1.正则表达式基本语法
为什么使用正则表达式?
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术对于对静态文本执行简单搜索和替换任务可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,即使不是不可能,至少也会变得很困难。
通过使用正则表达式,可以:
-
测试字符串内的模式。
例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。 -
替换文本。
可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。 -
基于模式匹配从字符串中提取子字符串。
可以查找文档内或输入域内特定的文本。
例如,您可能需要搜索整个网站,删除过时的材料,以及替换某些 HTML 格式标记。在这种情况下,可以使用正则表达式来确定在每个文件中是否出现该材料或该 HTML 格式标记。此过程将受影响的文件列表缩小到包含需要删除或更改的材料的那些文件。然后可以使用正则表达式来删除过时的材料。最后,可以使用正则表达式来搜索和替换标记。
使用 ? 和 * 通配符来查找硬盘上的文件。?通配符匹配文件名中的 0 个或 1 个字符,而 * 通配符匹配零个或多个字符。像
data(\w)?.dat
这样的模式将查找下列文件:
data.dat
data1.dat
data2.dat
datax.dat
dataN.dat
使用 ***** 字符代替
?
字符扩大了找到的文件的数量。
data.*.dat
匹配下列所有文件:
data.dat
data1.dat
data2.dat
data12.dat
datax.dat
dataXYZ.dat
两个特殊的符号’^‘和’$’。他们的作用是分别指出一个字符串的开始和结束。例子如下:
“^The”:表示所有以”The”开始的字符串(“There”,”The cat”等);
“of despair
”
:
表
示
所
以
以
”
o
f
d
e
s
p
a
i
r
”
结
尾
的
字
符
串
;
”
a
b
c
“:表示所以以”of despair”结尾的字符串; “^abc
”
:
表
示
所
以
以
”
o
f
d
e
s
p
a
i
r
”
结
尾
的
字
符
串
;
”
a
b
c
”:表示开始和结尾都是”abc”的字符串——呵呵,只有”abc”自己了;
“notice”:表示任何包含”notice”的字符串。
象最后那个例子,如果你不使用两个特殊字符,你就在表示要查找的串在被查找串的任意部分——你并
不把它定位在某一个顶端。
其它还有’*’,’+‘和’?’这三个符号,表示一个或一序列字符重复出现的次数。它们分别表示“没有或
更多”,“一次或更多”还有“没有或一次”。下面是几个例子:
“ab*”:表示一个字符串有一个a后面跟着零个或若干个b。(“a”, “ab”, “abbb”,……);
“ab+”:表示一个字符串有一个a后面跟着至少一个b或者更多;
“ab?”:表示一个字符串有一个a后面跟着零个或者一个b;
“a?b+$”:表示在字符串的末尾有零个或一个a跟着一个或几个b。
你也可以使用范围,用大括号括起,用以表示重复次数的范围。
“ab{2}”:表示一个字符串有一个a跟着2个b(“abb”);
“ab{2,}”:表示一个字符串有一个a跟着至少2个b;
“ab{3,5}”:表示一个字符串有一个a跟着3到5个b。
请注意,你必须指定范围的下限(如:”{0,2}“而不是”{,2}”)。还有,你可能注意到了,’*’,’+’和
‘?‘相当于”{0,}”,”{1,}“和”{0,1}”。
还有一个’¦’,表示“或”操作:
“hi¦hello”:表示一个字符串里有”hi”或者”hello”;
“(b¦cd)ef”:表示”bef”或”cdef”;
“(a¦b)*c”:表示一串”a”“b”混合的字符串后面跟一个”c”;
‘.’可以替代任何字符:
“a.[0-9]”:表示一个字符串有一个”a”后面跟着一个任意字符和一个数字;
“^.{3}$”:表示有任意三个字符的字符串(长度为3个字符);
方括号表示某些字符允许在一个字符串中的某一特定位置出现:
“[ab]”:表示一个字符串有一个”a”或”b”(相当于”a¦b”);
“[a-d]”:表示一个字符串包含小写的’a’到’d’中的一个(相当于”a¦b¦c¦d”或者”[abcd]”);
“
1
”:表示一个以字母开头的字符串;
“[0-9]%”:表示一个百分号前有一位的数字;
“,[a-zA-Z0-9]$”:表示一个字符串以一个逗号后面跟着一个字母或数字结束。
你也可以在方括号里用’
‘表示不希望出现的字符,’
‘应在方括号里的第一位。(如:”%[^a-zA-Z]%”表
示两个百分号中不应该出现字母)。
为了逐字表达,你必须在”^.$()¦*+?{“这些字符前加上转移字符’’。
请注意在方括号中,不需要转义字符。
微信扫码,回复 “ 666 ” 领取正则相关资料!
2.正则表达式验证控制文本框的输入字符类型
1.只能输入数字和英文的:
2.只能输入数字的:
3.只能输入全角的:
4.只能输入汉字的:
3.正则表达式的应用实例通俗说明
//校验是否全由数字组成
/
2
{1,20}$/
^ 表示打头的字符要匹配紧跟^后面的规则
$ 表示打头的字符要匹配紧靠$前面的规则
[ ] 中的内容是可选字符集
[0-9] 表示要求字符范围在0-9之间
{1,20}表示数字字符串长度合法为1到20,即为[0-9]中的字符出现次数的范围是1到20次。
/^ 和 $/成对使用应该是表示要求整个字符串完全匹配定义的规则,而不是只匹配字符串中的一个子串。
//校验登录名:只能输入5-20个以字母开头、可带数字、“_”、“.”的字串
/
3
{1}([a-zA-Z0-9]|[._]){4,19}$/
4
{1} 表示第一个字符要求是字母。
([a-zA-Z0-9]|[.
]){4,19} 表示从第二位开始(因为它紧跟在上个表达式后面)的一个长度为4到9位的字符串,它要求是由大小写字母、数字或者特殊字符集[.
]组成。
//校验用户姓名:只能输入1-30个以字母开头的字串
/
5
{1,30}$/
//校验密码:只能输入6-20个字母、数字、下划线
/^(\w){6,20}$/
\w:用于匹配字母,数字或下划线字符
//校验普通电话、传真号码:可以“+”或数字开头,可含有“-” 和 “ ”
/
6
{0,1}(\d){1,3}[ ]?([-]?((\d)|[ ]){1,12})+$/
\d:用于匹配从0到9的数字;
“?”元字符规定其前导对象必须在目标对象中连续出现零次或一次
可以匹配的字符串如:+123 -999 999 ; +123-999 999 ;123 999 999 ;+123 999999等
正则表达式的使用的基本语法:
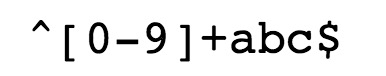
-
^
为匹配输入字符串的开始位置。 -
[0-9]+
匹配多个数字,
[0-9]
匹配单个数字,
+
匹配一个或者多个。 -
abc
∗∗
匹
配
字
母
∗
∗
a
b
c
∗
∗
并
以
∗
∗
a
b
c
∗
∗
结
尾
,
∗
∗
**匹配字母 **abc** 并以 **abc** 结尾,**
∗
∗
匹
配
字
母
∗
∗
a
b
c
∗
∗
并
以
∗
∗
a
b
c
∗
∗
结
尾
,
∗
∗
为匹配输入字符串的结束位置。
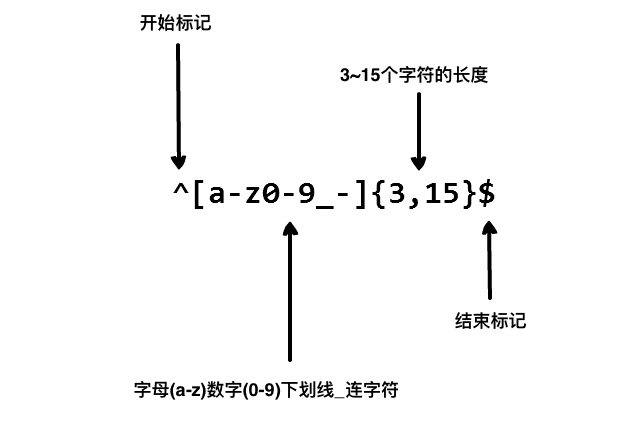
我们在写用户注册表单时,只允许用户名包含字符、数字、下划线和连接字符(-),并设置用户名的长度,我们就可以使用以下正则表达式来设定。
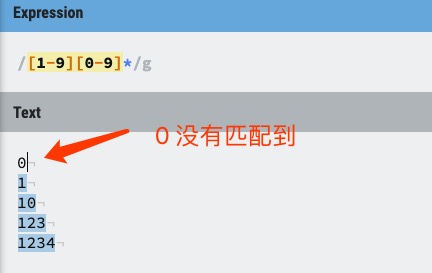
以下正则表达式匹配一个正整数,
[1-9]
设置第一个数字不是 0,
[0-9]*
表示任意多个数字:
/[1-9][0-9]*/
如果你想设置 0~99 的两位数,可以使用下面的表达式来至少指定一位但至多两位数字。
/[0-9]{1,2}/
上面的表达式的缺点是,只能匹配两位数字,而且可以匹配 0、00、01、10 99 的章节编号仍只匹配开头两位数字。
改进下,匹配 1~99 的正整数表达式如下:
/[1-9][0-9]?/
或
/[1-9][0-9]{0,1}/
- 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
定位符
定位符用来描述字符串或单词的边界,
^
和
$
分别指字符串的开始与结束,
\b
描述单词的前或后边界,
\B
表示非单词边界。
实例
匹配数字开头
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<script>
var str = "abc123456789def";
var patt1 = /[0-8]+/;
document.write(str.match(patt1));
</script>
</body>
</html>
运行结果:12345678
匹配以数字开头,并以 abc 结尾的字符串。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<script>
var str = "12345abcd";
var patt1 = /^[0-9]+abcd$/;
document.write(str.match(patt1));
</script>
</body>
</html>
运行结果:12345abcd