
【零】Go语言特点与输入输出
「特点」
1. 风格统一:同一件事只有一种实现方法,不同的人写出的代码风格应一致。例如:定义的变量必须要使用,if语句括号位置固定,只有for循环,fmt包能自动对齐代码
2. 易上手:简单易用是设计者的初衷
3. 编译型语言:直接编译成二进制码(Python等解释型语言编译成字节码后,需要通过解释器变成二进制码),因此更快
4. 从底层原生支持并发,从而能显著提高并发效率
5. 应用前景:目前字节跳动、b站、知乎均在较大规模的使用,腾讯新业务开始使用go
下载网址:https://golang.org/dl/
编辑器:
-
VSCode:https://code.visualstudio.com/Download
-
Goland:https://www.jetbrains.com/go/download

本人使用Goland,但VSCode更轻
「输入输出」
基于fmt包提供的接口来实现,使用方式同c语言的scanf和printf
-
常用占位符:
|
%d |
整型(十进制) |
%t |
布尔型 |
|
%f |
浮点型、复数 |
%T |
值的类型 |
|
%c |
字符型 |
%v |
结构体的值(%+v:字段名+值) |
|
%s |
字符串 |
%b |
整型(二进制) |
关于 %v 与 %+v的区别:
type Human struct { Name string}var people = Human{Name:"zhangsan"} fmt.Printf("%v", people) //输出 :zhangsanfmt.Printf("%+v", people) //输出 :name:zhangsan-
转义字符:以反斜杆 \ 起始,常用的有 \r 回车,\n换行
【一】数据类型与变量
数据类型
-
整型:按长度有int8、int16、int32、int64,数字代表其所占的位长度(如C++中的int是4个字节,对于此处即int32),对应的无符号整型:uint8、uint16、uint32、uint64。有时会简写为int/uint,此时32位操作系统上就是int32/uint32,64位操作系统上就是int64/uint64
-
浮点型:float32和float64
-
复数型:complex64和complex128,例如
var c1 complex64 = 1 + 2i-
布尔型:bool
-
字符:包含byte、rune两种
-
byte:代表了ASCII码的一个字符,大小为一个字节
-
rune:代表一个 UTF-8字符,如一个中文字符为多个字节,需要用rune类型,其大小为四个字节
-
-
字符串:string,底层为byte数组,不可修改
-
-
若修改:需要转换为切片byte[]或rune[],修改完成后转回string。如:
-
s := "big"// 强制转换S := []byte(s)S[0] = 'p'fmt.Println(string(S))
变量
-
变量声明
var 变量名 变量类型支持批量声明
var ( a string b int c bool d float32)-
变量初始化
未初始化的变量,均取对应数据类型的默认值,如整型,浮点型为0,字符串为空字符串“”,布尔型为false,切片、函数、指针变量默认为nil
var 变量名 类型 = 表达式如:
var name string = "xiaomin"var age int = 18Go支持类型推导,上述可简化为
var name = "xiaomin"var age = 18多个变量可一次性初始化:
var name, age = "xiaomin", 18在函数内部,可以使用短声明:
func(){ name, age := "xiaomin", 18}-
匿名变量:由于go支持一个表达式为多个变量同时赋值,如函数的返回值可以是多个。由于go中定义的变量必须要使用,当我们只需要使用部分返回值时,可以利用将不需要的值赋给匿名变量_。匿名变量不占用命名空间,不会分配内存,仅占位使用
func cpt() (x int, y int ) { return a+b, a-b}func main() { sum, _ := cpt() }【二】控制结构
分支结构
if 表达式1 { //这个括号必须放在if一行 分支1} else if 表达式2 { // else等必须在上个分支结尾括号一行 分支2} else{ 分支3}循环结构
for 初始语句;条件表达式;结束语句{ 循环体语句}另外有键值循环:
使用for range遍历数组、切片、字符串、map 及通道(channel)。通过for range遍历的返回值有以下规律:
-
数组、切片、字符串返回索引和值
-
map返回键和值
-
通道(channel)只返回通道内的值
例如:下面的代码为检查data中首个value为空的key
func check(data map[string]string) string { for k, v := range data { if v == "" { return k } } return nil}【三】线性数据结构
数 组
-
定义
var 数组变量名 [数组长度]数据类型-
初始化
var id [3]int //默认全零var name = [3]string{"a","b","c"} //定义同时初始化var score = [...]int{1,2,3} //自动推断长度weight = [...]int{1:150, 4:200} //对特定索引赋值,得到的数组为:[0,150,0,0,200]-
遍历:使用range能有效避免索引越界
Data := [...]int{1,2,3} for i:=0; i<len(Data); i++{ fmt.println(Data[i])}for i,v := range Data{ fmt.println(v)}-
二维数组:采用数组嵌套的定义方式
data := [3][2]string { {"a","b"}, {"c","d"}, {"e","f"},}for _,v1 := range data{ for _,v2 := range v1 { fmt.Printf("%s\t",v2) } fmt.Println()}切 片
-
本质
切片本质是对数组的引用,记录起始指针,len(元素个数)表示相对起始指针的偏移量,cap(容量)表示偏移量的上限值。这句话有如下内涵:
-
-
引用意味着切片并不复制元素,只记录起始指针+偏移量+最大偏移量
-
每个切片都有一个底层数组,它在初始化切片的时候创建。不同切片可能共用一个底层数组,对数组的修改,会同步到所有引用该数组的切片
-
-
定义方式
-
直接定义
-
var 切片名 []数据类型如:
var s1 = []int //定义一个切片,此时为nilvar s2 = []int{} //定义并初始化,此时虽没有元素,但不为nil,因为内存中已经创建一个对应的数组因此,不能根据是否等于nil来判断切片是否为空,应使用len查看当前元素长度是否为0
-
-
基于数组的定义
-
a := [8]int{0,1,2,3,4,5,6,7}b := a[1:7] fmt.Println(b)// 结果为 [1 2 3 4 5 6]即切取a数组下标 [1 , 7) 部分的元素【注意:左闭右开】,当索引边界未指定时,左边界默认为0,右边界默认为len(a)
-
-
切片的切片
-
a := [...]string{"甲", "乙", "丙", "丁", "春", "夏","秋","冬"}fmt.Printf("a:%v len:%d cap:%d\n", a, len(a), cap(a))b := a[1:3]fmt.Printf("b:%v len:%d cap:%d\n", b, len(b), cap(b))c := b[0:5]fmt.Printf("c:%v len:%d cap:%d\n", c, len(c), cap(c))输出为:
a:[甲 乙 丙 丁 春 夏 秋 冬] len:8 cap:8 b:[乙 丙] len:2 cap:7c:[乙 丙 丁 春 夏] len:5 cap:7原因:切片本质是对底层数组对引用,因此,切取 [L , R)范围内元素时,len = R-L,cap 取数组a[L]至其末尾的总个数。切片再切片时,c从b[1]对应的数组位置(这是切片b的唯一作用)开始切取len个元素,切到了b没有切到的元素。但要注意,索引不能超过原数组的长度,否则会因索引越界造成程序panic。
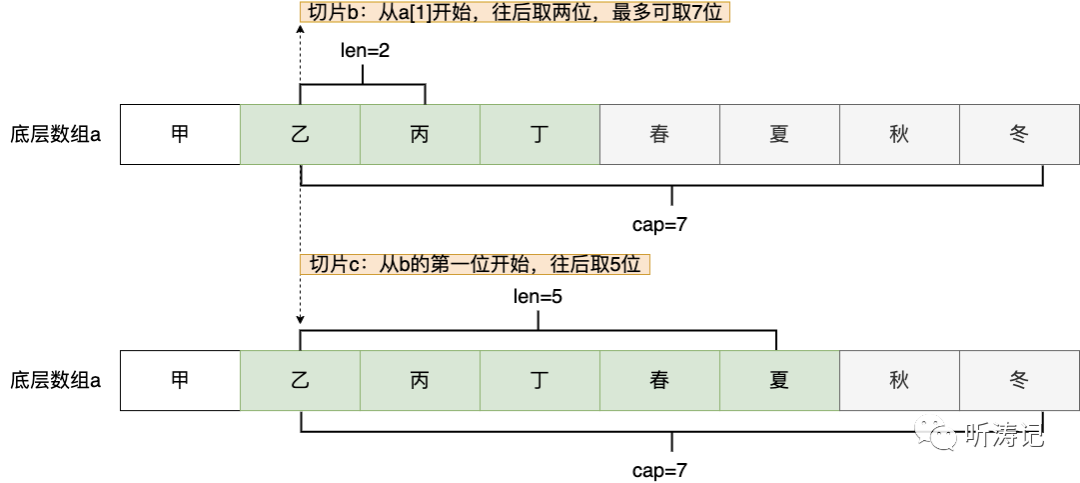
切片再切片的底层逻辑
-
-
make()函数定义
-
make([]数据类型, len, cap) -
追加:append()函数
新切片 = append(原切片,追加元素)追加的本质是,利用切片的指针信息计算出目标位置,然后将其赋值为追加的元素值。有三点要注意:
-
追加元素时,若目标位置没有超过数组范围,则会覆盖对应位置上原来的值
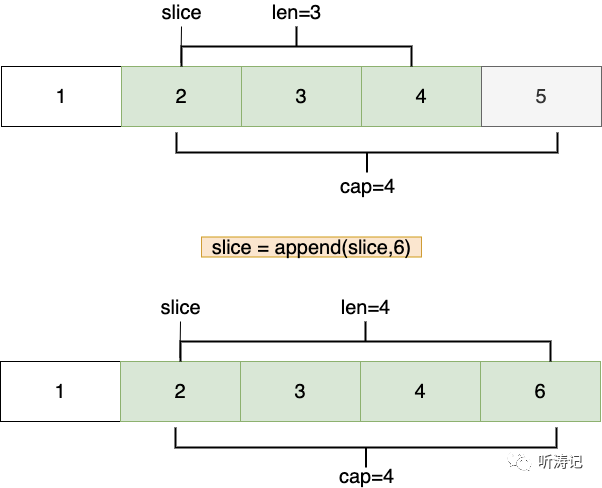
追加未超过原数组长度
-
追加元素时,若底层数组容量不够,数组将进行二倍扩容(当数组规模较大时,每次1.25扩容),注意是将cap*2,重新开辟一块数组,将原来无需改变的复制过来,将追加的元素放到后面
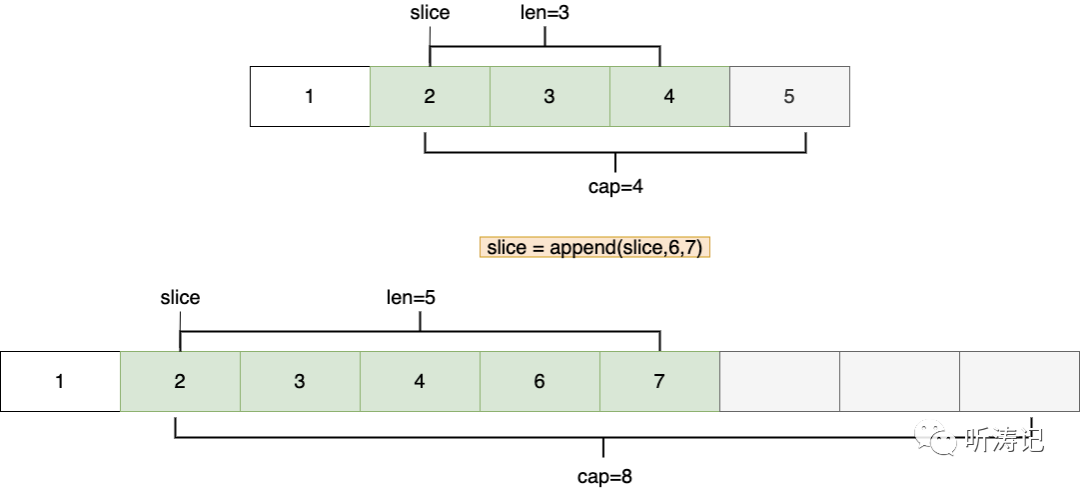
追加超过原数组长度
-
追加的元素可以是:一个,多个,切片
var citySlice []stringcitySlice = append(citySlice, "北京")// 追加一个元素citySlice = append(citySlice, "上海", "广州", "深圳")// 追加多个元素a := []string{"成都", "重庆"} // 追加切片citySlice = append(citySlice, a...)fmt.Println(citySlice) //[北京 上海 广州 深圳 成都 重庆]-
复制:copy()函数
由于切片为引用,共用同一个底层数组会互相影响。可以使用copy函数,将在内存中复制一个相同的数组,从而避免互相影响
copy(新切片, 原切片)
未完待续…
如有帮助,请点在看!
往期文章:
【字节跳动】日常/暑期实习招人啦(可转正)
情人节,用代码比个心
2019年offer待遇信息汇总——互联网篇
我的互联网转行之路

欢迎关注听涛记