一、YARN概述
统一资源管理和调度平台(Yet Another Resource Negotiator)
:YARN脱胎于MRv1(MapReduce在Hadoop1.x中的实现),它由编程模型(新旧编程接口)、运行时环境(由JobTracker和TaskTracker组成)和数据处理引擎(MapTask和ReduceTask)三部分组成。MRv2是Hadoop2.X的MapReduce实现,运行时环境由YARN提供。MRv2的核心已经从单一的MapReduce计算框架转移为
资源管理系统YARN
,形成了以YARN为核心的统一框架管理体系;由ApplicationMaster负责MapReduce作业的数据切分、任务划分、资源申请和任务调度与容错等工作。
MRv2模型
YARN接管了所有的资源管理功能,兼容了异构的计算框架。MapReduce、Spark、MPI、Storm、Flink等都是不同的大数据计算框架。
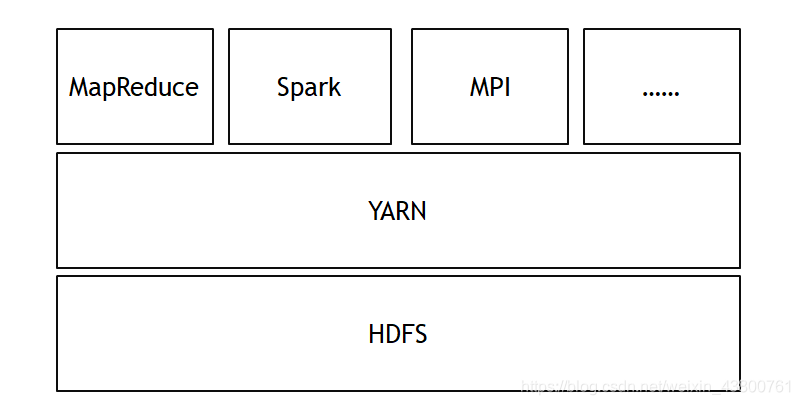
二、Hadoop资源调度
-
为什么要调度?
每个作业(计算任务)都需要CPU和内存资源才能运行,而这些资源散布在各个节点中,需要以某种规则将其分配给各个作业。 -
怎样调度?
资源调度的原则:
调度器
-
由谁执行调度?
一个节点执行调度可能忙不过来或不可靠(调度者故障),需要多个节点分工完成调度:
调度范式
2.1 最简单的资源调度模型
分配一个节点管理调度(谁调度:调度范式),作业进行排队,先申请资源的作业就先得,直到该作业完毕后释放资源(怎样调度:调度器)
符合人文精神,但效率不高
缺点1:
一个需要超大计算量、长时间执行但不算紧急的作业先申请,占用了系统绝大部分资源,其他紧急的小作业将得不到资源 (调度器缺陷)。
缺点2:
排队节点工作量巨大(接收入队申请、管理队列、分配资源、监测各工作节点状态、监测运行中的作业状况,回收已完成作业的资源……),导致系统效率降低(调度范式缺陷)。
缺点3:
排队节点故障会导致整个系统崩溃(调度范式缺陷)。
于是就出现了分布式资源调度
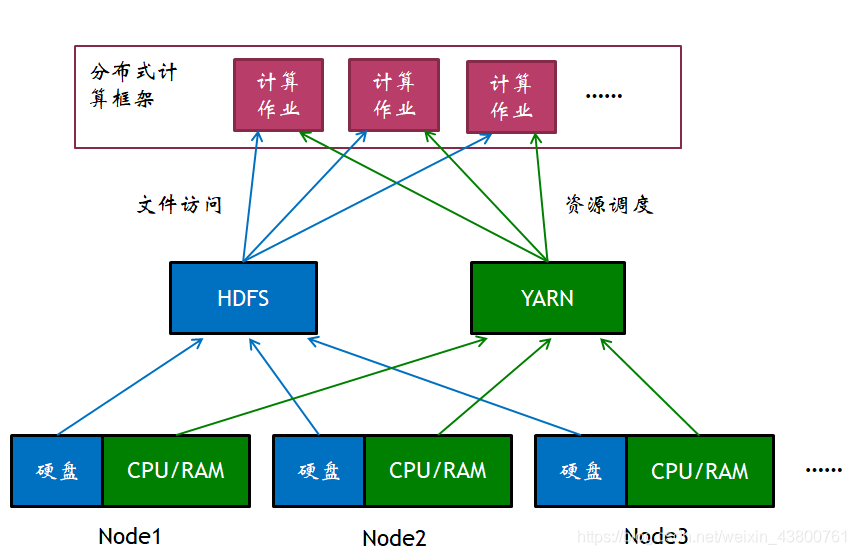
2.2 分布式资源调度
-
分布式资源调度特点
多Node协同工作完成一个大的计算作业,计算任务划分到节点Node中的资源容器(Container)动态的管理计算任务和集群资源。
需要多个Node协同完成上述管理任务:
调度范式
2.3 调度范式分类
Hadoop资源管理的运行机制分类:
-
集中式调度范式
全局只运行一个中央调度器,所有Node请求的资源都由该调度器实现,并发性能低、可靠性低。 -
双层调度范式
将调度分为中央调度(主调度/
一级调度
)器和框架调度(二级调度)器,中央调度器集中管理所有资源并粗粒度的分配给框架调度器,各框架调度器收到资源后,再做细粒度的资源分配,提升了并发性能。(
YARN的调度方式
)。 -
状态共享调度范式
在双层调度器的基础上弱化中央调度器,进一步提升并发性能。(理论阶段,尚不成熟)
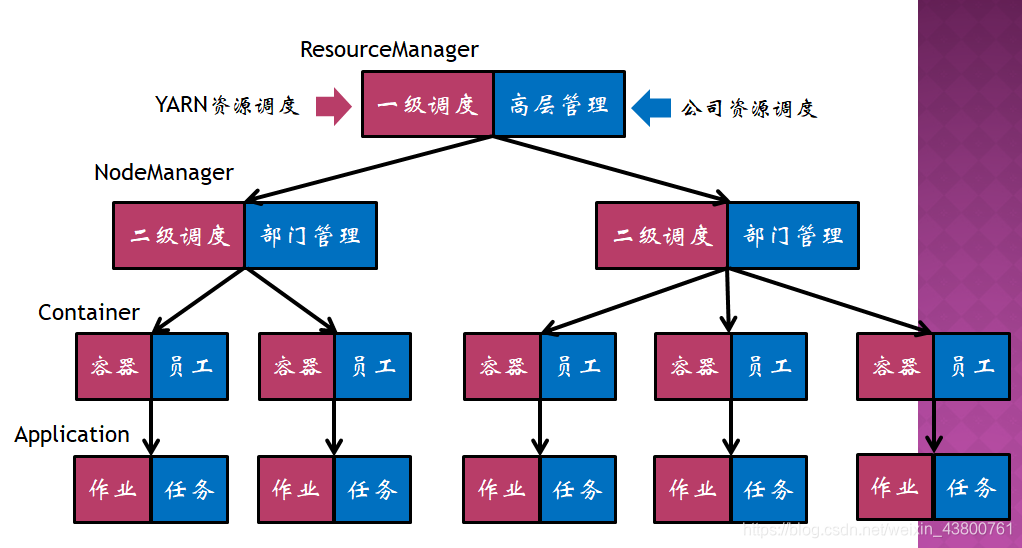
2.4 双层调度范式
计算资源的多层的资源调度模型,类似公司内部的资源调度,例如YARN资源调度:
- 高层管理类似于一级调度(ResourceManager)
- 部门经理类似于二级调度(NodeManager)
- 员工类似于容器(Container)
-
任务类似于作业(Application)
三、为什么要使用YARN
与旧MapReduce相比,YARN采用了一种分层的集群框架,具有以下几种优势。
-
Hadoop2.0提出了HDFSFederation;它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展。对于运行中
NameNode的单点故障
,通过 NameNode热备方案(
NameNode HA
)实现 。 -
YARN通过
将资源管理和应用程序管理两部分剥离开来
,分别由ResourceManager和ApplicationMaster进程来实现。其中,ResouceManager专管资源管理和调度,而ApplicationMaster则负责与具体应用程序相关的任务切分、任务调度和容错等。 -
YARN
具有向后兼容性
,用户在MR1上运行的作业,无需任何修改即可运行在YARN之上。 -
对于资源的表示以内存为单位(在目前版本的 Yarn 中没有考虑 CPU的占用),比之前以剩余 slot 数目为单位更合理。
-
支持多个框架,YARN不再是一个单纯的计算框架,而
是一个框架管理器
,用户可以将各种各样的计算框架移植到YARN之上,由YARN进行统一管理和资源分配,由于将现有框架移植到YARN之上需要一定的工作量,当前YARN仅可运行MapReduce这种离线计算框架。 -
框架升级容易,在YARN中,各种计算框架不再是作为一个服务部署到集群的各个节点上(比如MapReduce框架,不再需要部署JobTracker、 TaskTracker等服务),而是被封装成一个用户程序库(lib)存放在客户端,当需要对计算框架进行升级时,只需升级用户程序库即可,
四、YARN基本架构
-
YARN主从架构的构成
:-
Master —— ResourceManager
- 集群中各个节点的管理者
-
Slave —— NodeManager
- 集群中单个节点的代理
-
-
一级调度
- ResourceManager——接收作业,在指定NM(NodeManager)节点上启动AM(ApplicationMaster),在scheduler中执行调度算法为AM分配资源,管理各个AM。
-
二级调度
- ApplicationMaster——运行在NodeManager上,向RM请求资源,接收RM的资源分配,在NodeManager上启动Container,在Container中执行Application,并监控Application的执行状态。
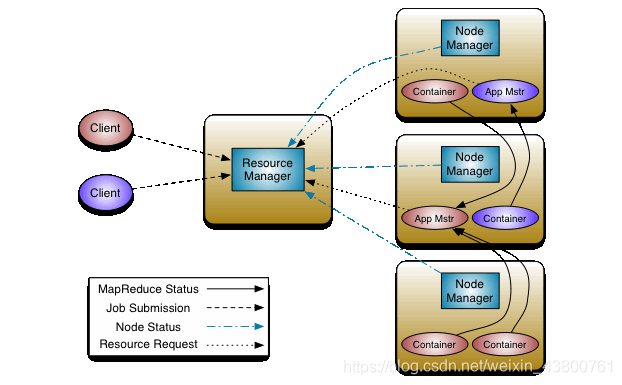
YARN重要组件如图所示:
-
Resource Manager
- 接收Client请求
- 执行一级调度scheduler
-
NodeManager
- 执行作业任务Job
- 执行二级调度ApplicationMaster
-
Container(容器)
- YARN的资源表示模型,CPU、内存、网络等资源分配给Container,由Container提供给其中的任务
-
Application和ApplicationMaster均需要计算资源,均运行在Container中
用户提交的Job以Application的方式得以执行
-
ApplicationManager
- 运行在ResourceManager中
- 管理YARN中所有的Application
-
ApplicationMaster
- 管理一个Application,运行在NodeManager的Container中
- 每个Application都一个ApplicationMaster负责管理
- 接收Container的进度汇报,为Container请求资源
-
通过心跳向ResourceManager汇报Application进度和资源状态
为什么主从之间通过心跳通信?如果不通过定时的心跳,那么我永远不知道是因为没有状况导致不通信还是因为故障导致没有通信。
-
作业(Job)
-
用户提交至YARN的一次计算任务,由client提交至ResourceManager
每个作业对应一个Application( MapReduce)
作业的每个工作流对应一个Application(Spark),效率更高
多用户共享一个长期Application(Apache Slider),系统响应更快
-
用户提交至YARN的一次计算任务,由client提交至ResourceManager
五、YARN工作流程
YARN的工作流程如下:
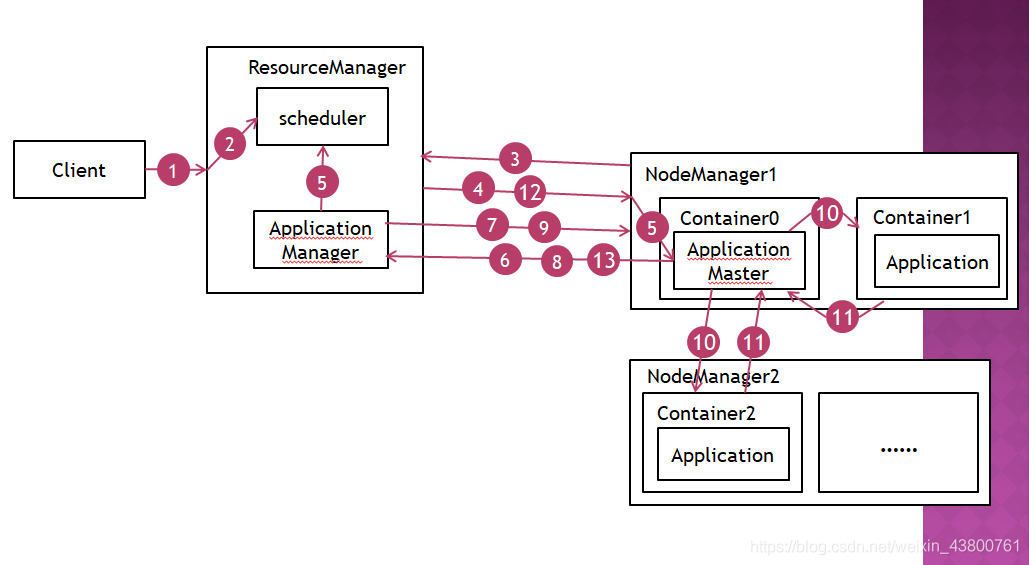
- Client向RM提交作业a(Job)
- RM在调度器(scheduler)中创建一个AppAttempt用以管理作业a的调度
- NM1向RM提交心跳,RM通过AManager将作业a的AMaster分配到NM1
- RM通过RPC调用NM1中的startContainer方法,在NM1中为作业a启动Container0(作业的0号容器)
- NM1在Container0中为作业a启动AMaster
- AMaster向AManager发起请求注册并初始化自身,计算自身所需资源,并向RM发起资源请求
- RM将AMaster的资源请求放入scheduler资源队列中,由scheduler分配资源,获得资源后向指定的NM分配相应的Container(资源以Container的形式分配),等下一次心跳
- AMaster向RM发送心跳
- RM返回AManager已分配好的Container
- AMaster向对应的NM发起RPC调用,启动已分配的Container
- Container启动后,用于执行用户的作业Application,并向AMaster汇报进度,AMaster负责整个Application中Container的生命周期管理
- AMaster为Container向RM请求资源
- 作业执行完毕,AMaster向RM申请注销资源
六、YARN调度器
-
YARN中的ResourceManager管理了集群中的资源,并使用双层调度范式,执行资源调度。
- RM作为一级调度,将资源分配给二级调度AM
-
RM通过Scheduler(调度器)执行一级调度
-
Scheduler支持三种调度器
- FIFO Scheduler (先进先出调度器)
- Capacity Scheduler (容器调度器)
- Fair Scheduler (公平调度器)
-
调度器通过分配不同大小的container实现资源调度
调度器 —> Container的分配信息 —> ApplicationMaster
—> 执行Container的创建 —> Application
-
Scheduler支持三种调度器
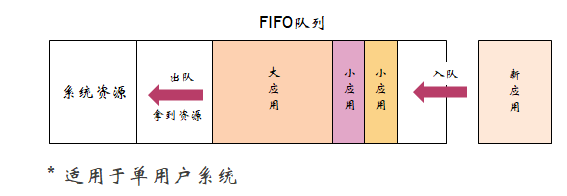
6.1 FIFO Scheduler (先进先出调度器)
- 按照作业的优先级高低和到达时间的先后顺序选择被执行的作业
-
不适合共享的集群,长时间执行的大应用优势太大,会长时间占用过多系统资源
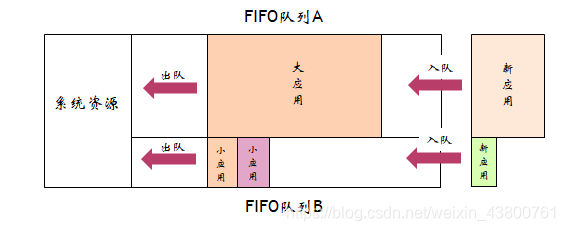
6.2 Capacity Scheduler (容器调度器)
- 将资源在逻辑上分为若干独立的子队列,任务被优先分配到空闲子队列中,队列内部采用FIFO原则排队。
-
保证了小应用的及时执行,降低了系统资源利用率
容器调度器特点
-
队列资源分配
每个队列预先配置资源量,出队的Application可以获得一定的资源量,可配置用户容量限制参数设定每个用户的Applications获得队列中的资源占比 -
入队操作
应用入队时,容器调度会找到资源利用率最少的队列执行入队操作 -
弹性队列
若队列在执行的过程中资源不够用时,可使用其他队列的空闲资源
若队列使用过多空闲资源,会导致其他队列资源被占用,正在使用的资源不能被抢占只能等待释放
可设置队列的资源上限,上限过高会导致其他队列资源被过多占用,上限太低会导致资源利用率低
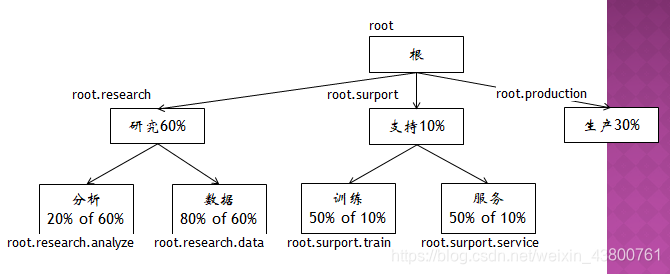
资源队列
- 资源队列以树的方式组织,配置队列容量/权限等,以树的方式执行配置
-
执行调度时,所有Application在叶子队列中完成排队和资源分配
例:公司YARN资源队列配置
6.3 Fair Scheduler (公平调度器)
-
公平调度器
与Capacity Scheduler类似,都是以队列按比例划分资源,在某个队列空闲时将资源共享给其他队列-
每个队列中有多种调度方式:FIFO、Fair或DRF
- Fair:公平调度,按内存资源需求占比执行调度
- DRF:主导资源公平,按主导资源(最大的需求资源[内存和CPU]类型)占比执行公平调度
如果一个队列占用过多资源,当其他队列需要时,可抢占这些被占用的资源
-
每个队列中有多种调度方式:FIFO、Fair或DRF
-
何谓公平?
保证各队列在执行任务时,保证能获得最小化的资源占比
兼顾了资源利用率和资源公平分配- 资源利用率:队列可使用空闲资源,避免资源浪费
- 公平分配:一旦有任务分配不到应得资源,可以抢占其他队列多占用的资源