我们在使用set集合时会发现,集合里的元素是不会重复的。
实例演示
HashSet<String> set = new HashSet<>();
set.add("abc");
set.add("abc");
set.add("张三");
set.add("李四");
System.out.println(set);
我们可以看到我们加入了两次abc,但是输出结果只会显示一次。
[李四, 张三, abc]
首先,我们利用第一条语句创建了一个空间
HashSet<String> set = new HashSet<>();

当我们调用set的add方法时,会调用元素的hashcode和equals方法,来判断元素是否重复。
先存入第一个abc

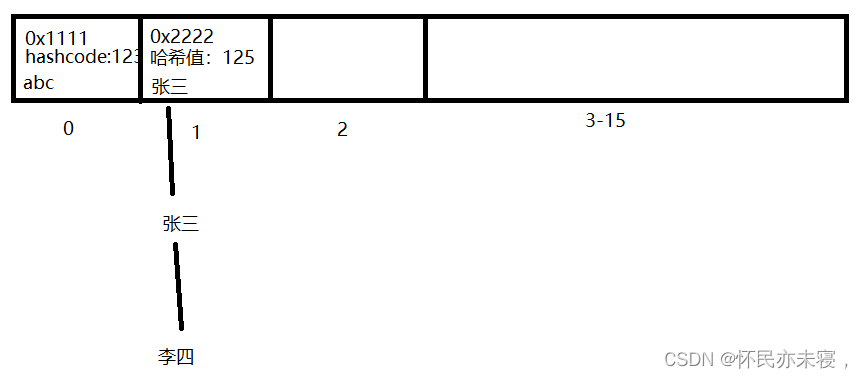
我们设它的哈希值为123,地址值为0x1111。当存入第二个abc时,系统计算到第二个元素的哈希值也是123,然后用equals方法比较他们的内容,系统发现他们的内容相同。那么程序就不会把第二个abc存进去。
接下来存入“张三”,过程是一样的,先比较哈希值,发现没有相同的哈希值,那么程序就会直接将张三存入

存入“李四”也是同理。
注意:在set集合中元素存入集合后,并不会按照存入的顺序排列。排列的顺序是随机的。
第二种情况:
如果两个元素的哈希值相同但是用equals比较后内容是不同的,那么他们会存在同一个位置上。假设李四与张三的哈希值相同。
版权声明:本文为m0_72466001原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。