目录
mixup是一种简单而有效的数据增强方法,该方法在图像、文本、语音、推荐、GAN、对抗样本防御等多个领域都能显著提高效果。mixup论文被ICLR2018收录,后续又出现了一系列改进方法。本文详细分析、讨论mixup,并介绍几种典型的改进方法。
一. mixup
原论文(ICLR2018收录):
https://arxiv.org/abs/1710.09412
源码(698星):
GitHub – facebookresearch/mixup-cifar10: mixup: Beyond Empirical Risk Minimization
1. mixup方法
mixup对两个样本-标签数据对按比例相加后生成新的样本-标签数据,这里
,
。
,其中x为输入向量
, 其中y为标签的one-hot编码
是概率值,
,即
服从参数都为
的Beta分布。
核心代码如下,即插即用:
criterion = nn.CrossEntropyLoss()
for x, y in train_loader:
x, y = x.cuda(), y.cuda()
# Mixup inputs.
lam = np.random.beta(alpha, alpha)
index = torch.randperm(x.size(0)).cuda()
mixed_x = lam * x + (1 - lam) * x[index, :]
# Mixup loss.
pred = model(mixed_x)
loss = lam * criterion(pred, y) + (1 - lam) * criterion(pred, y[index])
optimizer.zero_grad()
loss.backward()
optimizer.step()
代码中并没有直接按照公式计算新的标签
,而是把损失函数也修改成了线性组合的形式。可以自行推导一下,对于交叉熵损失CE,这种方法和计算
之后再计算一个单独的损失函数是等效的。而这种写法可以直接使用torch.nn.CrossEntropyLoss()(因为它仅支持整数型的y),所以非常方便。
2. mixup的讨论
2.1 mixup效果如何
原文实验数据:
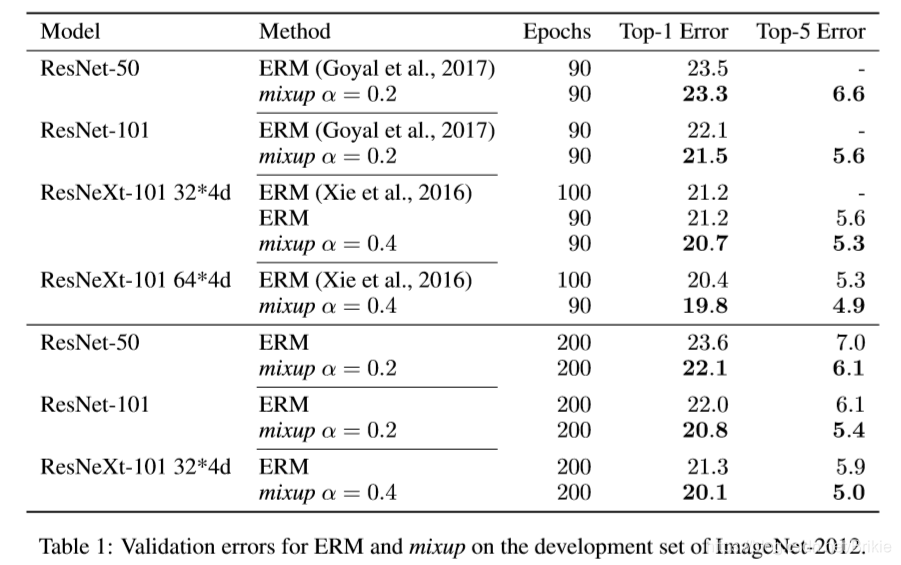
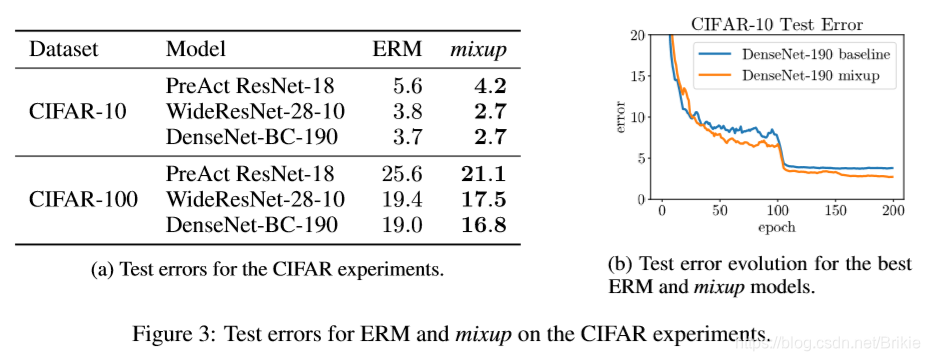
从原文试验结果中可以看出,mixup在ImageNet-2012上面经过200 epoch后在几个网络上提高了1.2 ~ 1.5个百分点。在CIFAR-10上提高1.0 ~ 1.4个百分点,在CIFAR-100上提高1.9 ~ 4.5个百分点。可以说是非常惊艳的。
作者继续试验了在语音数据、表格数据和GAN上也都有不错的效果。
作者还发现mixup不仅具有好的泛化性能,也具有很好的鲁棒性,无论对于含噪声标签的数据还是对抗样本攻击,都表现出不错的鲁棒性。
2.2 为什么使用Beta分布
使用Beta分布在数学上不是必须的,只是它比较零活方便。Beta分布有两个参数α和β,我们看图1中的α和β相同时的Beta分布概率密度曲线:
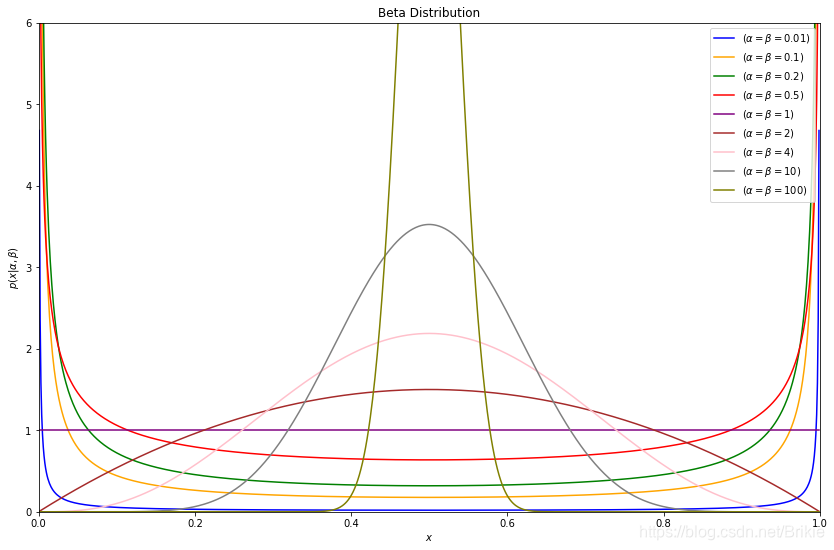
从图1中可以看出,当α = β = 1时,等于(0,1)均匀分布;当α = β < 1时,表现为两头的概率大,中间的概率小,当α = β → 0时,相当于{0,1}二项分布,要么取0,要么取1,等于原始数据没有增强,也就是论文中所说的
经验风险最小化ERM
;当α = β > 1时,表现为两头概率小,中间概率大,类似正态分布,当α = β → ∞时,概率恒等于0.5,相当于两个样本各取一半。所以使用Beta分布相当灵活,只需要调整参数α , β的值,就可以得到多样化的[0,1]区间内的概率分布,使用非常方便。
用PreActResNet18在CIFAR-10上进行了几种分布的对比试验,试验共训练200 epoch,学习率lr=0.1, 100 epoch和150 epoch时分别缩减到1/10,momentum=0.9, weight_decay=1e-4。本文以下所有试验参数配置相同。
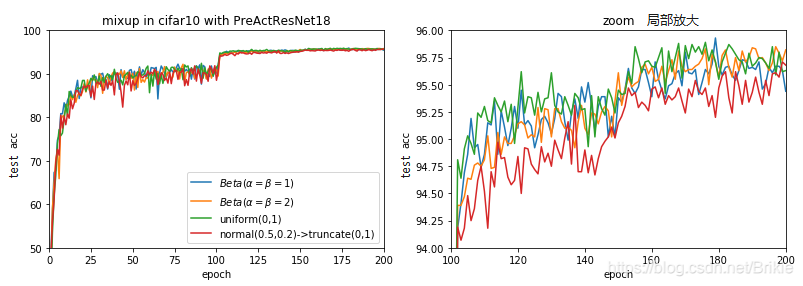
从图2中也可以看出,使用均匀分布或者正态分布和使用Beta分布相应参数的效果基本差不多。注意其中正态分布经过了truncate到(0,1)区间,这样会有一些样本等于是直接用了原始样本而没有进行mixup,所以效果会比其他几条线稍稍差一些。
2.3 参数

有何影响,如何选择
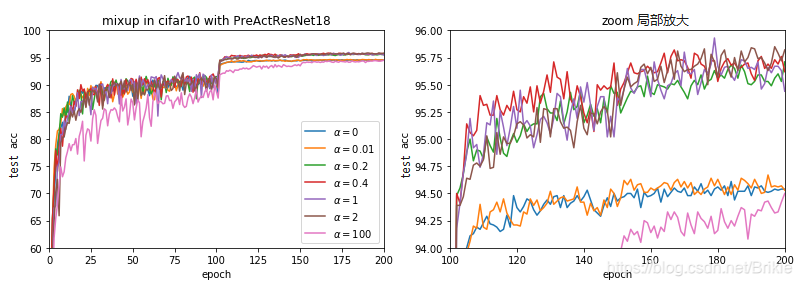
其中α = 0意味着不使用mixup,就是论文中说的ERM方法。
可以看出,α 在0.2 ~ 2之间效果都差不多,说明mixup对α参数并不是很敏感。但如果α过小,等于没有进行mixup的原始数据,如果α过大,等于所有输入都是各取一半混合,样本的多样性和没有增强的原始数据是一样的,但由于标签不直接,所以学习会慢一些,但最终精度和原始数据差不多。
限于资源,没有进行ImageNet上的试验,作者指出ImageNet上α在0.2 ~ 0.4之间效果更好,这可能意味着ImageNet上数据已经够多,应更多的保留原始数据成分,适当少用一些混合,效果更好。所以在不同的数据集也有必要对α进行一定的调参。
还有一点需要指出,从图中可以看出,使用mixup以后训练抖动会大一些,也就是说训练没有原来稳定。
2.4 是否可以使用多个样本混合
文中给出的方法使用了两个样本进行混合,我们自然会想到使用更多的样本混合效果会更好吗?也就是说:
,
,其中
使用狄利克雷分布可以方便的实现这个公式,在CIFAR10中进行了试验,结果如下图,N=2时等同于Beta分布,效果最好,N越大效果越差,N≤4效果仍能比原始数据稍好,N>5时效果还不如原始数据。什么原因还没有想明白。论文中提到作者也考虑了狄利克雷分布,但计算比较耗时且没有更好的效果。我不知道作者所指是否和我相同,我的试验中速度并没有比Beta分布变慢(即使N=10)。
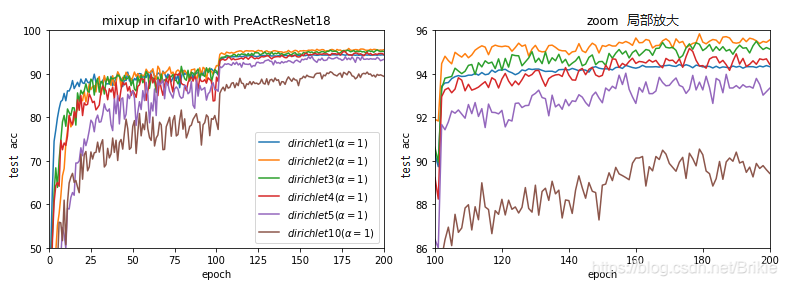
(图中dirichletN表示对N张图混合,N=1时相当于原始数据,N=2时相当于Beta分布)
2.5 为什么要使用凸组合
凸组合(convex combination)是指线性组合中各项系数之和为1。当然我们直觉上也能想象使用凸组合得到的新样本在数值上是和原样本持平的,应该会好。但效果怎样还是来试一试:
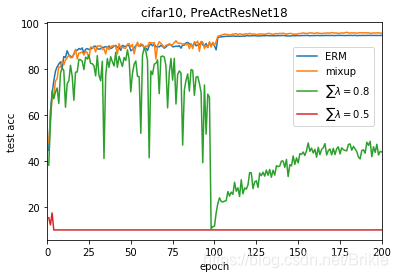
结果发现,∑ λ小于1时效果变差很多。
二. mixup的改进
1.多种改进方法简介
mixup方法成功挖了一个新坑,迅速涌现了大批改进和应用,我收集了部分方法改进性的论文进行介绍。除了这些改进性方法外,还有很多mixup
理论分析
及交叉应用的论文,比如mixUp
应用于GAN
,应用于对抗攻击防御,
应用于标签降噪
等,感兴趣的可自行阅读。
1.1 cutMix
论文(ICCV2019): https://arxiv.org/abs/1905.04899v2
代码(739星): https://github.com/clovaai/CutMix-PyTorch
cutMix方法另辟蹊径,不从数值角度对两个样本插值,而是从图像的空间角度考虑,把一张图片上的某个随机矩形区域剪裁到另一张图片上生成新图片。标签的处理和mixUp是一样的,都是按照新样本中两个原样本的比例确定新的混合标签的比例。这种新的处理更适合图像中信息连续性这个特点,所以作者试验认为效果比mixup更好。方法示意图见1.4节PuzzleMix插图。
1.2 manifold mixup
论文(ICML2019): https://arxiv.org/abs/1806.05236
代码(310星): https://github.com/vikasverma1077/manifold_mixup
manifold mixup对mixup进行扩展,把输入数据(raw input data)混合扩展到对中间隐层输出混合。至于对中间隐层混合更有效的原因,作者强行解释了一波。首先给出了现象级的解释,即这种混合带来了三个优势:平滑决策边界、拉大低置信空间(拉开各类别高置信空间的间距)、展平隐层输出的数值。至于这三点为什么有效,从作者说法看这应该是一种业界共识。然后作者又从数学上分析了第三点,即为什么manifold mixup可以实现展平中间隐层输出。总之这篇论文的理论解释部分比较深奥,毕竟作者有Yoshua Bengio大神。
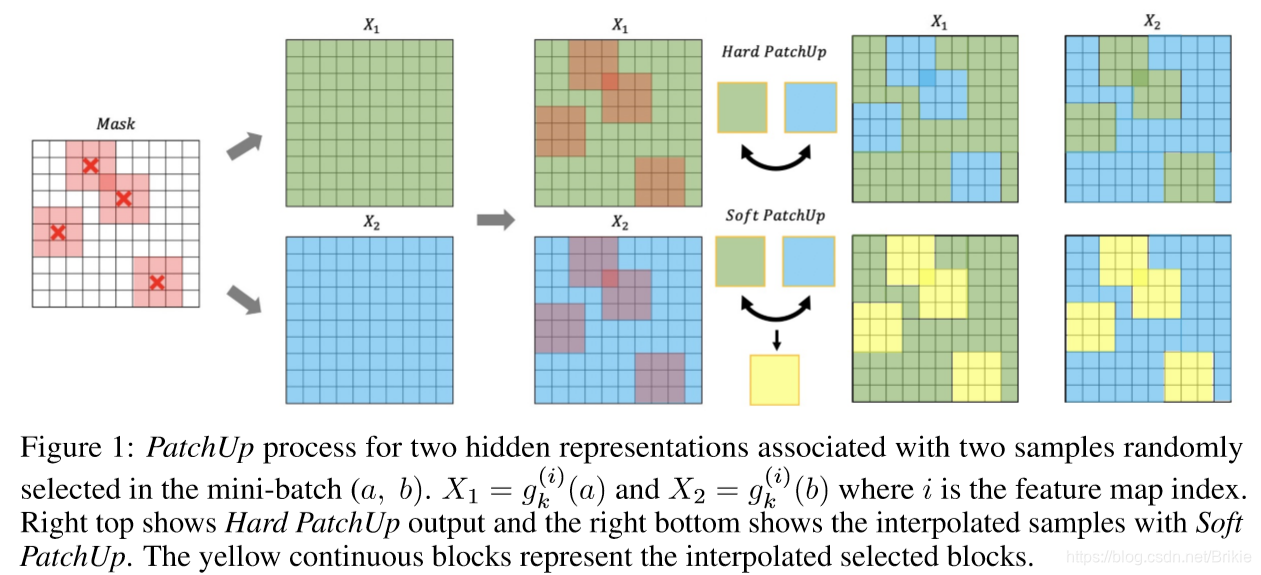
1.3 patchUp
论文(2020-6-14): https://arxiv.org/abs/2006.07794
代码(12星): https://github.com/chandar-lab/PatchUp
这个也是Bengio组出品。PatchUp方法在manifold mixup基础上,又借鉴了cutMix在空间维度剪裁的思路,对中间隐层输出也进行剪裁,对两个不同样本的中间隐层剪裁块进行互换或插值,文中称互换法为硬patchUp,插值法为软patchUp。试验发现互换法在识别精度上更好,插值法在对抗攻击的鲁棒性上更好。这篇论文作者没有再进行深度解释,仅仅给出了一个现象级对比,就是patchUp方法的隐层激活值比较高。
manifold和patchUp的官方开源代码都是对网络本身代码进行了修改,不能即插即用到其他网络中,实现的一份即插即用版,链接见文末。
1.4 puzzleMix
论文(ICML2020, 2020-9-15) https://arxiv.org/abs/2009.06962
代码(60星): https://github.com/snu-mllab/PuzzleMix
puzzleMix在cutMix基础上加入了显著性分析。因为cutMix合成的图片可能剪裁块正好来自于源图片的非重要区域或者正好把目标图片的重要区域遮挡,这明显和生成的标签不符。因此puzzle Mix首先计算各样本的显著性区域,仅剪裁显著性区域,又进一步加入了一些复杂精细的优化操作,从试验数据看效果很不错。

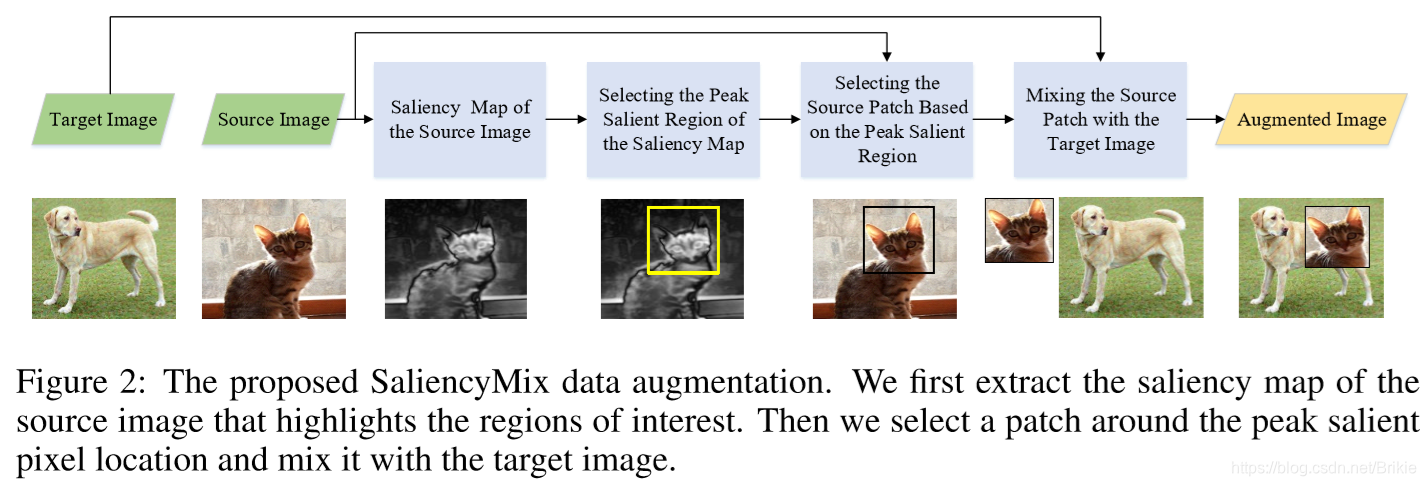
1.5 saliency Mix
论文(ICLR2021,2020-6-2):https://arxiv.org/abs/2006.01791
代码(0星):https://github.com/SaliencyMix/SaliencyMix
saliency Mix也是在cutMix基础上加入了显著性分析,但没有更多的优化操作措施,效果似乎不如puzzleMix。
1.6 fMix
论文(ICLR2021,2020-6-24):https://arxiv.org/abs/2002.12047
代码(249星):https://github.com/ecs-vlc/FMix
fMix在cutMix基础上改进,把剪裁区域从矩形转换为不规则形状,这样增加了数据样本空间规模。作者还先对图像进行傅里叶变换来提取低频分量(?)。除了在几个常用图像数据集上进行试验外,作者还把方法应用了情感分类这种一维数据上。但作者没有对方法为什么有效进行深入的理论分析。这篇论文以临界得分被ICLR2021录用。

1.7 co-Mix
论文(ICLR2021 oral, 2021-2-5): https://arxiv.org/abs/2102.03065
代码(27星): https://github.com/snu-mllab/Co-Mixup
co-Mix方法在剪裁+显著性的基础上继续改进,把从两个样本混合变成从多个样本中提取显著性区域并混合。该文使用显著性测度对显著性进行量化,并引入超模-子模分析方法,设计了一个子模最小化算法来实现在生成图片中尽可能多的累积显著性区域。这样生成的图片能够保证最大的显著性测度,同时还保持标签的多样性。该文是ICLR2021的oral,提出的理论方法确实比较深奥和高档。但综合多个文献的试验数据看,该方法的效果似乎还不如puzzleMix。

2.改进方法对比

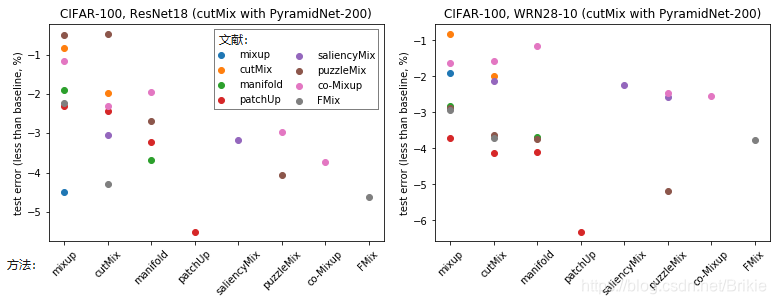
图6中给出了Mixup系列(不完全收录)发展过程。每篇论文都会宣称自己是SOTA,但是由于每篇论文中使用的模型的参数、训练超参等不可能完全相同,所以直接根据某一篇论文中给出的数据对比它们的性能并不准确和公平,下面我把各论文在cifar-100中试验结果整理出来,我们可以通过交叉分析多个文献的数据综合对比它们的效果。
| 方法/文献 | mixup | cutMix | manifold | patchUp | saliencyMix | puzzleMix | co-Mixup |
FMix |
|---|---|---|---|---|---|---|---|---|
|
baseline |
25.6 | 16.45 | 24.01 | 24.622 | 22.46 | 23.67 | 23.59 | 24.78 |
| mixup | 21.1 | 15.63 | 22.11 | 22.326 | – | 23.16 | 22.43 | 22.56 |
| cutMix | – | 14.47 | – | 22.184 | 19.42 | 23.20 | 21.29 | 20.49 |
| manifold | – | – | 20.34 | 21.396 | – | 20.98 | 21.64 | – |
| patchUp | – | – | – | 19.120 | – | – | – | – |
| saliencyMix | – | – | – | – | 19.29 | – | – | – |
| puzzleMix | – | – | – | – | – | 19.62 | 20.62 | – |
| co-Mixup | – | – | – | – | – | – | 19.87 | – |
| FMix | – | – | – | – | – | – | – | 20.15 |
| 方法/文献 | mixup | cutMix | manifold | patchUp | saliencyMix | puzzleMix | co-Mixup |
FMix |
|---|---|---|---|---|---|---|---|---|
|
baseline |
19.4 | 16.45 | 21.72 | 22.442 | 18.80 | 21.14 | 21.70 | 21.74 |
| mixup | 17.5 | 15.63 | 18.89 | 18.726 | – | 18.27 | 20.08 | 18.81 |
| cutMix | – | 14.47 | – | 18.316 | 16.66 | 17.50 | 20.14 | 18.04 |
| manifold | – | – | 18.04 | 18.352 | – | 17.40 | 20.55 | – |
| patchUp | – | – | – | 16.134 | – | – | – | – |
| saliencyMix | – | – | – | – | 16.56 | – | – | – |
| puzzleMix | – | – | – | – | 16.23 | 15.95 | 19.24 | – |
| co-Mixup | – | – | – | – | – | – | 19.15 | – |
| FMix | – | – | – | – | – | – | – | 17.97 |
一些结论:
1,几乎所有人都测出来自己误差最小(与自己前的文献对比),而很多情况下别人测出来的结果却未必;
2,综合各种因素看,感觉效果最好的应该是patchUp > puzzleMix > 其他;
3,虽然随着时间发展模型精度越来越高,但程序也越来越复杂。mixup原方法可以很方便的使用在CNN、RNN、GAN等各种场合,但使用剪裁的cutMix及后续方法似乎都只能用在CNN场合。而涉及到隐层修改的manifold和patchUp还需要修改网络本身各层的写法,官方开源代码不能够即插即用。
想到在pytorch中使用钩子操作(hook)可以修改中间层,因此见一份可以即插即用的manifold和patchUp,请参见另一篇博客:https://blog.csdn.net/Brikie/article/details/114222605