需求:使用postgresql13版本测试中文全文检索功能
安装postgresql13数据库
我这里是使用的docker容器安装测试的
1、创建一个centos7镜像容器
docker run -di --name postgres13 --privileged=true -p 5432:5432 centos:7 /usr/sbin/init
进入容器
docker exec -it postgres13 bash
以下操作都是在容器内操作!
2、安装yum源
yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
3、开始安装
yum install -y gcc gcc-c++ epel-release llvm5.0 llvm5.0-devel clang libicu-devel perl-ExtUtils-Embed readline readline-devel zlib zlib-devel openssl openssl-devel pam-devel libxml2-devel libxslt-devel openldap-devel systemd-devel tcl-devel python-devel centos-release-scl-rh
yum makecache
yum -y install postgresql13-server.x86_64 postgresql13-devel.x86_64
5、初始化数据库
/usr/pgsql-13/bin/postgresql-13-setup initdb
systemctl enable postgresql-13
systemctl start postgresql-13
6、配置账号信息
su -postgres
psql
创建用户
create user test with password '123.com';
创建数据库
create database test_db owner test;
7、设置远程配置
修改配置文件postgresql.conf – 允许远程
位置:
/var/lib/pgsql/13/data/postgresql.conf
修改:
listen_addresses = '*'
修改配置文件pg_hba.conf – 访问规则
位置:
/var/lib/pgsql/13/data/pg_hba.conf
修改:底部Ipv4下新增
host all all 0.0.0.0/0 md5
访问规则
重启服务
systemctl restart postgresql-13.service
安装中文检索组件
安装
zhparser
安装zhparser前,需要安装scws
安装编译工具
yum install gcc make wget git -y
wget http://www.xunsearch.com/scws/down/scws-1.2.3.tar.bz2
./configure && make && make install
git clone https://github.com/amutu/zhparser.git
export PATH=/usr/pgsql-13/bin:$PATH
make && make install
登录数据库
[root@229372496fad zhparser-master]# su - postgres
-bash-4.2$ psql
psql (13.4)
Type "help" for help.
#创建扩展
postgres=# create extension zhparser;
CREATE EXTENSION
postgres=# \dFp
List of text search parsers
Schema | Name | Description
------------+----------+---------------------
pg_catalog | default | default word parser
public | zhparser |
(2 rows)
#将扩展应用到配置中
postgres=# create text search configuration chinese (PARSER = zhparser);
CREATE TEXT SEARCH CONFIGURATION
#查看所有语言列表
postgres=# \dF
List of text search configurations
Schema | Name | Description
------------+------------+---------------------------------------
pg_catalog | arabic | configuration for arabic language
pg_catalog | danish | configuration for danish language
pg_catalog | dutch | configuration for dutch language
pg_catalog | english | configuration for english language
.
.
.
public | chinese |
(24 rows)
删除中文检索扩展命令
test_db=# drop extension zhparser CASCADE ;
NOTICE: drop cascades to text search configuration chinese
DROP EXTENSION
使用全文检索
查看数据库中已经安装的全文检索配置
\dF *

postgresql官方提供了一种数据类型tsvector来存储预处理后的文档,还提供了一种类型tsquery来表示处理过的
查询
。有很多函数和操作符可以用于这些
数据类型
,其中最重要的是匹配操作符
@@
,通过动态检索自然语言文档的集合,定位到最匹配的查询结果。全文搜索还可以
使用索引来加速
。
使用帮助
1、PostgreSQL中的全文搜索基于匹配操作符@@,它在一个tsvector(文档)匹配一个tsquery(查询)时返回true
搜索
a fat cat sat on a mat and ate a fat rat
中存不存在
cat
和
rat
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector @@ 'cat & rat'::tsquery;
?column?
----------
t
正如以上例子所建议的,一个tsquery并不只是一个未经处理的文本,顶多一个tsvector是这样。一个tsquery包含搜索术语,它们必须是已经正规化的词位,并且可以使用 AND 、OR、NOT 以及 FOLLOWED BY
操作符结合多个术语
。有几个函数to_tsquery、plainto_tsquery以及phraseto_tsquery可用于将用户书写的文本转换为正确的tsquery,它们会主要采用正则化出现在文本中的词的方法。相似地,to_tsvector被用来解析和正规化一个文档字符串。因此在实际上一个文本搜索匹配可能看起来更像:
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery('fat & rat');
?column?
----------
t
2、在tsquery中,&(AND)操作符指定它的两个参数都必须出现在文档中才表示匹配。类似地,|(OR)操作符指定至少一个参数必须出现,而!(NOT)操作符指定它的参数不出现才能匹配。例如,查询fat & ! rat匹配包含fat但不包含rat的文档。
搜索
fat cats ate fat rats
中存在
ate
并且不存在
ca
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery('ate & ! ca');
?column?
----------
t
判断两个词是不是相邻的
SELECT to_tsvector('fatal error not fatal') @@ to_tsquery('fatal <-> error');
?column?
----------
t
SELECT to_tsvector('fatal error not fatal') @@ to_tsquery('fatal <-> fatal');
?column?
----------
f
再看下在表中运用的例子
创建表
CREATE TABLE test(id int,info TEXT,crt_time TIMESTAMP);
INSERT INTO test SELECT generate_series(1,10000),md5(random()::TEXT),clock_timestamp();
可以在没有一个索引的情况下做一次全文搜索,指定要使用english配置来解析和正规化字符串
1、检索
info
列中的
fcd801772aa08e53eb52fefc0504467d
在
id
列的第几行
SELECT id
FROM test
WHERE to_tsvector('english', info) @@ to_tsquery('english', 'fcd801772aa08e53eb52fefc0504467d');

2、我们把表添加些中文数据,使用中文检索组件查找
test
表中
info
字段包含
数据中心
的数据
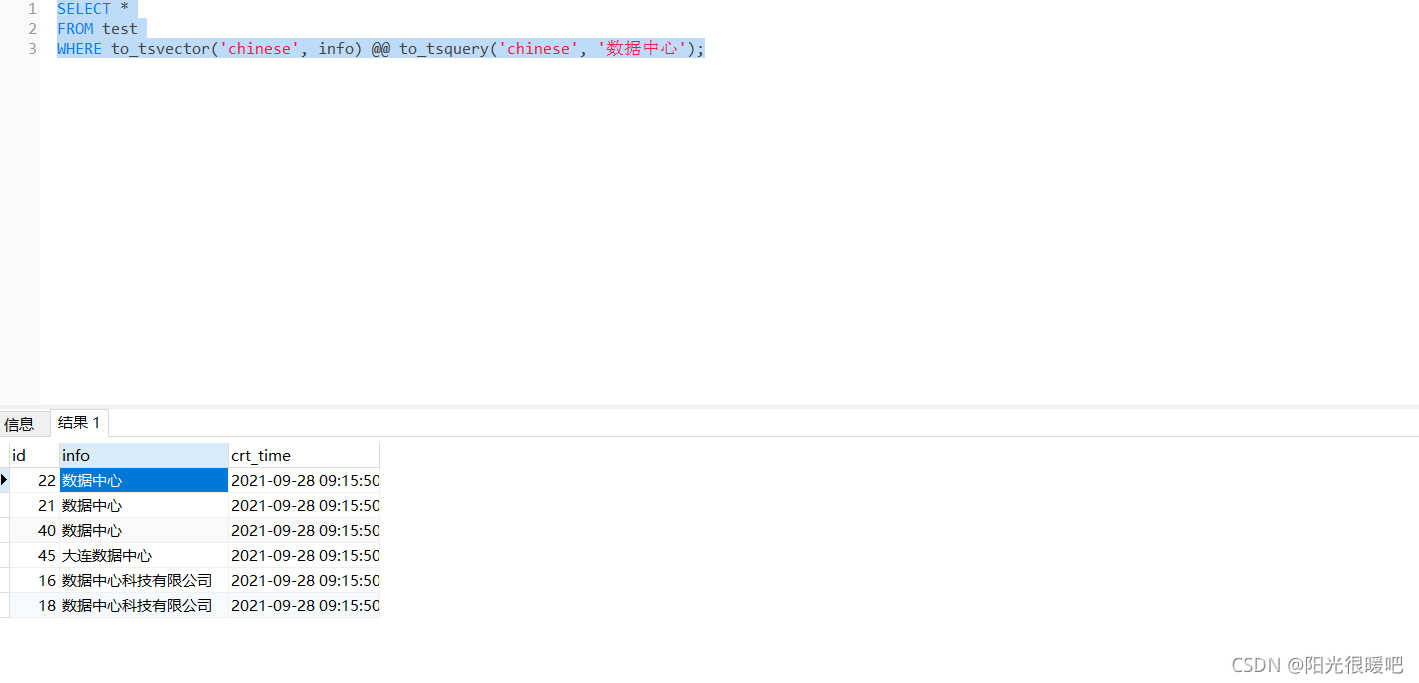
SELECT *
FROM test
WHERE to_tsvector('chinese', info) @@ to_tsquery('chinese', '数据中心');
3、在test表格中,检索字段
id
或者
info
中,包含
数据中心
和
大连
的数据
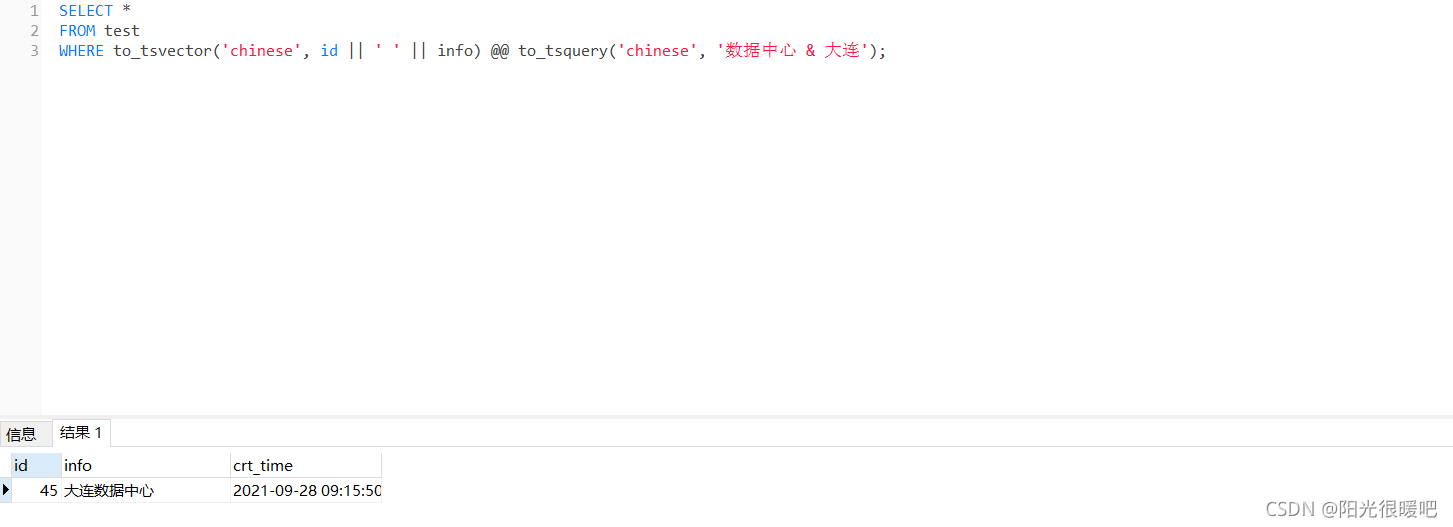
SELECT *
FROM test
WHERE to_tsvector('chinese', id || ' ' || info) @@ to_tsquery('chinese', '数据中心 & 大连');
4、在test表格中,检索字段
id
或者
info
中,包含
数据中心
但是不包含
大连
的数据
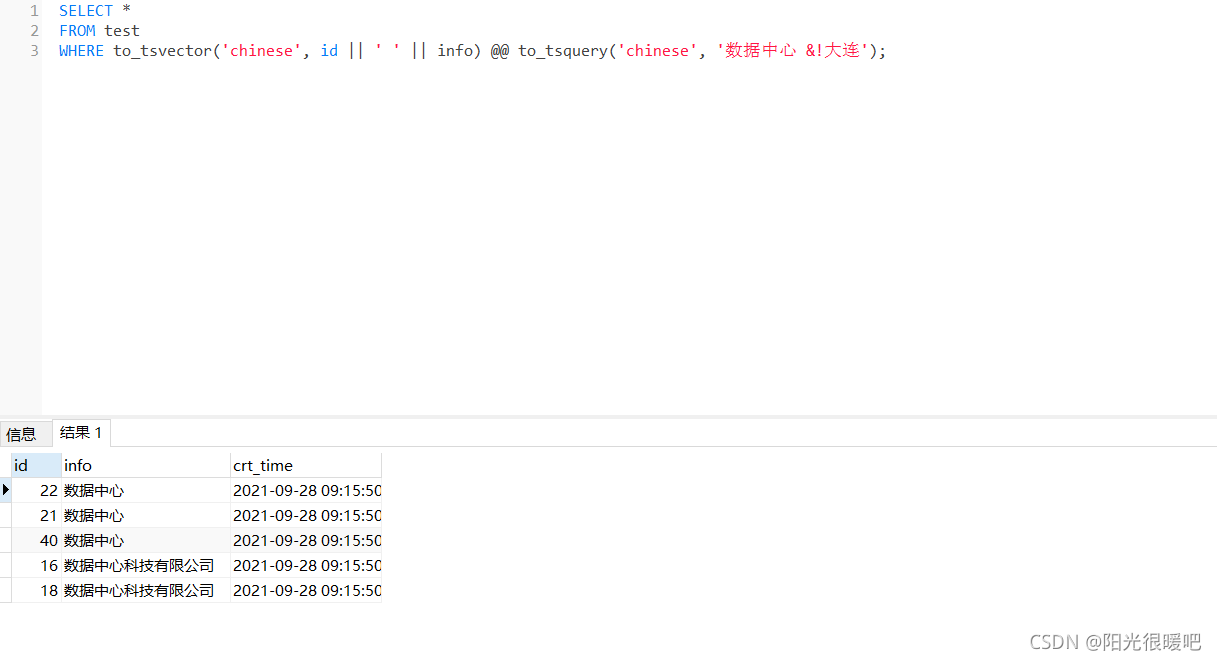
SELECT *
FROM test
WHERE to_tsvector('chinese', id || ' ' || info) @@ to_tsquery('chinese', '数据中心 &!大连');
5、匹配关于
数据
词组的所有内容(
官网
写的是匹配开头是
数据
的数据,但是我测试,是匹配所有与
数据
相关的数据)
自定义中文字典
在
CREATE EXTENSION
之后,必须配置分词参数才能正确进行分词和查找,否则什么都查不到。官方文档提供的一个配置策略是:
CREATE TEXT SEARCH CONFIGURATION chinese (PARSER = zhparser);
ALTER TEXT SEARCH CONFIGURATION chinese ADD MAPPING FOR n,v,a,i,e,l WITH simple;
n,v,a,i,e,l
这几个字母分别表示一种token策略,只启用了这几种token mapping,其余则被屏蔽。具体支持的参数和含义可以用
\dFp+ zhparser
显示:
postgres=# \dFp+ zhparser
Text search parser "public.zhparser"
Method | Function | Description
-----------------+-----------------+-------------
Start parse | zhprs_start |
Get next token | zhprs_getlexeme |
End parse | zhprs_end |
Get headline | prsd_headline | (internal)
Get token types | zhprs_lextype |
Token types for parser "public.zhparser"
Token name | Description
------------+------------------------
a | adjective,形容词
b | differentiation,区别词
c | conjunction,连词
d | adverb,副词
e | exclamation,感叹词
f | position,方位词
g | root,词根
h | head,前连接成分
i | idiom,成语
j | abbreviation,简称
k | tail,后连接成分
l | tmp,习用语
m | numeral,数词
n | noun,名词
o | onomatopoeia,拟声词
p | prepositional,介词
q | quantity,量词
r | pronoun,代词
s | space,处所词
t | time,时语素
u | auxiliary,助词
v | verb,动词
w | punctuation,标点符号
x | unknown,未知词
y | modal,语气词
z | status,状态词
(26 rows)
WITH simple
表示词典使用的是内置的simple词典,即仅做小写转换。根据需要可以灵活定义词典和token映射,以实现屏蔽词和同义词归并等功能。
第一种方法:
使用php工具,把xdb文件格式导出成txt格式文件编辑后,再导入成xdb格式文件
优点:不需要重启数据库,不需要重新建立连接
缺点:响应速度慢
1、下载转换工具
http://www.xunsearch.com/scws/down/phptool_for_scws_xdb.zip
csdn上文件下载:
https://download.csdn.net/download/zhanremo3062/29641651
2、安装php和php工具
yum install php php-mbstring -y
3、开启导入格式UTF8
vim make_xdb_file.php
第四行改为
define('IS_UTF8_TXT', true);
4、编辑字词
vim 3.txt
#<词> <词频(TF)> <词重(IDF)> <词性(北大标注)>
新词条 12.0 2.2 n
企鹅 12.0 2.2 n
科技有 12.0 2.2 n
限公司 12.0 2.2 n
词库文件的内容每一行的格式为
词 TF IDF 词性
,
词
是必须的,而
TF
词频(Term Frequency)、
IDF
反文档频率(Inverse Document Frequency) 和
词性
都是可选的,除非确定自己的词典资料是对的且符合 scws 的配置
5、把txt文件转换成xdb文件
格式是
php make_xdb_file.php <要生成的.xdb> [导入的文本文件]
php make_xdb_file.php dict4.utf8.xdb 3.txt
6、把文件放到指定位置
我的pgsql是使用容器启动的,所以我把dict4.utf8.xdb文件放到下面目录,并改名为dict.utf8.xdb
docker cp dict4.utf8.xdb postgres13:/usr/pgsql-13/share/tsearch_data/dict.utf8.xdb
注意:默认文件名字是
dict.utf8.xdb
,不过我们也可以直接使用
txt
格式的文件当成我们的词库,会比
xdb
格式的慢。比如自定义的txt文件名字叫:
mydict.txt
,需要在
postgresql.conf
文件中添加:
zhparser.extra_dicts = 'mydict.txt'
,
zhparser.dict_in_memory = true
7、重启数据库并验证
test_zhparser=# SELECT *
test_zhparser-# FROM test
test_zhparser-# WHERE to_tsvector('chinese', info) @@ to_tsquery('chinese', '企鹅');
id | info | crt_time
----+--------------------+----------------------------
12 | 小企鹅科技有限公司 | 2021-10-08 09:17:26.579552
4 | 小企鹅科技有限公司 | 2021-10-08 09:17:26.579541
3 | 小企鹅 | 2021-10-08 09:17:26.57954
(3 rows)

第二种方法:
把字典实时写入到数据库表中
优点:可以把字词实时写入到字典中
缺点:需要重新创建链接,同步数据后才能使用之前添加的字词
创建完成zhparser
extension
postgres=# \c test_zhparser;
create extension zhparser;
CREATE TEXT SEARCH CONFIGURATION chinese (PARSER = zhparser);
ALTER TEXT SEARCH CONFIGURATION chinese ADD MAPPING FOR n,v,a,i,e,l WITH simple;
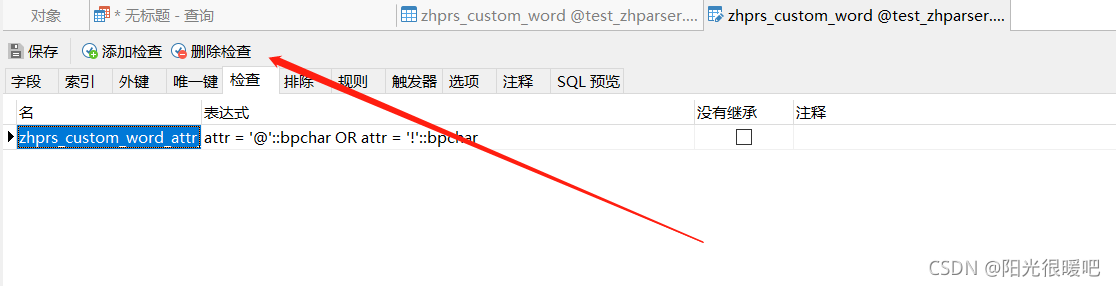
这里有一个问题,默认的
zhparser.zhprs_custom_word
表是空的,并且
attr
字段有检查,只能是
@
或者
!
,不能inset 其他数据,所以我们这里得把检查删除,并添加自定义数据即可
1、删除检查
2、添加自定义数据
#切换数据库
postgres=# \c test_zhparser;
#往表里添加数据
test_zhparser=# insert into zhparser.zhprs_custom_word (word,tf,idf,attr) values ('小企鹅',1.00,2.00,'n');
INSERT 0 1
test_zhparser=# insert into zhparser.zhprs_custom_word (word,tf,idf,attr) values ('科技',1.00,2.00,'n');
INSERT 0 1
test_zhparser=# insert into zhparser.zhprs_custom_word (word,tf,idf,attr) values ('有限',1.00,2.00,'n');
INSERT 0 1
test_zhparser=# insert into zhparser.zhprs_custom_word (word,tf,idf,attr) values ('公司',1.00,2.00,'n');
INSERT 0 1
同步下表数据,重新登录再次检索数据
test_zhparser=# select sync_zhprs_custom_word();
sync_zhprs_custom_word
------------------------
(1 row)
test_zhparser=# \q
[root@da31b86bbc9c /]# su - postgres -c psql
psql (13.4)
Type "help" for help.
postgres=# \c test_zhparser;
You are now connected to database "test_zhparser" as user "postgres".
test_zhparser=# SELECT *
FROM test
WHERE to_tsvector('chinese', info) @@ to_tsquery('chinese', '有限');
NOTICE: zhparser set dict : "/usr/pgsql-13/share/tsearch_data/dict.utf8.xdb" failed!
id | info | crt_time
----+--------------------+----------------------------
12 | 小企鹅科技有限公司 | 2021-10-08 09:17:26.579552
26 | 有限公司 | 2021-10-08 09:17:26.57957
4 | 小企鹅科技有限公司 | 2021-10-08 09:17:26.579541
(3 rows)
高亮显示检索匹配内容
postgresql本身
自带高亮功能
使用
ts_headline
即可实现
比如,检索
test
表格,关于
小企鹅
的数据,高亮显示
科技
字段
SELECT
*,ts_headline('chinese',info,to_tsquery('科技'))
FROM test
WHERE to_tsvector('chinese',info) @@ to_tsquery('chinese', '小企鹅');
高亮部分会被使用
<b> </b>
标签
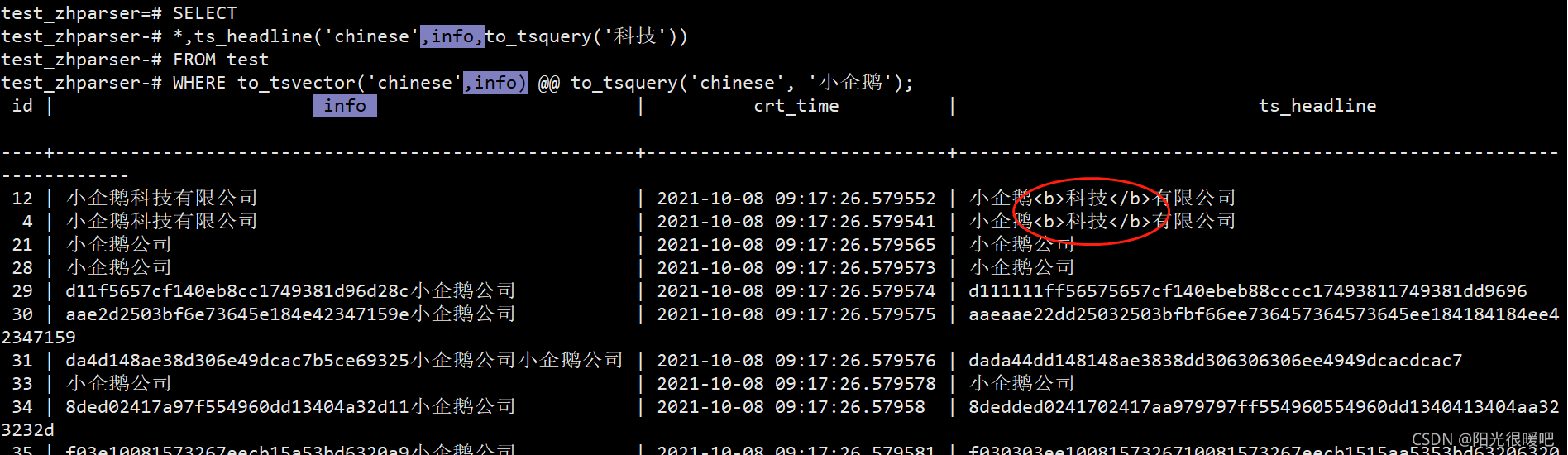
下面的例子会把在字典中的分词全部高亮显示出来
小企鹅、科技、有限、公司 这几个词是我们上面自定义字典分词的
SELECT
*,ts_headline('chinese',info,to_tsquery('chinese','小企鹅科技有限公司'))
FROM test
WHERE to_tsvector('chinese',info) @@ to_tsquery('chinese', '小企鹅科技');
id | info | crt_time | ts_headline
----+--------------------+----------------------------+------------------------------------------------
12 | 小企鹅科技有限公司 | 2021-10-08 09:17:26.579552 | <b>小企鹅</b><b>科技</b><b>有限</b><b>公司</b>
4 | 小企鹅科技有限公司 | 2021-10-08 09:17:26.579541 | <b>小企鹅</b><b>科技</b><b>有限</b><b>公司</b>
(2 rows)
下面的例子会把关于
小企鹅
或者
科技
的结果显示出来,并高亮指定分词
SELECT
*,ts_headline('chinese',info,to_tsquery('chinese','小企鹅科技有限公司'))
FROM test
WHERE to_tsvector('chinese',info) @@ to_tsquery('chinese', '小企鹅 | 科技');
控制检索结果数目
控制匹配结果数目,正常是会显示25列,使用
LIMIT
控制显示10列
SELECT
*,ts_headline('chinese',info,to_tsquery('chinese','公司'))
FROM test
WHERE to_tsvector('chinese',info) @@ to_tsquery('chinese', '小企鹅') ORDER BY test DESC LIMIT 10;
待完善内容
1、
添加索引,增加检索速度
2、
pg_search命令工具全文检索远程数据库
3、
问题总结
问题1:
make: pg_config: Command not found make: *** No targets. Stop.
解决:
export PATH=/usr/pgsql-13/bin:$PATH
再重新编译安装
make & make install
问题2:
ERROR: could not access file "$libdir/zhparser": 没有那个文件或目录
解决:
这是因为依赖文件不对,需要把文件全部替换成新编译后的依赖文件
这里就需要手动去将文件移动至指定目录:
/usr/lib64/pgsql/zhparser.so → /usr/pgsql-13/lib
(/usr/pgsql-11/是PostgreSQL安装后路径,如果PostgreSQL是使用的YUM安装方式,路径应该是一样)
还有
/usr/share/pgsql/extension/ → /usr/pgsql-13/share/extension
、
/usr/share/pgsql/tsearch_data/ → /usr/pgsql-13/share/tsearch_data
问题3:
WARNING: sql version 9.2, server version 13.0.Some psql features might not work. Type "help" for
解决:
mv /bin/psql /bin/psql-bk
ln -s /usr/pgsql-13/bin/psql /bin/psql
参考博文:
https://blog.csdn.net/qq_21948951/article/details/89680468
http://www.postgres.cn/docs/13/textsearch-tables.html
https://cloud.tencent.com/developer/article/1430039
http://pgbook.rails365.net/467197
https://www.postgresql.org/docs/9.4/textsearch-controls.html
https://www.jianshu.com/p/0dc2a8bf9631
https://github.com/amutu/zhparser/blob/master/README.md