之前的Spark总结,我提到了Spark的学习主要分为四个部分:
- 1.Spark Core用于离线计算;
- 2.Spark SQL用于交互式查询
- 3.Spark Streaming用于实时流式计算
-
4.Spark MLlib用于机器学习
这一篇博客我来讲讲Spark内部的运行过程剖析,比较偏理论 但是绝对值得你一看。
Spark中的专业术语
-
1.
Application
: 基于Spark的用户程序,包含了driver program和集群上多个executor
Spark中只要有一个sparkcontext就是一个application
;
启动一个spark-shell也是一个application,因为在启动spark-shell是就内置了一个sc(SparkContext的实例) -
2.
执行器(executor)
:在Worker Node上为某Application启动一个进程,该进程负责运行任务,并且负责将数据在硬盘或者内存中;每个Application都有各自独立的executors; -
3.
Driver Program
:Spark中的Driver即运行上述Application的main()函数并且创建 SparkContext,其中
创建SparkContext的目的是为了准备Spark应用程序的运行环境
。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Driver -
4.
Cluster Manager
: 在集群上获取资源的外部服务(例如standalone,Mesos,Yarn ) -
5.
Worker Node
集群中任何可以运⾏行应⽤用代码的节点 -
6.
Master
,是个进程,主要是负责资源的调度和分配,还有集群的监控等等职责。 -
7.
Worker
,同样是个进程,主要负责两个,一个是用自己的内存存储RDD的某个或者某些partition;另一个是启动其他线程或进程,对RDD上的partition进行处理和计算。 -
8.
Task
: 被送到某个executor上的工作单元 -
9.
Job
包含很多任务的并⾏行计算,Spark中的一个action对应一个job,如:collect, count, saveAsTextFile;
用户提交的Job会提交给DAGScheduler,Job会被分解成Stage(TaskSet) DAG;
RDD的transformation只会记录对元数据的操作(map/filter),而不会真正执行,只有action触发时才会执行job; -
10.
Stage
⼀个Job会被拆分很多组任务,每组任务被称为一个Stage,也可称为 TaskSet(就像Mapreduce分map任务和reduce任务⼀一样)
一个stage的边界往往是从某个地方取数据开始(如:sc.readTextFile),在shuffle时(如join,reduceByKey等)终止;
一个job的结束(如:count、saveAsTextFile等)往往也是一个stage的边界;
有两种类型的stage:ShuffleMapStage和ResultStage
-
11.
Task
被送到executor的工作单元;
在Spark中有两类Task:shuffleMap和ResultTask,第一类Task的输出时shuffle所需数据,第二类Task的输出时result;
Stage的划分也以此为依据,shuffle之前的所有变换是一个stage,shuffle之后的操作时另一个stage; -
12.
Partition
类似hadoop中的split,计算是以partittion为单位进行的。
备注:以上这些涉及到spark内部运行过程的专业词汇在初学者第一次接触时 可能不能完全明白理解 ,这是人之常情。通过后面长时间的学习,慢慢我们就会掌握理解。
相关概念的逻辑关系图:

Spark的基本运行流程(面试常考)
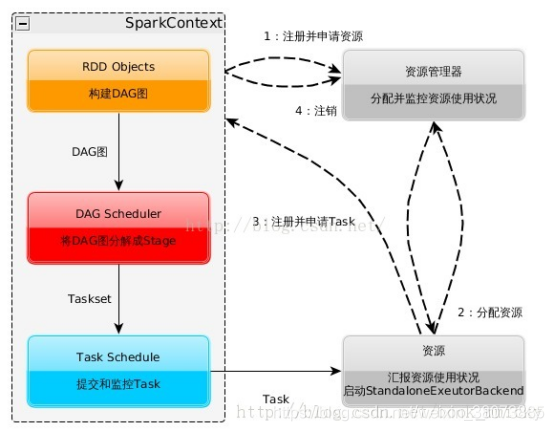
如上图所示,基本运行过程:
(1):构建Spark Application的运行环境,启动SparkContext
(2):SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend,Executor向SparkContext申请Task
(3):SparkContext将应用程序分发给Executor
(4):SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送给Executor运行
(5):Task在Executor上运行,运行完释放所有资源
Spark运行架构特点:
- 每个Application获取专属的executor进 程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种Application隔离机制有其优势的,无论是从调度角度看 (每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同的JVM中)。当然,这也意味着 Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
- Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
- 提 交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将 SparkContext提交给集群,不要远离Worker运行SparkContext。
- Task采用了数据本地性和推测执行的优化机制。
注意,所有的spark应用程序都离不开SparkContext和Executor两部分,Executor负责执行任务,运行Executor的机器成为work节点,SparkContext由用户启动,通过资源调度模块和Executor通信。SparkContext和Executor这两部分的核心代码是在在各种运行模式下都是公用的,在这之上,根据运行模式部署的不停,包装了不同调度模块以及相关的适配代码。
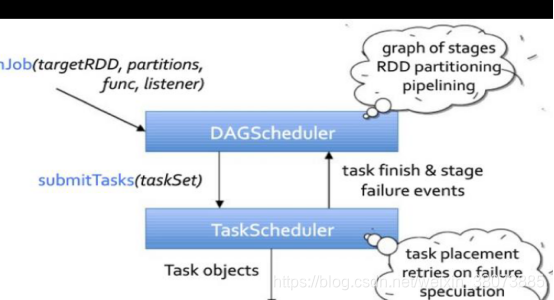
在SparkContext的初始化过程中,Spark会分别创建DAGScheduler作业调度和TaskSchduler任务调度两级调度模块。
DAG Scheduler
DAG Scheduler把一个Spark作业转换成Stage的DAG(Directed Acyclic Graph有向无环图),根据RDD和Stage之间的关系找出开销最小的调度方法,然后把Stage以TaskSet的形式提交给TaskScheduler。具体过程如下:
- 基于Stage构建DAG,决定每个任务的最佳位置
- 记录哪个RDD或者Stage输出被物化
- 将taskset传给底层调度器TaskScheduler
- 重新提交shuffle输出丢失的stage
Task Scheduler
DAG Scheduler决定了Task的理想位置,并把这些信息传递给下层的Task Scheduler。此外,DAG Scheduler还处理由于Shuffle数据丢失导致的失败,还有可能需要重新提交运行之前的Stage(非Shuffle数据丢失导致的Task失败由Task Scheduler处理)
Task Scheduler维护所有TaskSet,当Executor向Driver发生心跳时,Task Scheduler会根据资源剩余情况分配相应的Task。另外Task Scheduler还维护着所有Task的运行标签,重试失败的Task。
具体过程如下:
- 提交taskset(一组task)到集群运⾏行并汇报结果
- 出现shuffle输出lost要报告fetch failed错误
- 碰到straggle任务需要放到别的节点上重试
- 为每⼀个TaskSet维护⼀一个TaskSetManager(追踪本地性及错误信息)
在不同运行模式中任务调度器具体为:
- Spark on Standalone模式为TaskScheduler;
- YARN-Client模式为YarnClientClusterScheduler
-
YARN-Cluster模式为YarnClusterScheduler
相关基础类
(2020.2.6更新)
TaskScheduler/SchedulerBackend




还记得我们在上一篇博客
Spark02
提到的RDD吗?RDD是Spark编程的基础。在那篇博客中,我们主要讲到的是RDD的基础知识。
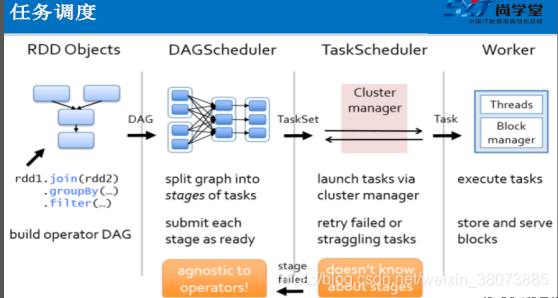
RDD在Spark中运行,主要分为一下三步:
- 1.创建RDD对象
- 2.DAGscheduler模块介入运算,计算RDD之间的依赖关系,RDD之间的依赖关系就形成了DAG
- 3.每一Job被划分为多个Stage。划分Stage的一个主要依据是当前计算因子的输入是否确定,如果是将其分在同一个Stage,避免多个Stage之间的消息传递开销
调度器根据RDD的结构信息为每个动作确定有效的执行计划。调度器的接口是runJob函数,参数为RDD及其分区集,和一个RDD分区上的函数。该接口足以表示Spark中的所有动作(即count、collect、save等)。
调度器根据目标RDD的血统关系(Lineage)创建一个由stage构成的有向无环图(DAG)。每个stage内部尽可能多地包含一组具有窄依赖关系的转换,并将它们流水线并行化(pipeline)。stage的边界有两种情况:一是宽依赖上的Shuffle操作;二是已缓存分区,它可以缩短父RDD的计算过程。
以下面一个按 A-Z 首字母分类,查找相同首字母下不同姓名总个数的例子来看一下 RDD 是如何运行起来的。

步骤 1 :
创建 RDD
。上面的例子除去最后一个 collect 是个动作不会创建 RDD 之外,前面四个转换都会创建出新的 RDD 。因此第一步就是创建好所有 RDD( 内部的五项信息 ) 。
步骤 2 :
创建执行计划
。 Spark 会尽可能地管道化,并基于是否要重新组织数据来划分 阶段 (stage) ,例如本例中的 groupBy() 转换就会将整个执行计划划分成两阶段执行。最终会产生一个 DAG(directed acyclic graph ,有向无环图 ) 作为逻辑执行计划。

步骤 3 :
调度任务
。将各阶段划分成不同的任务 (task) ,每个任务都是数据和计算的合体。在进行下一阶段前,当前阶段的所有任务都要执行完成。因为下一阶段的第一个转换一定是重新组织数据的,所以必须等当前阶段所有结果数据都计算出来了才能继续。
假设本例中的 hdfs://names 下有四个文件块,那么 HadoopRDD 中 partitions 就会有四个分区对应这四个块数据,同时 preferedLocations 会指明这四个块的最佳位置。现在,就可以创建出四个任务,并调度到合适的集群结点上。

何为Lineage(血统关系)?
利用内存加快数据加载,在众多的其它的In-Memory类数据库或Cache类系统中也有实现,Spark的主要区别在于它处理分布式运算环境下的数据容错性(节点实效/数据丢失)问题时采用的方案。
为了保证RDD中数据的鲁棒性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的
。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
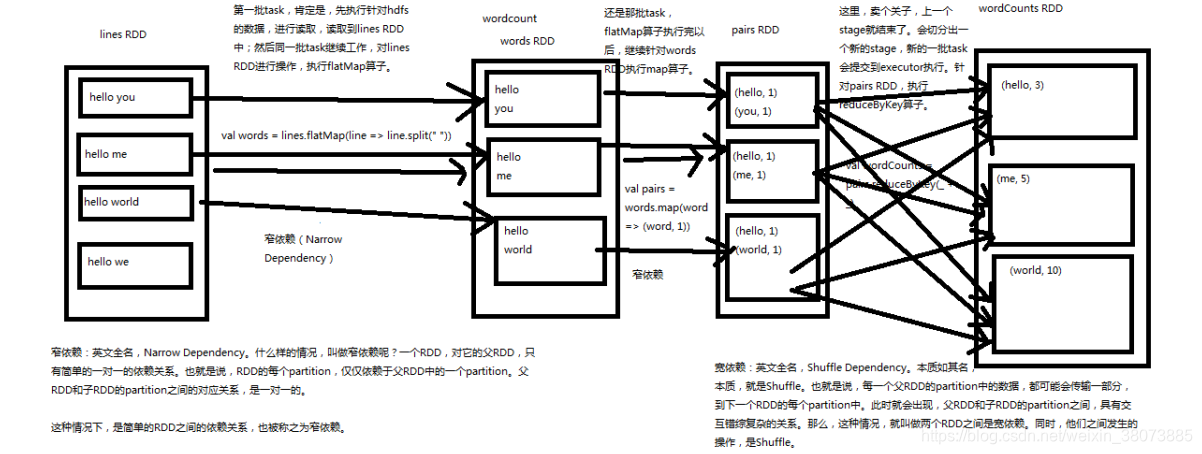
RDD在Lineage依赖方面分为两种==窄依赖(Narrow Dependencies)
与
宽依赖(Wide Dependencies)==用来解决数据容错的高效性。
宽依赖和窄依赖
窄依赖(Narrow Dependencies)是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。宽依赖(Wide Dependencies)是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。
对于Wide Dependencies,这种计算的输入和输出在不同的节点上,lineage方法对与输入节点完好,而输出节点宕机时,通过重新计算,这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上其祖先追溯看是否可以重试(这就是lineage,血统的意思),Narrow Dependencies对于数据的重算开销要远小于Wide Dependencies的数据重算开销。
关于宽窄依赖的理解,这里我已wordCount举了例子:
这一篇关于spark的博客 偏理论基础,涉及到许多原理剖析的基础知识(DAG RDD的血缘关系 宽依赖和窄依赖等),但却是大数据相关岗位经常会遇到的面试高频问题。说实话,南国前段时间面试cvte数据挖掘岗的时候,就被问到了spark运行的基本过程,但一时之间有点卡壳 只记得大概和一些名词 没有回答好。所以自己回顾之前的一些学习笔记和查找资料,总结出这篇。如有问题,还请多指教!
参考资料:
https://www.cnblogs.com/1130136248wlxk/articles/6289717.html