问题是这样的
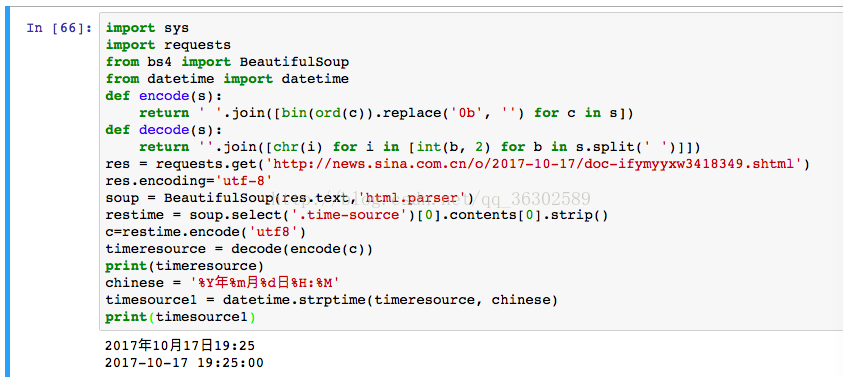
我用的jupyter,下图是我的源代码我知道由于未把ASCII转为utf8,但是我按照网上的代码修改后直接没有output了
我加上
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8’)
还是没反应

百度了好久,有人提供了个解决方案是这样的,因为按代码逻辑没有问题,首先requests 得到的结果已经用utf-8来进行编码了,但是beautifulSoup函数再次将目标用utf-8再次进行强转,导致了如下的情况:
'''我们想要使用的字符串'''
target_str
=
'2017\xe5\xb9\xb402\xe6\x9c\x8816\xe6\x97\xa512:53'
'''两次转码后的字符串'''
get_str
=
u
'2017\xe5\xb9\xb402\xe6\x9c\x8816\xe6\x97\xa512:53'
归根结底是两个对象的类不同,但python不支持这两种类型的强转,个人想了个比较临时的解决方案,算是个python打了个补丁,就是将字符串转成二进制,再转回字符串,这样就unicode就不用给他加上编码方式再转成二进制字符串了,加了如下两个函数:
def
encode(s):
'''将字符串转成二进制'''
return
' '
.join([
bin
(
ord
(c)).replace(
'0b'
, '')
for
c
in
s])
def
decode(s):
'''将二进制转换成字符串'''
return
'
'.join([chr(i) for i in [int(b, 2) for b in s.split('
')]])
修改后的代码如下,但还是报错了如图:
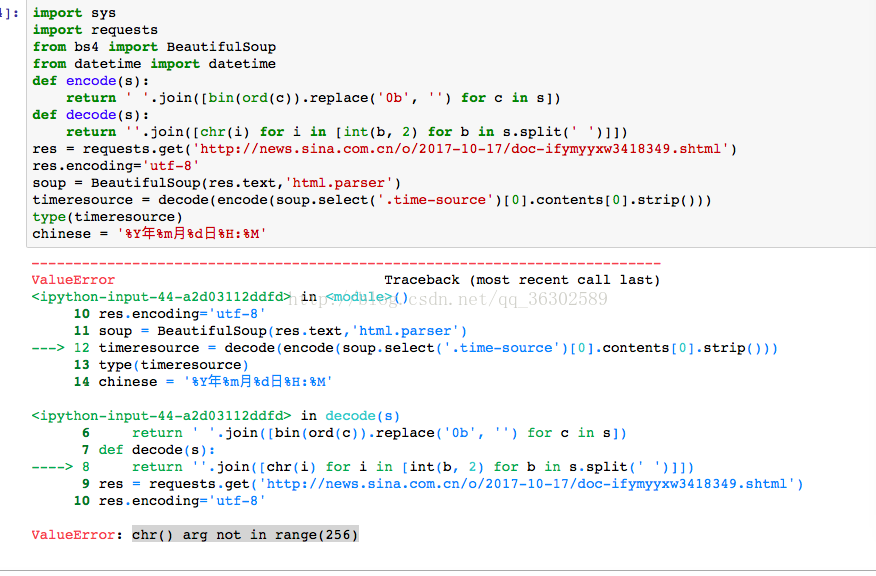
一看错误类型就是典型的类型错误咯,多次测验我发现了一个问题
timeresource的类型是 unicode! 导致解码的时候出了类型格式错误,就更不用说后面继续调用strptime函数了,所以首先要做的是把timeresource转换成str,
参考一篇博客
Python2x中Str&Unicode
接下来我们来讨论Python2x中的Str和Unicode。
首先我打开Python2.7的编译环境。输入以下代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
可以看到在Python2.7shell中,我们输入”中文“这两个中文字符时,用了解释器的默认编码格式,在windows下即为GBK,所以我们看到的是上面第一个图中的十六进制表达。可以看到此时a的类型是str。
当我们对str类型的a用”gbk“解码后赋给变量b,可以b的类型是unicode,十六进制的表达式类似上面第二个图。
但是我们用ASCII编码去解码却得到DecodeError的结果。
所以我们得到一个结论:
[str].decode(str对应的编码)=[unicode],并且用什么码编码就用什么码解码。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们可以看到对unicode类型的变量b用utf8编码后变成了str类型的c,它的底层十六进制表达如上面的第三张图。
当我们print c的时候就打印出来乱码了,原因是此时的str变量c用的是utf8编码,但是解释器的编码是gbk,相当于用gbk的编码方式去解释用utf8编码的字符串,自然打印出来的是乱码。(而且,上面说过gbk是两个字节表示一个中文字符,utf8是三个字节表示一个中文字符,所以打印出来是三个乱码的字符)
所以我们得到另一个结论:
[unicode].encode(你想要的编码方式)=[str],解释器编码方式要与字符串的编码方式一样才能解出正确的字符。
所以修改后的程序如下: