对于大数据来说,数仓的作用不言而喻,承载着整个公司全业务线的数据,现阶段,在hadoop上的数仓主要是用来解决企业内部数据的分析,尤其是各种各样的统计分析报表。本文主要结合自己公司目前数仓的结构设计和现阶段解决的问题而叙述和分享,如有不明,错误之处,各位看官可指出,非常感谢!
下图为数仓整体的技术架构:
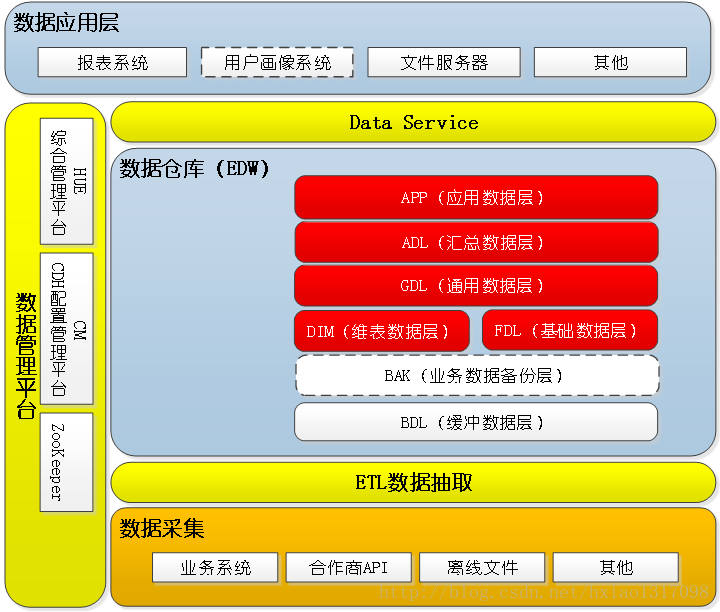
一个优秀可靠的数仓,一定要结构、分层清晰,而不是越多的分层和主题越好,保障清晰的状态下,能够快速找到数据的位置。主题域的划分,完全可按照公司内部的业务线和结构去划分。
图中BDL层,作为缓冲数据层,其实就是贴数据层,和源数据表相同的表。直接用源库(传统关系型业务库)抽取数据,只存每天最新的数据快照(主要是增量数据)
BAK层是BDL层抽数,保存的是全历史业务数据,起备份和查错的作用。
FDL层是基础数据层,是基于主题、数仓模型开发的基础数据表。这里主要用到了范式建模法和维度建模法(即星型模型)包含最细粒度的数据,故称基础数据层,通俗的理解,这才是整个数仓的最核心的基础数据层,因为BAK层和BDL层的数据表结构跟业务库的数据是完全一致的,而FDL层的数据才是开始进行真正意义上的第一次清洗,不要的字段去除,不规范的字段命名去除,统一数据,规范标准化的一个过程。
GDL层是通用数据层,就是宽表层。也是基于主题、数仓模型开发的宽表。可能会牺牲第三范式,将相关的各维度或属性整合到一张表里。这种表的特点就是字段较多,数据量较大,但它能帮助消除重复查询。由于这种表会被各种需求用到,故称通用数据层。
ADL层是汇总数据层,是基于主题、数仓模型开发的汇总数据表。这里只用到维度建模法(即星型模型)。指标库可以放到这一层。
APP层是开放给用户,用户可以在此层自己开发数据,提数。给用户的脱敏数据也可以放到这一层。我们开发的数据产品所需数据也可以在这一层做。
还有两层比较特殊:
一个是TMP(临时层),说白了就是存储中间结果表,有些业务场景比较复杂,需要拆表,多次计算,要用到一些中间结果集表,因此这层也是辅助层。
DIM层是维表层,各种时间维,省市区维度都可以存放,根据公司的业务形态去划分,ADL层可以跟DIM层的多维度关联,做各种报表,手到擒来。
以下是数据仓库数据流架构图:
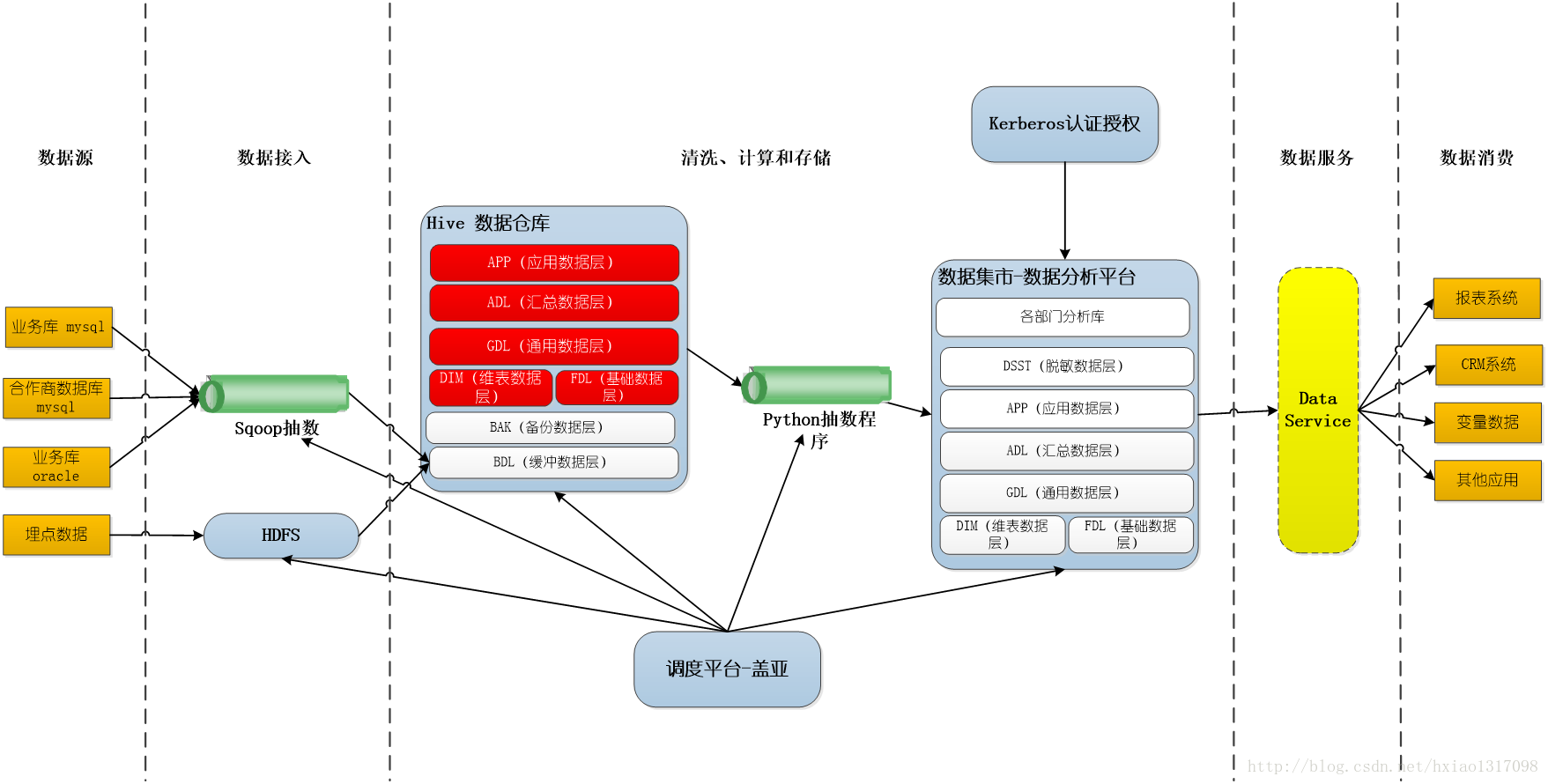
以上就是整个数仓平台的大概架构思路,其实大部分公司的数仓都是差不多的,无非是各个层的划分的区别,层的多少区别,我是这么理解的。如果有更新意的分层、数仓设计,欢迎大家交流,一起探讨,接下来的几章,我会大概叙述数仓的标准化的建设,如何设计模型,如何编写清洗脚本,服务器目录如何标准化分目录等等,这些都很重要,流程的规范化,会给实际工作开发带来巨大的效率提升!