层次遍历避免使用了递归方法,所以整个代码就会显得略长。
首先是二叉树的链式存储的类型说明:
#include<stdio.h>
#define MaxSize 100
typedef char ElemType;
typedef struct tnode
{
ElemType data;
struct tnode *lchild,*rchild;
}BTNode;重点看后面的遍历方法,我也是看了很久才明白。
定义函数,形参为这个二叉树,由于这项功能不用后续调用该二叉树所以不用&引用型。
这里面定义一个结构体,设置一个非循环队列qu,其中两个域:s为二叉树中的结点指针,parent存放该结点的双亲在qu中的下标,这也是这个定义的精妙之处,为了方便找到每个结点它的双亲。
P作为在二叉树中移动指向的指针,i为记录双亲结点在qu中的下标即qu[].parent。
void ancestor(BTNode *bt)
{
BTNode *p;
int i;
struct
{
BTNdoe *s;
int parent;
}qu[MaxSize];用一个队列描述整个指针的走势情况。先进队首结点,由于首结点没有双亲所以让它的parent为-1。(这也为后面输出双亲的判断条件埋下了伏笔)
int front=-1,rear=-1;
rear++;qu[rear].s=bt;
qu[rear].parent=-1;while循环若队不空,则先让首结点出队(第一次,后面出队的就是下一个进队的前驱),若满足叶子结点的条件(if语句),先把这个结点打印出来,接着打印他的各个祖先结点。这时候前面定义的i就派上用场了,先存这个叶子结点的前驱结点的parent,然后通过while,每次都让这个i存为前驱的前驱……,并且依次将各个qu[parent](或者说这里的qu[i])所对应s的data打印出来。直到i=-1。就说明已经访问到首结点了,结束循环。
while(front!=rear)
{
front++;
p=qu[front].s;
if(p->lchild==NULL && p->rchild==NULL)
{
printf(" %c的所有祖先结点:",p->data);
i=qu[front].parent;
while(i!=-1)
{
printf("%c",qu[i].s->data);
i=qu[i].parent;
}
printf("\n");
}
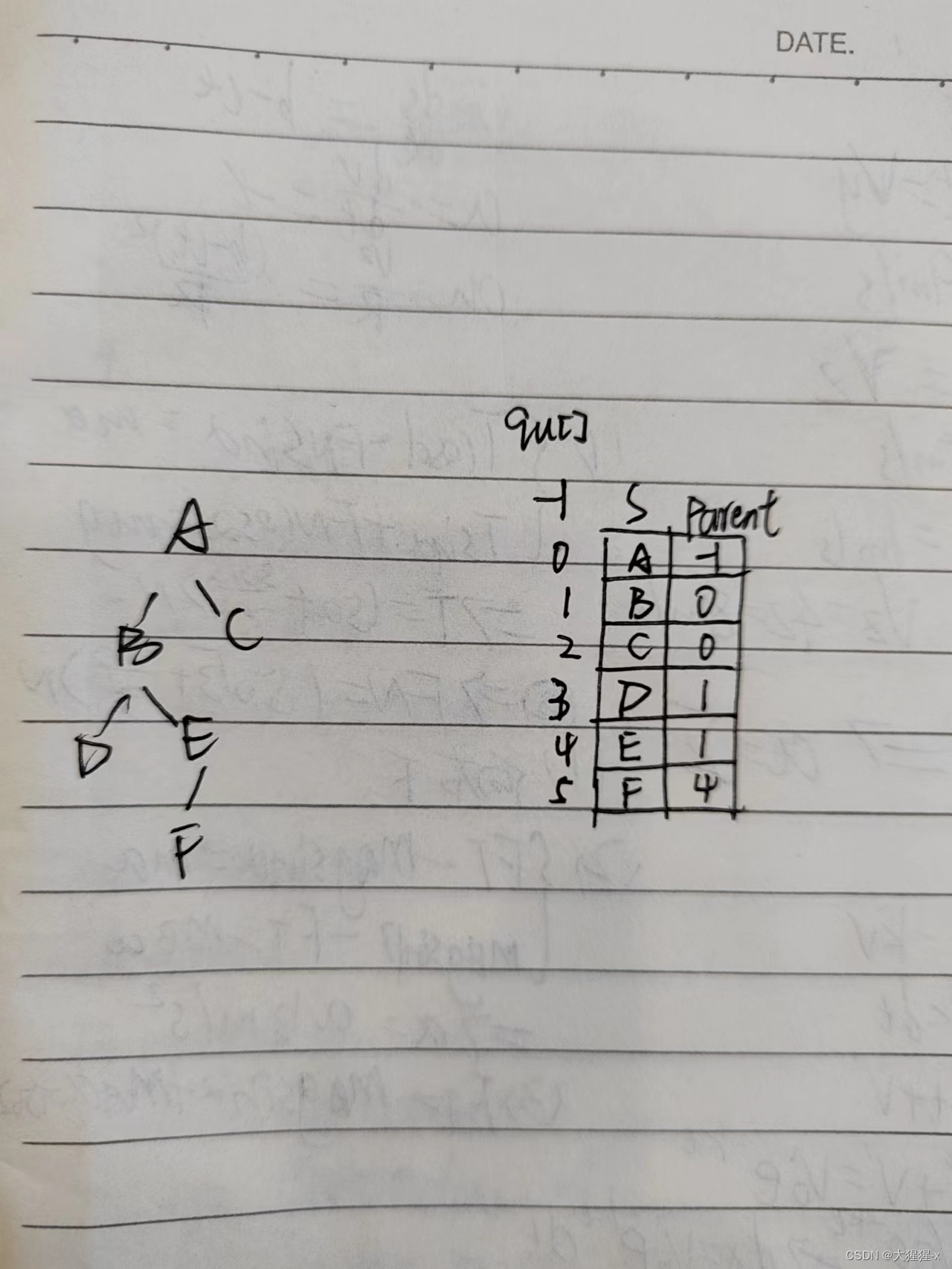
这个逻辑类似上图。parent存的是他前驱结点的qu下标。
如果不是叶子结点,就将它的左右孩子(若存在)分别进队,并且将它的parent值存为队头值(就是它的前驱)。
if(p->lchild!=NULL)
{
rear++;
qu[rear].s=p->lchild;
qu[rear].parent=front;
}
if(p->rchild!=NULL)
{
rear++;
qu[rear].s=p->rchild;
qu[rear].parent=front;
}
}
}整个代码如下:
#include<stdio.h>
#define MaxSize 100
typedef char ElemType;
typedef struct tnode
{
ElemType data;
struct tnode *lchild,*rchild;
}BTNode;
void ancestor(BTNode *bt)
{
BTNode *p;
int i;
struct
{
BTNdoe *s;
int parent;
}qu[MaxSize];
int front=-1,rear=-1;
rear++;qu[rear].s=bt;
qu[rear].parent=-1;
while(front!=rear)
{
front++;
p=qu[front].s;
if(p->lchild==NULL && p->rchild==NULL)
{
printf(" %c的所有祖先结点:",p->data);
i=qu[front].parent;
while(i!=-1)
{
printf("%c",qu[i].s->data);
i=qu[i].parent;
}
printf("\n");
}
if(p->lchild!=NULL)
{
rear++;
qu[rear].s=p->lchild;
qu[rear].parent=front;
}
if(p->rchild!=NULL)
{
rear++;
qu[rear].s=p->rchild;
qu[rear].parent=front;
}
}
}
版权声明:本文为weixin_65085475原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。