目录
一、MySQL主从复制介绍
MySQL主从复制是MySQL内建的复制功能,是构建大型、高性能应用程序的基础。
简单来说,主从复制是将数据库主机(master)中的数据或产生数据的SQL语句复制到另一个或多个数据库主机(slaves)上,之后再执行一遍即可得到主机(master)的数据。
在这个复制过程中,master主机被称为主服务器,slave主机被称为从服务器。
1、MySQL支持的复制类型
- 基于语句(statement)的复制:在主服务器上执行SQL语句,在从服务器上执行同样的语句。MySQL默认采用基于语句的复制,效率较高。
- 基于行(row)的复制:把改变的内容复制过去,而不是把命令在从服务器上执行一遍。从MySQL 5.0开始支持。
- 混合型(mixed)的复制:默认采用基于语句的复制,一旦发现基于语句的无法精确复制时,就会采用基于行的复制。
2、为什么要做主从复制
- 灾备
- 数据分布
- 负载均衡
- 读写分离
- 提高并发能力
- 提高可用性
3、主从复制原理
主要基于MySQL二进制日志
主要包括三个线程(2个I/O线程,1个SQL线程)
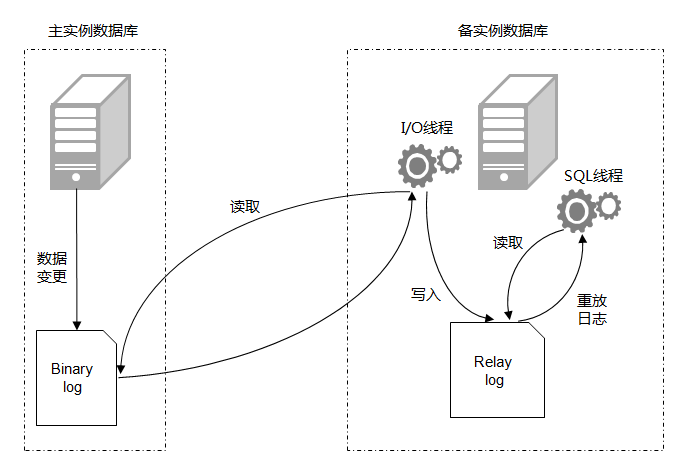
简言之,分三步曲进行:
- 主数据库有个 bin log 二进制文件,记录了所有增删改 SQL 语句。(IO线程)
- 从数据库把主数据库的 bin log 文件的 SQL 语句复制到自己的中继日志 relay log(IO线程)
- 从数据库的 relay log 重做日志文件,再执行一次这些sql语句。(SQL线程)
详细步骤:
- 从库通过手工执行change master to 语句连接主库,提供了连接的用户一切条件(user 、password、port、ip),并且让从库知道,二进制日志的起点位置(file名 position 号); start slave
- 从库的IO线程和主库的IO线程建立连接。
- 从库根据change master to 语句提供的file名和position号,IO线程向主库发起binlog的请求。
- 主库IO线程根据从库的请求,将本地binlog以events的方式发给从库IO线程。
- 从库IO线程接收binlog events,并存放到本地relay-log中,传送过来的信息,会记录到master.info中
- 从库SQL线程应用relay-log,并且把应用过的记录到relay-log.info中,默认情况下,已经应用过的relay 会自动被清理(purge)
4、MySQL主从复制数据同步的策略
以上就是主从复制的过程,当然,主从复制的过程有不同的策略方式进行数据的同步,主要包含以下几种:
-
同步策略
:Master会等待所有的Slave都回应后才会提交,这个主从的同步的性能会严重的影响。 -
半同步策略
:Master至少会等待一个Slave回应后提交。 -
异步策略
:Master不用等待Slave回应就可以提交。 -
延迟策略
:Slave要落后于Master指定的时间。
对于不同的业务需求,有不同的策略方案,但是一般都会采用最终一致性,不会要求强一致性,毕竟强一致性会严重影响性能。
二、MySQL主从复制的配置(一主双从)
大致步骤:
1.主库上(master):
在配置文件中选择唯一的server-id,开启binlog日志;
创建一个具有复制权限的用户
2.从库上(slave):
在配置文件中选择唯一的server-id,开启中继日志(默认开启);
连接至主库,并开启复制;
检查连接启动是否正常
环境准备:
MySQL版本:mysql 5.7.36
服务器:
| IP地址 | 端口 | |
| 主库 | 192.168.5.132 | 3306 |
| 从库1 | 192.168.5.133 | 3306 |
| 从库2 | 192.168.5.134 | 3306 |
1、主库配置
1)设置唯一server-id,开启binlog日志
修改配置文件;
[mysqld]
log_bin = mysql-bin
server_id = 132
重启mysql服务。
2)创建具有复制权限的用户账号
mysql> grant replication slave on *.* to 'rep'@'192.168.95.%' identified by
'123456';
3)锁表设置只读
为后面备份准备,注意生产环境要提前申请停机时间;
mysql> flush tables with read lock;
4)查看主库状态
查看主库状态,即当前日志文件名和二进制日志偏移量
mysql> show master status;
5)备份数据库数据
mysqldump -uroot -p -A -B |gzip > /backup/mysql_bak.$(date +%F).sql.gz
6)解锁
mysql> unlock tables;
7)主库备份数据上传到两个从库
scp /backup/mysql_bak.2023-04-03.sql.gz 192.168.5.133:~
scp /backup/mysql_bak.2023-04-03.sql.gz 192.168.5.134:~
2、从库配置
1)设置server-id值
#从库1
[mysqld]
server_id = 133#从库2
[mysqld]
server_id = 134重启数据库;
2)还原从主库拷贝过来的备份数据
zcat mysql_bak.2023-04-03.sql.gz | mysql -uroot -p检查还原:
mysql -uroot -p -e ‘show databases;’
3)设定从主库同步
# 从库1
mysql> change master to
MASTER_HOST='192.168.5.133',
MASTER_PORT=3306,
MASTER_USER='rep',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=149;# 从库2
mysql> change master to
MASTER_HOST='192.168.5.134',
MASTER_PORT=3306,
MASTER_USER='rep',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000003',
MASTER_LOG_POS=149;
4)启动从库同步开关
mysql> start slave;
5)检查状态
mysql> show slave status\G

一定要注意Slave_IO_Running参数和Slave_SQL_Running参数应都为Yes,否则代表主从复制异常。这两个参数分别代表:
- Slave_IO_Running:IO线程是否打开 YES/No/NULL
- Slave_SQL_Running:SQL线程是否打开 YES/No/NULL
三、利用MyCAT2配置读写分离
大致步骤:
- 创建数据源
- 创建集群
- 创建逻辑库
- 修改逻辑库的数据源
- 测试读写分离是否成功
环境准备:
MyCAT版本:MyCAT2-1.21
新增一个MyCAT服务器
| IP地址 | 端口 | |
| MyCAT服务器 | 192.168.5.136 | 8066 |
登录mycat客户端进行以下配置。
1、创建数据源
# 添加读写的数据源
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"m1",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.5.132:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0
} */;# 添加读的数据源(从库1)
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"m1s1",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.5.133:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0
} */;# 添加读的数据源(从库2)
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"m1s2",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.5.134:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0
} */;查看数据源
/*+ mycat:showDataSources{} */;
这里由于篇幅原因,就给大家看一下数据源目录显示结果:

2、创建集群
/*! mycat:createCluster{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"m1"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"m1s1",
"m1s2"
],
"switchType":"SWITCH"
} */;
查询集群
/*+ mycat:showClusters{} */;
集群目录结果:

3、创建逻辑库
CREATE DATABASE db1 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
4、修改逻辑库的数据源
修改conf/schemas/db1.schema.json,在里面添加 “targetName”:”prototype”
vim /mycat-data/mycat/conf/schemas/db1.schema.json
cat /mycat-data/mycat/conf/schemas/db1.schema.json
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"db1",
"shardingTables":{},
"views":{},
"targetName":"prototype"
}
5、重启MyCAT,配置完成
cd /mycat-data/mycat/bin/
./mycat restart