
背景
由于公司管理层决定要将云平台从阿里云切换成 AWS,所以部署在阿里云上的所有中间件服务都需要迁移,包括 kafka, zookeeper 等。由于 zookeeper 集群保存着重要的状态信息,而且迁移过程中极易出错,在此记录,方便有需要的读者参考。
迁移要求
对 zookeeper 集群的迁移,需要保证两点:
1)数据不能丢
2)服务不能中断
即对于业务方来说,迁移过程应该是尽量无感知的,不能影响到业务。
实施方案
zookeeper 集群的迁移,针对不同的 zk 部署版本,迁移过程也有所区别。如果 zk 版本 >= 3.5,那么 zk 集群支持动态配置,此时迁移过程会简单很多(参考 zookeeper 官网介绍
https://zookeeper.apache.org/doc/r3.5.9/zookeeperReconfig.html
)
而对于 zk < 3.5 之前的版本,可以有两种解决方案:
(1)停机迁移
(2)平滑迁移
方案一 停机迁移
这个方案最简单,操作方便,先把旧节点上的 zk 进程停掉,然后将 zk 数据目录 copy 一份到新节点,然后启动新节点进程即可。但缺点是迁移期间无法继续提供服务,而且停机时间视数据目录大小 copy 耗时而定。因此该方案适用于非线上环境 zookeeper 集群迁移。

zookeeper停机迁移
方案二 平滑迁移
该方案的基本思路是先扩展 zookeeper 集群到新节点,然后下线旧节点,在整个迁移过程中 zk 集群可以持续提供服务。因此,平滑迁移可以保证服务不中断,适合线上环境执行,但缺点是操作复杂,容易出错。
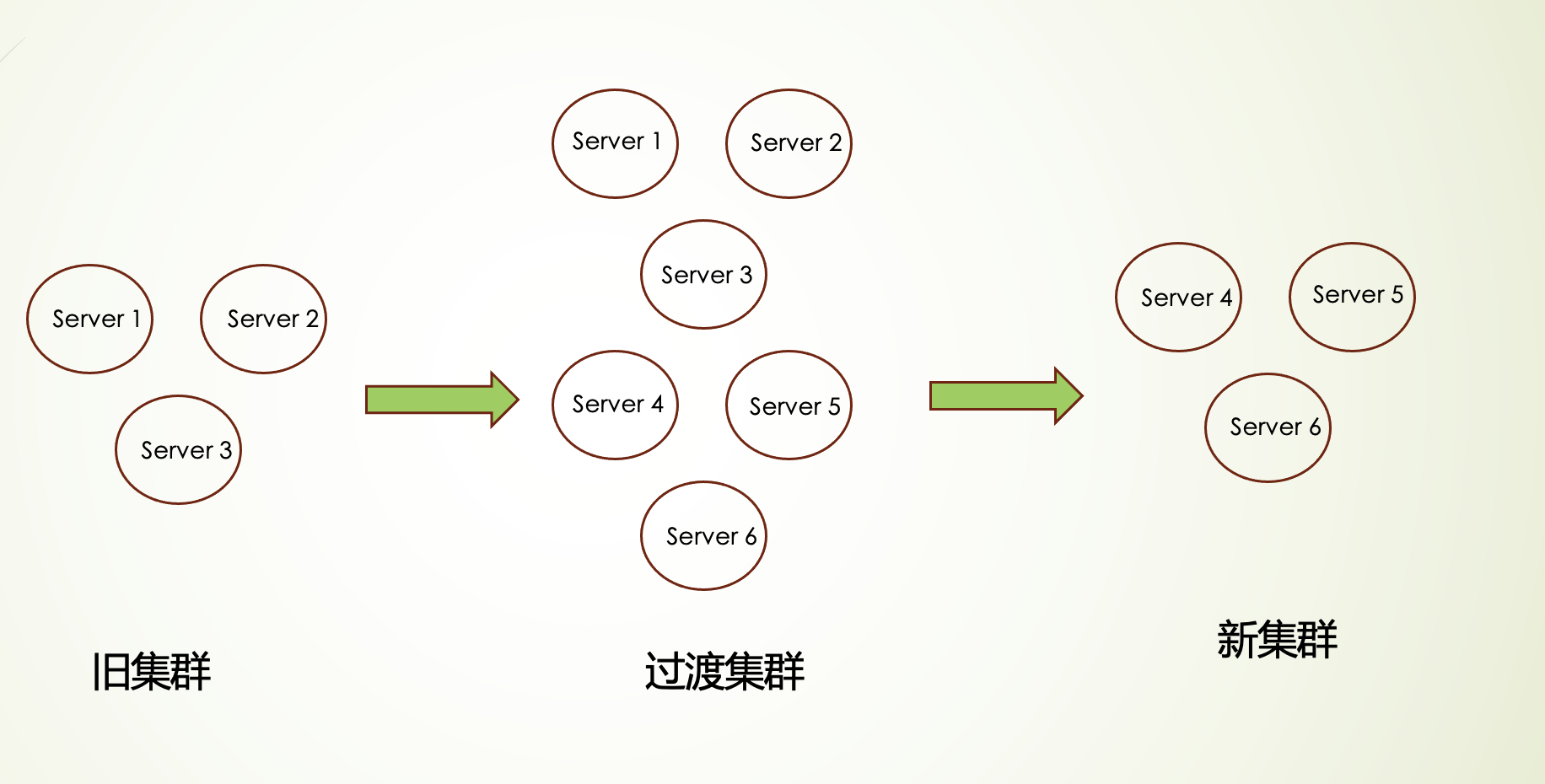
zookeeper集群平滑迁移
具体迁移流程
由于我们目前部署的 zk 集群版本为 3.4.12,为了保证线上服务不中断,我们采用平滑迁移方案。
假定迁移前集群由 server1, server2, server3 组成,迁移后集群由 server4, server5, server6 组成。原有节点配置如下所示:
server.1=localhost:2881:3881server.2=localhost:2882:3882server.3=localhost:2883:3883
复制代码
迁移流程如下:
1)新增 ID 为 4,5,6 的节点(注意,新增节点 id 需要大于旧节点 id),并依次启动 server4, server5, server6,其中 server4 需要进行二次重启。
server4 的配置如下:
server.1=localhost:2881:3881server.2=localhost:2882:3882server.3=localhost:2883:3883server.4=localhost:2884:3884server.5=localhost:2885:3885#需要在启动server6后进行第二次重启并打开剩余节点注释#server.6=localhost:2886:3886
复制代码
server5 的配置如下:
server.1=localhost:2881:3881server.2=localhost:2882:3882server.3=localhost:2883:3883server.4=localhost:2884:3884server.5=localhost:2885:3885server.6=localhost:2886:3886
复制代码
server6 的配置如下:
server.1=localhost:2881:3881server.2=localhost:2882:3882server.3=localhost:2883:3883server.4=localhost:2884:3884server.5=localhost:2885:3885server.6=localhost:2886:3886
复制代码
即新增节点的启动顺序为 server4(列表中不包含 server6) -> server5 -> server6 -> 重启 server4(包含完整列表)。
2)对 1,2,3 节点的配置文件,分别补充新增节点列表,e.g.
server.1=localhost:2881:3881
server.2=localhost:2882:3882
server.3=localhost:2883:3883
server.4=localhost:2884:3884
server.5=localhost:2885:3885
server.6=localhost:2886:3886
3)对原节点 1,2,3 中的 follower 节点,分别进行重启
可以使用命令 echo mntr|nc localhost 2181 来查看当前集群节点的角色。
假设现在节点 2 是 leader,那么分别重启节点 1 和节点 3(此时除了节点 2,其余节点都能看到集群有 6 个 member)
4)对原节点 1,2,3 中的 leader 节点,进行重启
重启原 leader 节点之前,先确认 follower 节点已经同步完成 echo mntr|nc localhost 2181
zk_followers 5
zk_synced_followers 5
重启旧 leader 后,会选举出新的 leader(一般是 id 最大的节点),假设为节点 6。
至此,我们拥有了一个 6 个节点组成的新 zk 集群,其中 3 个旧节点,3 个新节点。
5)对外发布新节点 4,5,6 组成的连接串(即业务方将使用这个串进行新集群交互)
这一步很重要,它可以让业务方通过新地址串连接 zk 集群,方便我们后续下线旧节点。比如我们目前的集群有 6 个节点组成,但是我们对外发布 e.g. ip4:2181,ip5:2181,ip6:2181 的新节点连接串,这样业务方就不再感知旧节点,后续我们下线旧节点时就不会对业务方造成影响。
6)确认业务方替换完新连接串后(注意,因为新连接串只包含 4,5,6 节点,所以如果业务方替换完后,不会再有业务方机器连接旧节点):
A.先下线节点 1 (此时可用节点为 5 个,满足 6 个节点集群需要至少 4 个可用的要求),剩余两个可用的旧节点用来滚动替换,最终建成一个 3 个新节点的集群。
B.剩余 2,3,4,5,6 节点分别将节点 1 的配置从 zoo.cfg 中删除/注释,然后按先 follower,后 leader 的顺序重启各个节点,这样形成 5 个节点的 zk 集群。
C.对于 5 个节点的集群,可以容忍两个节点失效,因此,先下线旧节点 2,然后对于剩余的 3,4,5,6 节点分别将节点 2 的配置从 zoo.cfg 中删除/注释,然后按先 follower,后 leader 的顺序重启各个节点,这样形成 4 个节点的集群。
D.对于 4 个节点的集群,可以容忍一个节点失效,此时要注意不能直接下线节点 3,否则后续重启节点 4,5,6 时会造成集群不可用。因此对于剩余的 4,5,6 节点分别将节点 3 的配置从 zoo.cfg 中删除/注释,然后按先 follower,后 leader 的顺序重启各个节点,这样最终形成 3 个新节点的集群,此时下线最后一个旧节点 3。
7) done,此时最终形成节点 4,5,6 组成的新集群,数据跟旧集群一致。
注意事项
1.新增节点必须按照节点顺序依次启动,不能同时启动新增节点,关键因素就是先要保持原有的 leader 不变,不能因为新增节点导致重新选举。
这里我们要解释下为什么第一次启动节点 4 时配置列表中不能包含节点 6,假设我们包含节点 6,那么节点 4 看到集群包含 6 个节点,需要至少 4 个节点选择一致才能确定 leader 节点,而这时节点 1,2,3 会有一致选择,而节点 4,5,6 会有一致选择,都达不到确定 leader 节点的要求。
2.新增节点的 id 必须大于原有节点 id。这是因为 zookeeper 在两个节点之间建立连接时,只允许 id 较大的节点向 id 较小的节点发起连接,如果 id 较小的节点向 id 较大的节点发起连接,会被舍弃,如下图所示:

id较小的节点向id较大节点发起连接
假设新增节点 id 比原有节点 id 小,会出现什么情况呢?
答案就是会出现两个 leader,并且最后会导致数据不一致,如下图所示:

当前集群状态,出现两个leader
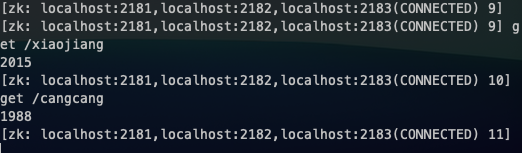
最后形成的leader为4,此时集群所存数据
而真实数据为原来 leader,节点 5 的数据为
/xiaojiang = ‘born-in-beihai’
/cangcang = ‘born-in-hangzhou’
造成这种状况的根本原因,在于重启原有 leader 节点前,现有集群节点没有全部处于 sync 状态。而新增较小的节点 id,使得在各个新增节点重启过程中出现较大 id 节点(原有节点)无法感知较小 id 节点加入集群的情况:
id较大节点无法感知较小id节点的加入
举个例子,原来有节点 4,5,6(leader 为 5),新增节点 1,2,3,那么启动完新增节点后,整个 zk 集群还是只有原来的 4,5,6 节点处于 sync 状态,此时节点 1,2,3 都处于寻找 leader 状态,并且都投票给节点 3(相同情况下,编号大的胜出)。那么当重启节点 4 后,节点 1,2,3,4 选出了节点 4 作为 leader(选票数超过 6 个节点的一半),而此时节点 5,6 仍然组成以 5 为 leader 的集群,这时两个集群都能提供服务,那么很明显数据将出现不一致。而后面继续重启节点 6 和节点 5 时,leader 仍为节点 4(仍然获得超过集群一半以上节点的支持),那么最后整个集群将以 leader(节点 4)的数据作为依据,因而先前在节点 5 作为 leader 期间变更的数据将丢失!!! 这无疑会是灾难性的后果。
3.在对外提供新集群连接串时,不要包含老节点地址。
业务方客户端在使用 zk 连接串时,都会随机挑一个地址进行尝试,如果无法连接则尝试下一个地址。因此我们只提供新地址组成的连接串,可以方便我们后续判断是否所有业务方都已使用新串进行连接。
4.在进行迁移的第 6 步进行滚动下线的 D 步骤时,要注意:不能先下线节点 3 然后再依次进行重启新节点。这是因为对于 4 个节点集群只能容忍一个节点失效,如果先下线节点 3,那么后续重启任何一个节点都将使得 zk 集群在重启期间不可用。
遇到的问题
1.zk server 上有保留着已建立连接的 established 信息(netstat -ntap),但是对应 server 却没有相应的连接。
这个问题比较诡异,不好排查,不影响操作流程。在 zookeeper 官网上找到一个原因可供参考:
Some broken network infrastructure may lose the FIN packet that is sent from closing client. These never closed client sockets cause OS resource leak.
解决方案:
官方文档有提到一个配置(clientTcpKeepAlive,3.6.1 开始支持)
Setting this to true sets the TCP keepAlive flag on the client sockets. Enabling this option terminates these zombie sockets by idle check.
2.迁移过程中 zk server 中可能会看到类似的日志:
Too many connections from /172.23.xxx.xxx - max is 60复制代码
这个 warning 日志表示当前 server 接受的客户端连接数超过了默认给每个客户端 IP 使用的连接数,如果想调整这个参数,重新设置
maxClientCnxns
即可,e.g.
# set max client connectsmaxClientCnxns=300
复制代码
总结
3.5 版本前的 zk 迁移比较繁琐,容易出错,在迁移前也查阅了一些资料,但都没有详细的迁移步骤,在参考相关资料及自身搭建测试环境验证后,顺利完成了线上环境 zk 集群的迁移。为了避免后来人走弯路出错导致集群数据不一致或者服务中断,留下经过验证的一些迁移步骤,希望对大家有所帮助。
大家有更好的迁移计划也欢迎留言探讨~