1.简介
Hive是基于Hadoop的一个开源数据仓库工具,将海量结构化数据文件映射为一张表,并在其上提供类SQL(HQL)查询功能。Hive本质是将HQL转化成MapReduce,以处理存储在HDFS上的数据。
优点
- 避免写MapReduce,减少学习成本。提供HQL操作接口,易上手。
- 适合处理大数据,处理小数据意义不大。
- 支持自定义函数处理数据。
缺点
- HQL表达能力有限。
- 执行效率低。基于MapReduce,天然延迟高。
- 不支持修改,一次写入多次读取。
- 不支持事务。
2.架构
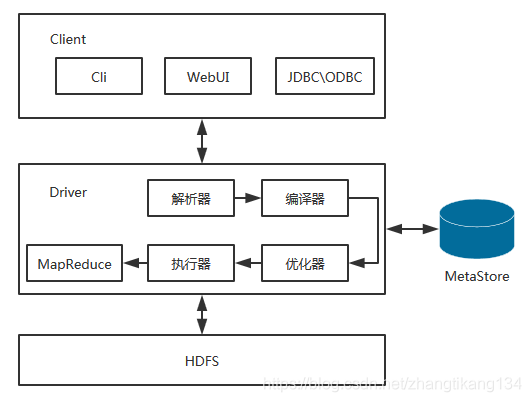
Client 客户端
- Cli(command-line interface)
- JDBC/ODBC
- WebUI
Metastore 元数据
元数据:包括表名、表所属的数据库、表的拥有者、列/分区字段、表类型、表数据所在路径等
版权声明:本文为zhangtikang134原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。