于存储信息
list_all = []
for food in list_foods:
tag_a = food.find('a')
# 菜名,使用strip()函数去掉了多余的空格
name = tag_a.text.strip()
# 获取URL
URL = 'http://www.xiachufang.com'+tag_a['href']
tag_p = food.find('p',class_='ing ellipsis')
# 食材,使用strip()函数去掉了多余的空格
ingredients = tag_p.text.strip()
# 将菜名、URL、食材,封装为列表,添加进list_all
list_all.append([name,URL,ingredients])
# 打印
print(list_all)
总结
程序员写代码并不是从0开始的,我们也是需要借助多个模板拼接,使得代码能够实现我们的想法,而且也并非默写出来,毕竟学习编程是开卷学习,开卷使用,本文的代码不一定一直具有有效性,毕竟爬虫与防爬也在一直进步,但本文爬虫的模板概念的介绍还是一直有效的,希望对你有帮助,加油,希望你我一同走进爬虫的世界~~
欢迎大家留言一起讨论问题~~~
注:本文是参考风变编程课程资料(已经授权)及部分百度资料整理所得,系博主个人整理知识的文章,如有侵权,请联系博主,感谢~
爬虫文章专栏