消息队列
一、模式
1.Peer-to-Peer模式 点对点
a.往往消费者是串行消费的
b.数据往往只能被消费一次
c.角解耦能力相对较弱
2.发布/订阅模式
a.允许消费者进行并行消费
b.往往会提供数据的持久化机制,从而保证数据可以被消费多次
c.解耦能力更强
二、消息队列的优势
1.实现生产者和消费者的解耦
2.可以保证数据的可靠性
3.实现消峰限流
Kafka
简介
一、概述
1.Kafka是由LinkedIn(领英)开发的消息发布系统,后来贡献给了apache
2. Kafka是发布订阅模式的消息队列
3. Kafka的特征
a.以流式的方式来发布和订阅消息
b.提供了容错机制来存储流式数据
c.在流式数据出现的时候能够实时处理
kafka地址
https://kafka.apache.org/
4.应用场景:
a.能够在系统或者应用之间构建一个可靠的实时流传输管道
b.能够构建一个用于流式数据的传输和转化的实时流应用
5.实际开发中,KafKa节点个数一般是3-5个。Kafka之所以能实现大量数据的传输,是因为底层才用了Scala语言开发,并且引入了零拷贝技术(省去状态转化)
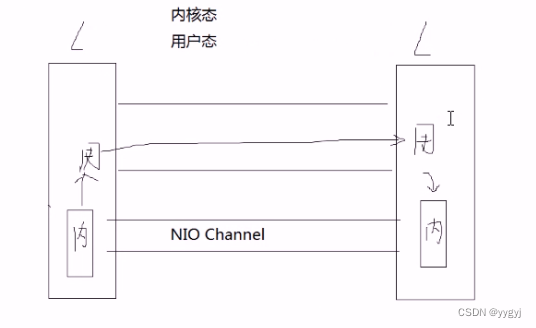
二、基本概念
1.Producer:生产者。产生数据放入Kafka
2. Consumer:消费者。从Kafka中拿取数据
3. broker:经纪人。在Kafka集群中,每一个Kafka节点都称之为是一个broker
4. topic:主题/话题。
a.在Kafka中,要求每一条数据必须放在某个主题中
b.主题在Kafka中的作用是用于进行数据的分类
c.所谓的主题可以认为是在Kafka中维系了一个子队列
d.每一个主题可以对应1个到多个分区
e.主题在执行删除明林之后,不会立即删除而是被标记为删除状态,等3os才会被删除。需要需要立即删除,那么修改server.properties中的delete.topic.enable,将这一项的值改为true
5.partition:分区
a.为了做到数据的分布式存储,设计了分区
b.如果设置了多个分区,那么每一个分区都会对应一个目录
c.实际过程中,如果配置了多个Kafka节点,那么分区会平均分配到每一个节点上
6.replication:副本
对数据进行备份,保证数据不会丢失
7. leader和follower:
a. Kafka中leader和follower指的并不是节点,而是副本
b.在Kafka中可以设置多个副本,当出现多个副本的时候,这些副本之间会选择一个副本成为leader副本,其他副本成为follower副本
c. producer和consumer在和Kafka进行交互的时候,只和leader副本来交换数据
d. leader副本和follower来进行实时的更新,并且更新之后,follower副本会给leader副本返回ack信号。同时leader副本还会保存一个返回信号的节点队列。这个队列准确的说是维系在了Zookeeper节点/isr_change_notification上。如果leader副本挂掉,那么优先从队列中来选leader,这个过程称之为ISR
e.只要有副本存活,那么Kafka就可以继续对外服务
f.如果所有副本都挂掉,那么先复活的副本就会成为leader
8. controller:控制器。监控leader副本的状态。如果leader副本挂掉,那么controller负责选择一个新的leader副本
9. Consumer Group:消费者组。将一个或者多个消费者绑定在一块形成一个消费者组。消息在组间基享(即不同的消费者组可以获取相同的消息)在组内竞争(即消息只能被这个消费者组中的某一个消费者消费不能被这个组内的多个消费者进行消费
三、基本细节
1.数据放入Kafka中之后,即使被多次消费,也不会从队列中移除2. Kafka会将数据以日志形式记录到本地磁盘上
3.数据清理条件:
a.默认情况下,每隔7天清理一次
b.如果单个日志文件达到1G的时候,也会清理一次
4. leader和follower之间进行备份的时候,是follower主动到leader来拉取数据
5. offset机制:
a.偏移量的作用是用于记录消费者组上一次的消费位置防止数据的重复消费
b. Kafka在启动之后,会在log.dirs目录下自动生成50个子目录用于存储消费者组的偏移量
6.索引机制:
a.在分区目录下会存在index文件和log文件。每一个log文件都会对应一个index文件。一个log+一个index=一个segment
b.数据是记录到log文件中,index是针对log的索引
c.在Kafka中,建立的是稀疏索引-并不是针对每条数据都建立索引而是隔几条建立一个索引
d.在读取索引文件的时候,也不是从头读取,而是才用了二分查找
e. 当log文件达到1G的时候,会自动生成一个新的log文件,同时生成一个新的index文件。如果生成了新的log文件和index文件,则文件名是这个log文件所记录第几个数据(起始下标)
f. leader-epoch-checkpoint:记录follower从leader中拿取的数据的个数
00000000000000000001.index:初始容量10M
leader-epoch-checkpoint:检查点记录
语义
1.至少一次(悲观)

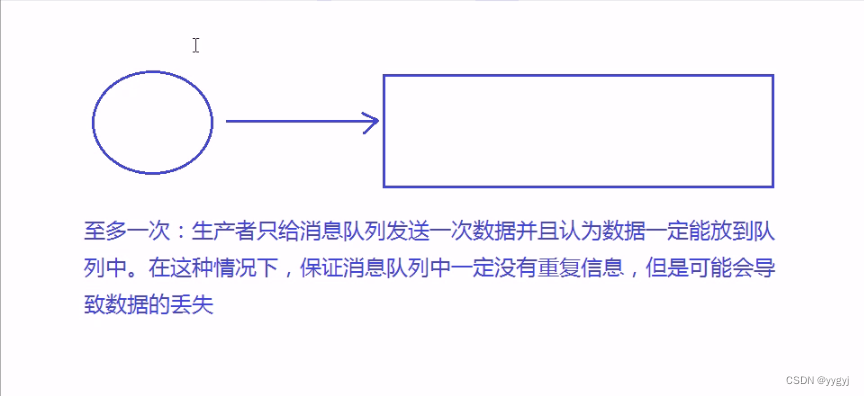
2.至多一次(乐观)
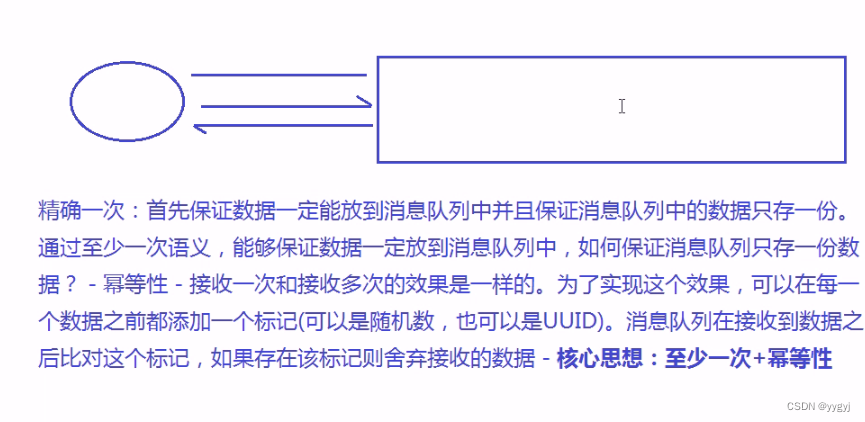
3.精确一次
消息队列push到消费者———至多一次
消费者pull到消息队列———三种语义
四、CAP
1.Consistency:一致性。保证所有节点的数据是相同的
Available:可用性。在有有效节点的情况下,能够准确的返回请求消息
Partition Tolerance:分区容忍性。部分节点宕机,其余的模块是不受影响
2.在分布式中,CAP三大原则只能满足其中2个,分布式中通常满足的是CP【zk、kafka】或者AP【cassandra】,绝大部分是cp原则
3.一致性满足方式:
a. M/S结构
b. Paxos算法及其变种: Zookeeper
c. WNR:在WNR中,规定只有当W+R>N的时候,满足一致性。w表示写入的节点个数,R表示读取的节点个数,N表示总节点个数。例如:某个集群中总节点个数为9个,在写入的时候,向其中的3个节点写入了数据,那么在读取的时候,根据W+R>N的原则,要求至少读取7个节点,3+7>9,之所以这样规定,是保证每次读取一定能够读取到最新写入的数据
常用命令
kafka的安装启动
1.上传或者下载安装包
2.解压安装包: tar -xvf kafka_2.11-1.0.0.tgz
3.进入安装目录的子目录config下 : cd kafka_2.11-1.0.0/config/
4.编辑server.properties : vim server.properties
5.添加如下内容:
#给每—个Kafka节点配置编号
broker.id=0
#消息的存储陌路
log.dirs=/home/software/kafka_2.11-1.0.0/kafka-logs# Zookeeper的连接地址
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
5.保存退出后
6.配置其他两台虚拟机,更改配置文件的broker.id编号(不重复即可)
7.启动zookeeper集群
8.进入Kafka安装目录的bin目录下
9.启动Kafaka,执行:
[root@hadoop01 bin]# sh kafka-server-start.sh ../config/server.properties
zk注册信息展示
[root@hadoop01 bin]# sh zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[cluster, controller, brokers, zookeeper, log, yarn-leader-election, hadoop-ha, admin, isr_change_notification, log_dir_event_notification, controller_epoch, rmstore, consumers, latest_producer_id_block, config, hbase]
创建一个主题
[root@hadoop01 bin]# sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 1 --partitions 1 --topic log
Created topic "log".
效果
[2022-08-04 17:00:25,978] INFO [Partition log-0 broker=0] log-0 starts at Leader Epoch 0 from offset 0. Previous Leader Epoch was: -1 (kafka.cluster.Partition)
主题的分区创建
[root@hadoop01 bin]# sh kafka-topics.sh --create --zookeeper hadoop01:2181 --repication-factor 1 --partitions 2 --topic txt
主题的副本创建
[root@hadoop01 bin]# sh kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 2 --partitions 2 --topic class
效果节点1
[root@hadoop01 kafka-logs]# ls
class-0 music-1
class-1 news-0
cleaner-offset-checkpoint recovery-point-offset-checkpoint
log-0 replication-offset-checkpoint
log-start-offset-checkpoint txt-0
meta.properties video-0
music-0
效果节点2
[root@hadoop02 kafka-logs]# ls
class-0 meta.properties
class-1 recovery-point-offset-checkpoint
cleaner-offset-checkpoint replication-offset-checkpoint
log-start-offset-checkpoint txt-1
主题的删除
sh kafka-topics.sh --delete --zookeeper hadoop01:2181 --topic music
效果
[root@hadoop01 bin]# ls ../kafka-logs/
class-0
class-1
cleaner-offset-checkpoint
log-0
log-start-offset-checkpoint
meta.properties
music-0.444eb99b24fc464ea76fbbf4db95e436-delete
music-1.6c2664f254194e4183cf7d3359812cdd-delete
news-0
recovery-point-offset-checkpoint
replication-offset-checkpoint
txt-0
video-0
删除状态提示(有个删除的过程)
Topic music is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
可以更改这个提示(/config/server.properties)
Topic class is marked for deletion .
Note: This will have no impact if delete.topic.enable is not set to true.
查看主题
[root@hadoop01 bin]# sh kafka-topics.sh --list --zookeeper hadoop01:2181
class
log
news
txt
video
启动生产者(hadoop01)
[root@hadoop01 bin]# sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic txt
>hello
>
启动消费者(hadoop01)
[root@hadoop01 bin]# sh kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic txt
效果(hadoop01消费者)
[root@hadoop01 bin]# sh kafka-console-consumer.sh --zookeeper hadoop01:2181 --topic txt
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
hello
Kafka ha(高可用)
Kafka API操作
Kafka offset机制(偏移量)
通过这一特性可以保证同一消费者从Kafka中不会重复消费数据
启动生产者(hadoop01)
[root@hadoop01 bin]# sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic txt
启动消费者(hadoop01)
[root@hadoop01 bin]# sh kafka-console-consumer.sh --bootstrap-server hadoop01:9092 --topic txt --from-beginning --new-consumer
定位消费组所在位置
[root@hadoop01 kafka-logs]# sh kafka-consumer-groups.sh --bootstrap-server hadoop01:9092 --list --new-consumer
console-consumer-51217
求哈希码值
Math.abs("console-consumer-51217".hashCode()) % 50
偏移量量对应的目录(启动一个Kafka目录集中到一个节点上,启动两个Kafka目录集中到两个节点–奇数偶数分布)
[root@hadoop01 kafka-logs]# ls
class-0 __consumer_offsets-34
class-1 __consumer_offsets-35
cleaner-offset-checkpoint __consumer_offsets-36
__consumer_offsets-0 __consumer_offsets-37
__consumer_offsets-1 __consumer_offsets-38
__consumer_offsets-10 __consumer_offsets-39
__consumer_offsets-11 __consumer_offsets-4
__consumer_offsets-12 __consumer_offsets-40
__consumer_offsets-13 __consumer_offsets-41
__consumer_offsets-14 __consumer_offsets-42
__consumer_offsets-15 __consumer_offsets-43
__consumer_offsets-16 __consumer_offsets-44
__consumer_offsets-17 __consumer_offsets-45
__consumer_offsets-18 __consumer_offsets-46
__consumer_offsets-19 __consumer_offsets-47
__consumer_offsets-2 __consumer_offsets-48
__consumer_offsets-20 __consumer_offsets-49
__consumer_offsets-21 __consumer_offsets-5
__consumer_offsets-22 __consumer_offsets-6
__consumer_offsets-23 __consumer_offsets-7
__consumer_offsets-24 __consumer_offsets-8
__consumer_offsets-25 __consumer_offsets-9
__consumer_offsets-26 log-0
__consumer_offsets-27 log-start-offset-checkpoint
__consumer_offsets-28 meta.properties
__consumer_offsets-29 music-0
__consumer_offsets-3 news-0
__consumer_offsets-30 recovery-point-offset-checkpoint
__consumer_offsets-31 replication-offset-checkpoint
__consumer_offsets-32 txt-0
__consumer_offsets-33 video-0
[root@hadoop01 kafka-logs]# pwd
/home/presoftware/kafka_2.11-1.0.0/kafka-logs