一、Spark 概述
Spark是一种
基于内存的
快速、通用、可扩展的大数据分析计算引擎
1. Spark与Hadoop
Spark的主要功能是用于
数据计算
,所以Spark一直被认为是 Hadoop 框架的升级版
Spark在传统 MapReduce 计算框架的基础上,利用其计算过程的优化,大大加快了数据分析、挖掘的运行和读写速度,并将计算单元缩小到更适合并行计算和重复使用的
RDD计算模型
Spark和Hadoop的根本差异是多个作业之间的数据通信问题:
Spark多个作业之间的数据通信是基于内存,而Hadoop是基于磁盘
在绝大多数计算场景中,Spark比MapRudecu更有优势,但Spark是基于内存的,所以在实际生产环境的部署中
对内存资源的要求更高
2. Spark核心模块
-
Spark Core
:提供Spark最核心最基础的功能 -
Spark SQL
:用来操作结构化数据 -
Spark Streaming
:针对实时数据进行流失计算 -
Spark MLlib
:机器学习算法库 -
Spark GraphX
:面向图计算的库
二、 WordCount
实现思路
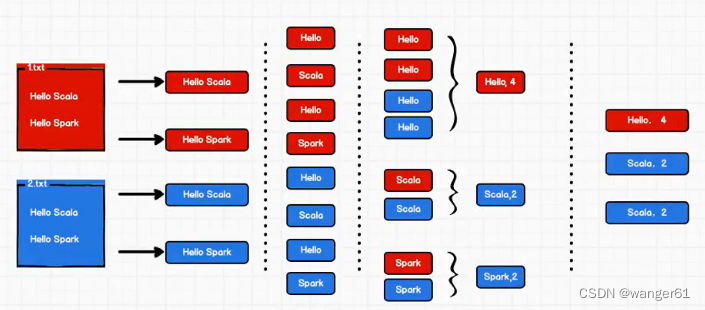
实现代码
// 建立和Spark框架的连接
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
// 1. 读取文件,逐行读取数据
val lines: RDD[String] = sc.textFile("1.txt")
// 2. 将每行数据拆分为一个个单词
val words: RDD[String] = lines.flatMap( .split(" "))
// 3. 单词进行转换 (hello,1)
val wordToOne = words.map{
word => (word, 1)
}
// 4.对相同的key的value作聚合,极简原则
val wordToCount = wordToOne.reduceByKey(_+_)
// 5. 转换结果采集到控制台打印
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(print)
// 关闭Spark连接
sc.stop()
三、Spark核心组件
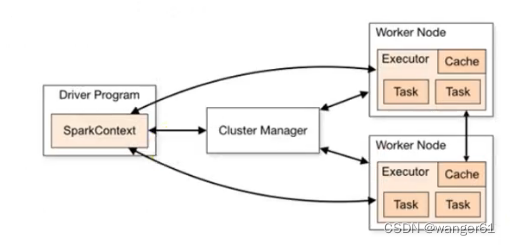
1. 计算组件
Spark采用了master-slave结构
Driver
为master,
负责管理整个集群中的作业调度
:
- 将用户程序转换为job
- 在Executor之间调度任务task
- 跟踪Executor的执行情况
Executor
为slave,
负责实际执行任务
:
- Executors是运行在工作节点(Worker)中的一个JVM进程,是集群中专门用于计算的节点。
-
在提交应用中,可以通过参数指定计算节点的个数和使用的资源(
内存大小和CPU核数
) - 可以通过自身的块管理器为RDD提供缓存,使任务在运行时充分利用缓存数据加速运算
2. 资源组件
Master
:
负责资源的调度和分
配,并进行集群的监控
Worker
:由Master分配资源对数据进行处理和计算
ApplicationMaster
:Driver通过ApplicationMaster向Master申请资源,实现
计算和资源的解耦