结构
概述
工具类 就是封装平常用的方法,不需要你重复造轮子,节省开发人员时间,提高工作效率。谷歌作为大公司,当然会从日常的工作中提取中很多高效率的方法出来。所以就诞生了guava。
guava的优点
高效设计良好的API,被Google的开发者设计,实现和使用
遵循高效的java语法实践
使代码更刻度,简洁,简单
节约时间,资源,提高生产力
guava的核心库
集合 [collections]
缓存 [caching]
原生类型支持 [primitives support]
并发库 [concurrency libraries]
通用注解 [common annotations]
字符串处理 [string processing]
I/O
引入
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>
使用
集合
集合创建
各种以S结尾的工厂类简化了集合的创建。在创建泛型实例的时候,它们使代码更加简洁
//java 7 中
Map<String,List<String>> m=new HashMap<>();
// java 8 普通Collection的创建
List<String> list = Lists.newArrayList("a","b","c");
Set<String> set = Sets.newHashSet();
Map<String, String> map = Maps.newHashMap();
// 不变Collection的创建
ImmutableList<String> iList = ImmutableList.of("a", "b", "c");
ImmutableSet<String> iSet = ImmutableSet.of("e1", "e2");
ImmutableMap<String, String> iMap = ImmutableMap.of("k1", "v1", "k2", "v2");
创建不可变集合 先理解什么是
immutable(不可变)对象
在 多线程操作 下,是 线程安全的
所有不可变集合 会比 可变集合 更有效的利用资源
中途不可改变
ImmutableList<String> immutableList = ImmutableList.of("1","2","3","4");
// add 方法
@Deprecated @Override
public final void add(int index, E element) {
throw new UnsupportedOperationException();
}
这声明了一个
不可变的List集合
,List中有数据
1,2,3,4
。类中的 操作集合的方法(譬如
add, set, sort, replace
等)都被声明过期,并且抛出异常。 而
没用guava之前是需要声明并且加各种包裹集合才能实现这个功能
集合转换、查找、过滤、分割
将一个集合转换成另外一种类型的集合
Lists.transform()
List<String> listStr = Lists.newArrayList("1", "2", "3");
//将字符串集合转换为Integer集合
List<Integer> listInteger = Lists.transform(listStr, new Function<String, Integer>() {
@Nullable
@Override
public Integer apply(@Nullable String s) {
return Integer.valueOf(s);
}
});
ImmutableMap<String, Integer> m = ImmutableMap.of("begin", 12, "code", 15);
//Function<F, T> F表示apply()方法input的类型,T表示apply()方法返回类型
Map<String, Integer> m2 = Maps.transformValues(m, input -> {
if(input > 12){
return input;
}else{
return input + 1;
}
});
System.out.println(m2);
//{begin=13, code=15}
//java 8 中
List<Integer> listInteger2 = listStr.stream().map(Integer::valueOf).collect(Collectors.toList());
查找集合首个匹配的元素
List<String> listStr = Lists.newArrayList("hello", "world", "hehe");
//查找首个以h开头的值
String value = Iterables.find(listStr, new Predicate<String>() {
@Override
public boolean apply(String input) {
return input.startsWith("h");
}
});
//java 8
String value2 = listStr.stream().findFirst().filter(input -> input.startsWith("h")).get();
过滤集合中所有符合特定条件的元素
List<String> listWithH = Lists.newArrayList(Collections2.filter(listStr, new Predicate<String>() {
@Override
public boolean apply(@Nullable String s) {
return s.startsWith("h");
}
}));
//按照条件过滤
ImmutableList<String> names = ImmutableList.of("begin", "code", "Guava", "Java");
Iterable<String> fitered = Iterables.filter(names, Predicates.or(Predicates.equalTo("Guava"), Predicates.equalTo("Java")));
//java 8
List<String> listWithH2 = listStr.stream().filter(input -> input.startsWith("h")).collect(Collectors.toList());
将一个大的集合分割成小集合,适用于分批查询、插入等场景
List<String> listStr = Lists.newArrayList("1", "2", "3","4","5","6","7");
List<List<String>> batchList = Lists.partition(listStr,3);
//被分割成了: [[1, 2, 3], [4, 5, 6], [7]]
分组
Maps.uniqueIndex 根据集合中的唯一键把集合转换为以唯一键为key,以元素为value的Map
Multimaps.index 根据集合中的相同的值把集合转换为以相同值为key,以List<元素>为value的Map. 相当于一键多值Map
class Apple {
int id;
String color;
public Apple(int id, String color) {
this.id = id;
this.color = color;
}
public int getId() {
return id;
}
public String getColor() {
return color;
}
@Override
public String toString() {
return MoreObjects.toStringHelper(Apple.class).add("id", id).add("color", color).toString();
}
}
@Test
public void test1() {
List<Apple> appleList = Lists.newArrayList(new Apple(1, "red"), new Apple(2, "red"), new Apple(3, "green"), new Apple(4, "green"));
// 以主键为key,生成键值对:Map<id,Apple>
Map<Integer, Apple> appleMap = Maps.uniqueIndex(appleList, new Function<Apple, Integer>() {
@Nullable
@Override
public Integer apply(@Nullable Apple apple) {
return apple.getId();
}
});
// 相当于根据颜色分类:转为Map<颜色,Collection<Apple>>
Multimap<String, Apple> multiMap = Multimaps.index(appleList,
new Function<Apple, String>() {
@Nullable
@Override
public String apply(@Nullable Apple apple) {
return apple.getColor();
}
});
}
List<Apple> appleList = Lists.newArrayList(new Apple(1, "red"), new Apple(2, "red"), new Apple(3, "green"), new Apple(4, "green"));
Map<Integer, Apple> appleMap = appleList.stream().collect(Collectors.toMap(Apple::getId, apple -> apple));
Map<String, List<Apple>> groupsByColor = appleList.stream().collect(Collectors.groupingBy(Apple::getColor));
集合运算工具类
Sets
集合差
// s1 - s2
Set<String> s1 = Sets.newHashSet("1", "2", "3", "4");
Set<String> s2 = Sets.newHashSet("2", "3", "4", "5");
// 得到第一个集合中有而第二个集合没有的字符串
Sets.SetView res = Sets.difference(s1, s2);
for(Iterator<String> it = res.iterator(); it.hasNext();){
System.out.println(it.next()); // 1
}
集合对称差
Sets.SetView res2 = Sets.symmetricDifference(s1, s2);
for(Object it14 : res2){
System.out.println(it14); // 1 5
}
集合交
// s1和s2的交集
Sets.SetView<String> res3 = Sets.intersection(s1, s2);
for(String it14 : res3){
System.out.println(it14); // 2 3 4
}
集合并
// 合并s1和s2
Sets.SetView<String> res4 = Sets.union(s1, s2);
for(String it14 : res4){
System.out.println(it14); // 1 2 3 4 5
}
Map
MapDifference differenceMap = Maps.difference(mapA, mapB);
differenceMap.areEqual();
Map entriesDiffering = differenceMap.entriesDiffering();
Map entriesOnlyLeft = differenceMap.entriesOnlyOnLeft();
Map entriesOnlyRight = differenceMap.entriesOnlyOnRight();
Map entriesInCommon = differenceMap.entriesInCommon();
System.out.println(entriesDiffering); // {b=(2, 20)}
System.out.println(entriesOnlyLeft); // {a=1}
System.out.println(entriesOnlyRight); // {d=4}
System.out.println(entriesInCommon); // {c=3}
对JDK集合的有效补充
MultiSet: 无序+可重复 count()方法获取单词的次数 增强了可读性+操作简单
创建方式: Multiset<String> set = HashMultiset.create();
Multimap: key-value key可以重复
创建方式: Multimap<String, String> teachers = ArrayListMultimap.create();
BiMap: 双向Map(Bidirectional Map) 键与值都不能重复
创建方式: BiMap<String, String> biMap = HashBiMap.create();
Table: 双键的Map Map--> Table-->rowKey+columnKey+value //和sql中的联合主键有点像
创建方式: Table<String, String, Integer> tables = HashBasedTable.create();
...等等(guava中还有很多java里面没有给出的集合类型)
灰色地带:Multiset
JDK
的集合,提供了
有序且可以重复的List
,
无序且不可以重复的Set
。那这里其实对于集合涉及到了2个概念,一个order,一个dups。那么List vs Set,and then some ?
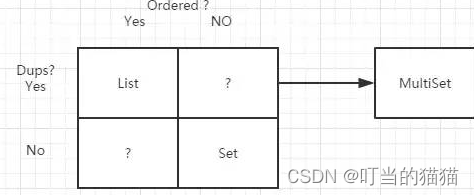
Multiset就是无序的,但是可以重复的集合,它就是游离在List/Set之间的“灰色地带”!
import com.google.common.collect.HashMultiset;
import com.google.common.collect.Multiset;
注意 区分下面
import org.apache.commons.collections4.MultiSet;
import com.google.common.collect.Multiset;
Multiset<String> set = HashMultiset.create();
set.add("a");
set.add("b");
set.add("c");
System.out.println(set.size());
System.out.println(set.count("a")); //Multiset自带一个有用的功能,就是可以跟踪每个对象的数量
Immutable vs unmodifiable
JDK
提供的
Collections.unmodifiableXxx
所
返回的集合和源集合
是
同一个对象
,只不过可以
对集合做出改变的API都被override
,会
抛出UnsupportedOperationException
也就是说
改变源集合,导致不可变视图(unmodifiable View)也会发生变化
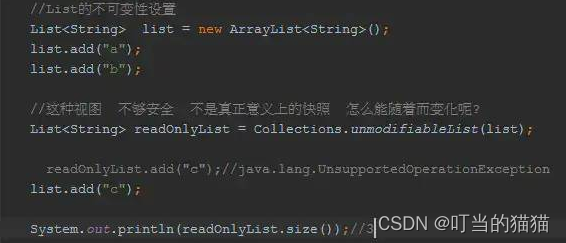
不使用guava的情况下避免上面的问题
// 下面 揭示了一个概念:Defensive Copies,保护性拷贝
ArrayList<Object> list = Lists.newArrayList("a","b");
List<Object> objects = Collections.unmodifiableList(new ArrayList<>(list));
// objects.add("a"); //throw java.lang.UnsupportedOperationException
list.add("c");
System.out.println(list); //a b c
使用
guava 的 Immutable
guava提供了很多Immutable集合,比如
ImmutableList/ImmutableSet/ImmutableSortedSet/ImmutableMap/......
ImmutableList<String> list = ImmutableList.of("a", "b", "c");
list.add("c"); //throw java.lang.UnsupportedOperationException
ImmutableList<String> immutableList = ImmutableList.copyOf(list);
immutableList.add("c"); //视图不随着源而改变,guava 设置了只读
System.out.println(list.size() + "\n" + immutableList.size());
ImmutableMap
ImmutableMap<String, String> map = ImmutableMap.of("name", "zhangsan", "sex", "man");
map.put("wife","no") //throw java.lang.UnsupportedOperationException
可不可以一对多:Multimap
JDK
提供的
Map是一个键,一个值,一对一的
,那么在实际开发中,显然存在
一个KEY多个VALUE
的情况
(比如一个分类下的书本)
,我们往往这样表达:
Map<k,List<v>>
,好像有点臃肿!臃肿也就算了,更加不爽的事,我们
还得判断KEY是否存在来决定是否new 一个LIST出来
,有点麻烦!更加麻烦的事情还在后头,比如遍历,比如删除,so hard…
ArrayListMultimap<Object, Object> multimap = ArrayListMultimap.create();
multimap.put("name","zhangsan");
multimap.put("name","lisi");
multimap.put("age","12");
System.out.println(multimap.get("name"));
guava所有的集合都有create方法,这样的好处在于简单,而且我们不必在重复泛型信息了。
get()/keys()/keySet()/values()/entries()/asMap()都是非常有用的返回view collection的方法。
Multimap的实现类有:
ArrayListMultimap/HashMultimap/LinkedHashMultimap/TreeMultimap/ImmutableMultimap/....
// 用ArrayList保存,一键多值,值不会被覆盖
ArrayListMultimap<String, String> multimap = ArrayListMultimap.create();
multimap.put("foo", "1");
multimap.put("foo", "2");
multimap.put("foo", "3");
multimap.put("bar", "a");
multimap.put("bar", "a");
multimap.put("bar", "b");
for(String it20 : multimap.keySet()){
// 返回类型List<String>
System.out.println(it20 + " : " + multimap.get(it20));
}
// 返回所有ArrayList的元素个数的和
System.out.println(multimap.size());
//结果
bar : [a, a, b]
foo : [1, 2, 3]
6
//这里采用HashTable保存
HashMultimap<String, String> hashMultimap = HashMultimap.create();
hashMultimap.put("foo", "1");
hashMultimap.put("foo", "2");
hashMultimap.put("foo", "3");
// 重复的键值对值保留一个
hashMultimap.put("bar", "a");
hashMultimap.put("bar", "a");
hashMultimap.put("bar", "b");
for(String it20 : hashMultimap.keySet()){
// 返回类型List<String>
System.out.println(it20 + " : " + hashMultimap.get(it20));
}
// 5
System.out.println(hashMultimap.size());
//结果
bar : [a, b]
foo : [1, 2, 3]
5
可不可以双向:BiMap
JDK
提供的MAP让我们可以
find value by key
,那么能不能通过
find key by value
呢,能不能
KEY和VALUE都是唯一的呢
。这是一个
双向的概念
,即
forward+backward
在实际场景中有这样的需求吗?比如
通过用户ID找到mail
,
也需要通过mail找回用户名
。没有guava的时候,我们需要
create forward map
AND
create backward map
,and now just let guava do that for you.
HashBiMap<Object, Object> bimap = HashBiMap.create();
bimap.put("name","zhangsan");
//bimap.put("student","zhangsan"); //value 相同也会报错 java.lang.IllegalArgumentException: value already present: zhangsan
bimap.put("name","lisi"); //覆盖
bimap.forcePut("student","zhangsan"); // 强制覆盖
bimap.forcePut("age","12");
System.out.println(bimap.inverse().get("zhangsan"));
biMap / biMap.inverse() / biMap.inverse().inverse() 它们是什么关系呢?
你可以稍微看一下BiMap的源码实现,实际上,当你创建BiMap的时候,在内部维护了2个map,一个forward map,一个backward map,并且设置了它们之间的关系。
因此,biMap.inverse() != biMap ;biMap.inverse().inverse() == biMap
可不可以多个KEY:Table
数据库除了主键外,还提供了
复合索引
,而且实际中这样的
多级关系查找
也是比较多的,当然我们可以利用
嵌套的Map来实现:Map<k1,Map<k2,v2>>
。为了让我们的代码看起来不那么丑陋,guava为我们提供了Table。
rowKey,columnKey,value
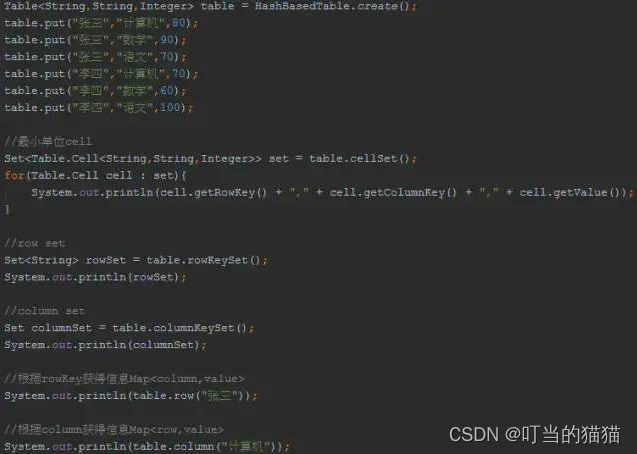
// 两个键row key和column key,其实就是map中map, map<Integer, map<Integer, String> > mp
HashBasedTable<Integer, Integer, String> table = HashBasedTable.create();
table.put(1, 1, "book");
table.put(1, 2, "turkey");
table.put(2, 2, "apple");
System.out.println(table.get(1, 1)); // book
System.out.println(table.contains(2, 3)); // false
System.out.println(table.containsRow(2)); // true
table.remove(2, 2);
System.out.println(table.get(2, 2)); // null
// 获取单独的一个map
Map<Integer, String> row = table.row(1);
Map<Integer, String> column = table.column(2);
System.out.println(row.get(1)); // book
System.out.println(column.get(1)); // turkey
不可变集合类ImmutableListMultimap
// 不可变的集合,都有一个Builder内部类。不可以修改和添加
Multimap<Integer, String> map = new ImmutableListMultimap.Builder<Integer, String>().put(1, "hello")
.putAll(2, "abc", "log", "in").putAll(3, "get", "up").build();
System.out.println(map.get(2)); // [abc, log, in]
字符串
拼接 Joiner
Joiner
可以快速地
把多个字符串或字符串数组连接成为用特殊符号连接的字符串
List<String> list = Lists.newArrayList("a","b","c");
String value =Joiner.on("-").skipNulls().join(list);
System.out.println(value);
//输出为: a-b-c
joiner.appendTo()
按照
Joiner 规则
追加
StringBuilder stringBuilder = new StringBuilder("hello");
// 字符串连接器,以|为分隔符,同时去掉null元素
Joiner joiner1 = Joiner.on("|").skipNulls();
// 构成一个字符串foo|bar|baz并添加到stringBuilder
stringBuilder = joiner1.appendTo(stringBuilder, "foo", "bar", null, "baz");
System.out.println(stringBuilder); // hellofoo|bar|baz
把map集合转换为特定规则的字符串
Map<String, Integer> map = Maps.newHashMap();
map.put("xiaoming", 12);
map.put("xiaohong",13);
String result = Joiner.on(",").withKeyValueSeparator("=").join(map);
// result为 xiaoming=12,xiaohong=13
连接List元素并写到文件流
FileWriter fileWriter = null;
try{
fileWriter = new FileWriter(new File("/home/gzx/Documents/tmp.txt"));
} catch(Exception e){
System.out.println(e.getMessage());
}
List<Date> dateList = new ArrayList<Date>();
dateList.add(new Date());
dateList.add(null);
dateList.add(new Date());
// 构造连接器:如果有null元素,替换为no string
Joiner joiner2 = Joiner.on("#").useForNull("no string");
try{
// 将list的元素的tostring()写到fileWriter,是否覆盖取决于fileWriter的打开方式,默认是覆盖,若有true,则是追加
joiner2.appendTo(fileWriter, dateList);
// 必须添加close(),否则不会写文件
fileWriter.close();
} catch(IOException e){
System.out.println(e.getMessage());
}
分割 Splitter
Splitter
用来分割字符串
String testString = "Monday,Tuesday,,Thursday,Friday,,";
//英文分号分割;忽略空字符串
Splitter splitter = Splitter.on(",").omitEmptyStrings().trimResults();
System.out.println(splitter.split(testString).toString());
//转换为了:[Monday, Tuesday, Thursday, Friday]
将String转换为特定的集合
//use java
List<String> list = new ArrayList<String>();
String a = "1-2-3-4-5-6";
String[] strs = a.split("-");
for(int i=0; i<strs.length; i++){
list.add(strs[i]);
}
//use guava
String str = "1-2-3-4-5-6";
List<String> list = Splitter.on("-").splitToList(str);
//list为 [1, 2, 3, 4, 5, 6]
使用 omitEmptyStrings().trimResults() 去除空串与空格
String str = "1-2-3-4- 5- 6 ";
List<String> list = Splitter.on("-").omitEmptyStrings().trimResults().splitToList(str);
System.out.println(list);
将String转换为map
String str = "xiaoming=11,xiaohong=23";
Map<String,String> map = Splitter.on(",").withKeyValueSeparator("=").split(str);
特定的正则分隔
String input = "aa.dd,,ff,,.";
List<String> result = Splitter.onPattern("[.|,]").omitEmptyStrings().splitToList(input);
CharMatcher
匹配
CharMatcher
常用来
从字符串里面提取特定字符串
比如想
从字符串中得到所有的数字
String value = CharMatcher.DIGIT.retainFrom("some text 2046 and more");
//value=2046
替换
// 空白回车换行对应换成一个#,一对一换
String stringWithLinebreaks = "hello world\r\r\ryou are here\n\ntake it\t\t\teasy";
String s6 = CharMatcher.BREAKING_WHITESPACE.replaceFrom(stringWithLinebreaks,'#');
System.out.println(s6); // hello#world###you#are#here##take#it###easy
连续空白缩成一个字符
// 将所有连在一起的空白回车换行字符换成一个#,倒塌
String tabString = " hello \n\t\tworld you\r\nare here ";
String tabRet = CharMatcher.WHITESPACE.collapseFrom(tabString, '#');
System.out.println(tabRet); // #hello#world#you#are#here#
去掉前后空白和缩成一个字符
// 在前面的基础上去掉字符串的前后空白,并将空白换成一个#
String trimRet = CharMatcher.WHITESPACE.trimAndCollapseFrom(tabString, '#');
System.out.println(trimRet);// hello#world#you#are#here
inRange
// 判断匹配结果
boolean result = CharMatcher.inRange('a', 'z').or(CharMatcher.inRange('A', 'Z')).matches('K'); //true
// 保留数字文本 CharMatcher.digit() 已过时 retain 保留
//String s1 = CharMatcher.digit().retainFrom("abc 123 efg"); //123
String s1 = CharMatcher.inRange('0', '9').retainFrom("abc 123 efg"); // 123
// 删除数字文本 remove 删除
// String s2 = CharMatcher.digit().removeFrom("abc 123 efg"); //abc efg
String s2 = CharMatcher.inRange('0', '9').removeFrom("abc 123 efg"); // abc efg
Strings 工具类
System.out.println(Strings.isNullOrEmpty("")); // true
System.out.println(Strings.isNullOrEmpty(null)); // true
System.out.println(Strings.isNullOrEmpty("hello")); // false
// 将null转化为""
System.out.println(Strings.nullToEmpty(null)); // ""
// 从尾部不断补充T只到总共8个字符,如果源字符串已经达到或操作,则原样返回。类似的有padStart
System.out.println(Strings.padEnd("hello", 8, 'T')); // helloTTT
Function
利用Functions将Map转化为Function
Function
的功能是
将一个类型转化为另一个类型
Map<String, Person> mp = Maps.newHashMap();
mp.put(person1.getName(), person1);
mp.put(person2.getName(), person2);
mp.put(person3.getName(), person3);
mp.put(person4.getName(), person4);
// 将map转化为Function
Function<String, Person> lookup = Functions.forMap(mp);
// 如果键值不存在,则会抛出异常。lookup内部已经有元素
Person tmp = lookup.apply("Betty");
System.out.println(tmp == person3); // true
public void testConverte1() {
ArrayList<String> strings = Lists.newArrayList("helloworld", "deadtodead", "newbirth");
Function<String, String> function = new Function<String, String>() {
@Nullable
@Override
public String apply(@Nullable String s) {
return s.length()<=4 ? s : s.substring(0,4);
}
};
Function<String, String> function1 = new Function<String, String>() {
@Nullable
@Override
public String apply(@Nullable String s) {
return s.toUpperCase();
}
};
Function<String, String> compose = Functions.compose(function, function1);
Collection<String> transform = Collections2.transform(strings, compose);
transform.forEach(t-> System.out.println(t));
}
好处在于在
集合遍历操作中提供自定义Function的操作
,比如
transform转换
。我们再也不需要一遍遍的遍历集合,显著的简化了代码

断言 Predicate
Predicate
最常用的功能就是
运用在集合的过滤当中

//use java
if(list!=null && list.size()>0)
'''
if(str!=null && str.length()>0)
'''
if(str !=null && !str.isEmpty())
//use guava
if(!Strings.isNullOrEmpty(str))
//use java
if (count <= 0) {
throw new IllegalArgumentException("must be positive: " + count);
}
//use guava
Preconditions.checkArgument(count > 0, "must be positive: %s", count);
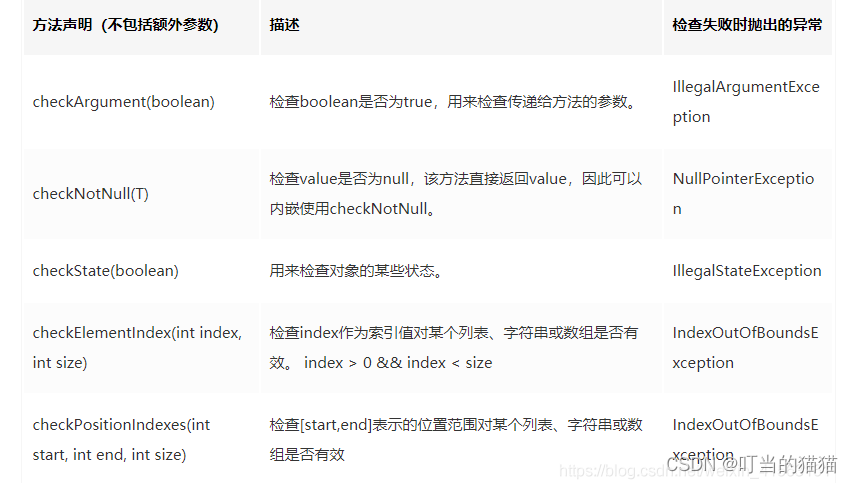

Predicate单个判断
Predicate<Person> agePre = new Predicate<Person>(){
@Override
public boolean apply(Person person) {
return person.getAge() < 32;
}
};
Predicate<Person> namePre = new Predicate<Person>(){
@Override
public boolean apply(Person person) {
return person.getName().equals("Betty");
}
};
// 判断是否符合条件
System.out.println(agePre.apply(person2)); // false
System.out.println(namePre.apply(person3)); // true
Predicates的and运算
// 利用Predicates工具类,同时满足两个条件成一个predicate
Predicate<Person> both = Predicates.and(agePre, namePre);
System.out.println(both.apply(person1)); // false
Predicates的or运算
//至少一个满足组成一个Predicate
Predicate<Person> orPre = Predicates.or(agePre, namePre);
System.out.println(orPre.apply(person2)); // false
Predicates的compose运算
// 通过键name获得值Person,然后检查Person的age < 32,即agepre.apply(lookup.apply(name)) == true?
// lookup内部已经有集合
Predicate<String> two = Predicates.compose(agePre, lookup);
System.out.println(two.apply("Wilma")); // true
文件操作 Files
写文件流
// 写文件流
File writeFile = new File("/home/gzx/Documents/write.txt");
try {
// 不必打开或关闭文件流,会自动写盘
Files.write("hello world!", writeFile, Charsets.UTF_8); // 重新写
Files.append("你的名字", writeFile, Charsets.UTF_8); // 追加
} catch (IOException e) {
e.printStackTrace();
}
读取文件流
以前写文件读取要定义缓冲区,各种条件判断,使用 guava 后就简单多了
File file = new File("test.txt");
List<String> list = null;
try {
list = Files.readLines(file, Charsets.UTF_8);
} catch (Exception e) {
}
读输入字节流ByteSource和写输出字节流ByteSink
// source是源的意思,封装输入流
ByteSource byteSource = Files.asByteSource(writeFile);
try {
byte[] contents1 = byteSource.read();
byte[] contents2 = Files.toByteArray(writeFile); // 两个方法的作用相同
for(int i = 0; i < contents1.length; i++){
assert(contents1[i] == contents2[i]);
System.out.print(contents1[i] + " ");
}
} catch (IOException e) {
e.printStackTrace();
}
// sink是目的地的意思,封装输出流,流会自动关闭
File tmpFile = new File("/home/gzx/Documents/hello.txt"); // acd
ByteSink byteSink = Files.asByteSink(tmpFile);
try {
byteSink.write(new byte[]{'a', 'c', 'd', '\n'});
} catch (IOException e) {
e.printStackTrace();
}
编码工具类BaseEncoding
FilepdfFile = new File("/home/gzx/Documents/google.pdf");
BaseEncoding baseEncoding = BaseEncoding.base64();
try {
byte[] content = Files.toByteArray(pdfFile);
String encoded = baseEncoding.encode(content); // 将不可打印的字符串转化为可以打印的字符串A-Za-z0-9/+=,pdf不是纯文本文件
System.out.println("encoded:\n" + encoded);
System.out.println(Pattern.matches("[A-Za-z0-9/+=]+", encoded));
// 获得对应的加密字符串,可以解密,可逆的,得到原来的字节
byte[] decoded = baseEncoding.decode(encoded);
for(int i = 0; i < content.length; i++){
assert(content[i] == decoded[i]);
}
} catch (IOException e) {
e.printStackTrace();
}
移动复制重命名删除等
// 文件操作:复制,移动,重命名
File originFile = new File("/home/gzx/Documents/Program/Java/abc.java");
File copyFile = new File("/home/gzx/Documents/test.java");
File mvFile = new File("/home/gzx/Documents/abc.java");
try {
Files.copy(originFile, copyFile); //复制文件
Files.move(copyFile, mvFile); // 重命名
}
catch(IOException e){
e.printStackTrace();
}
Files.deleteDirectoryContents(File directory); //删除文件夹下的内容(包括文件与子文件夹)
Files.deleteRecursively(File file); //删除文件或者文件夹
URL url = Resources.getResource("abc.xml"); //获取classpath根下的abc.xml文件url
...
获取文件哈希码
try {
// File,HashFunction
HashCode hashCode = Files.hash(originFile, Hashing.md5());
System.out.println(originFile.getName() + " : " + hashCode);
} catch (IOException e) {
e.printStackTrace();
}
abc.java : 66721c8573de09bd17bafac125e63e98
提醒处理null的类Optional
Optional<Person> optional = Optional.fromNullable(person1); // 允许参数为null
System.out.println(optional.isPresent()); // true
System.out.println(optional.get() == person1); // 如果是person1 == null,get将抛出IllegalStateException, true
Optional<Person> optional2 = Optional.of(person1); // 不允许参数为null。如果person1 == null, 将抛出NullPointerException
System.out.println(optional2.isPresent()); // true
线程
com.google.common.util.concurrent目录下是各种线程工具类
ListenableFuture
:
可以监听的Future
,它是
对java原生Future的扩展增强
。
MoreExecutors
: 提供了很多
静态方法
。其中
listeningDecorator
方法
初始化ListeningExecutorService方法
,使用此实例
submit方法即可初始化ListenableFuture对象
。
ListeningExecutorService
的
invokeAny
继承自Jdk原生类,
率先返回线程组中首个执行完毕的
。
ListeningExecutorService
的
invokeAll
并行执行
线程组,
等待所有线程执行完毕
,适用于
批量处理
public final List<String> list = Lists.newArrayList("a", "b", "c", "d", "e", "f");
@Test
public void testGuava() {
ListeningExecutorService listeningExecutorService = MoreExecutors.listeningDecorator(Executors.newFixedThreadPool(10));
List<Callable<String>> allThread = Lists.newArrayList();
for (final String value : list) {
Callable<String> callable = new Callable<String>() {
@Override
public String call() {
return value + " 休息了 " + sleepRandom();
}
};
allThread.add(callable);
}
try {
//1. 返回首个执行完毕的值
// String date = listeningExecutorService.invokeAny(allThread);
// 2. 并行执行完所有线程
List<Future<String>> valueList = listeningExecutorService.invokeAll(allThread);
for (Future<String> future : valueList) {
System.out.println(future.get());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
listeningExecutorService.shutdown();
}
}
java 8 中
@Test
public void testJava8() throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(10);
List<CompletableFuture> futures = list.stream()
.map(value -> CompletableFuture.completedFuture(value).thenApplyAsync(s -> s + " 休息了 " + sleepRandom(), executor))
.collect(Collectors.toList());
//1. 返回首个执行完毕的值
// CompletableFuture valueFuture = CompletableFuture.anyOf(futures.toArray(new CompletableFuture[futures.size()]));
// 2. 并行执行完所有线程
CompletableFuture valueFutureList = CompletableFuture.allOf(futures.toArray(new CompletableFuture[futures.size()]));
futures.stream().forEach(f -> {
try {
System.out.println(f.get());
} catch (Exception e) {
}
});
}
缓存
其他
Lists并没有提供filter方法,不过你可以使用Collections2.filter
计算中间代码的运行时间 Stopwatch
import com.google.common.base.Stopwatch;
import java.util.concurrent.TimeUnit;
public class Test9 {
public static void main(String[] args) throws InterruptedException {
// 创建stopwatch并开始计时
Stopwatch stopwatch = Stopwatch.createStarted();
Thread.sleep(1980);
// 以秒打印从计时开始至现在的所用时间,向下取整
System.out.println(stopwatch.elapsed(TimeUnit.SECONDS)); // 1
// 停止计时
stopwatch.stop();
System.out.println(stopwatch.elapsed(TimeUnit.SECONDS)); // 1
// 再次计时
stopwatch.start();
Thread.sleep(100);
System.out.println(stopwatch.elapsed(TimeUnit.SECONDS)); // 2
// 重置并开始
stopwatch.reset().start();
Thread.sleep(1030);
// 检查是否运行
System.out.println(stopwatch.isRunning()); // true
long millis = stopwatch.elapsed(TimeUnit.MILLISECONDS); // 1034
System.out.println(millis);
// 打印
System.out.println(stopwatch.toString()); // 1.034 s
}
}
MoreObjects
这个方法是在
Objects过期后官方推荐使用的替代品
,该类最大的好处就是
不用大量的重写 toString
,用一种很优雅的方式实现重写,或者在某个场景定制使用
Person person = new Person("aa",11);
String str = MoreObjects.toStringHelper("Person").add("age", person.getAge()).toString();
System.out.println(str);
//输出Person{age=11}
firstNonNull
// 如果第一个为空,则返回第二个,同时为null,将抛出NullPointerException异常
String someString = null;
String value = Objects.firstNonNull(someString, "default value");
System.out.println(value); // deafult value
区间工具类Range
// 闭区间
Range<Integer> closedRange = Range.closed(30, 33);
System.out.println(closedRange.contains(30)); // true
System.out.println(closedRange.contains(33)); // true
// 开区间
Range<Integer> openRange = Range.open(30, 33);
System.out.println(openRange.contains(30)); // false
System.out.println(openRange.contains(33)); // false
Function<Person, Integer> ageFunction = new Function<Person, Integer>(){
@Override
public Integer apply(Person person) {
return person.getAge();
}
};
// Range实现了Predicate接口,这里的第一个参数是Predicate,第二个参数是Function
// ageFunction必须返回整数
Predicate<Person> agePredicate = Predicates.compose(closedRange, ageFunction);
System.out.println(agePredicate.apply(person1)); // person1.age == 30 true
Ordering排序器
可以用来为构建复杂的比较器,以完成集合排序的功能
natural() 对可排序类型做自然排序,如数字按大小,日期按先后排序
usingToString() 按对象的字符串形式做字典排序[lexicographical ordering]
from(Comparator) 把给定的Comparator转化为排序器
reverse() 获取语义相反的排序器
nullsFirst() 使用当前排序器,但额外把null值排到最前面。
nullsLast() 使用当前排序器,但额外把null值排到最后面。
compound(Comparator) 合成另一个比较器,以处理当前排序器中的相等情况。
lexicographical() 基于处理类型T的排序器,返回该类型的可迭代对象Iterable<T>排序器
onResultOf(Function) 对集合中元素调用Function,再按返回值用当前排序器排序
Person person = new Person("aa",14); //String name ,Integer age
Person ps = new Person("bb",13);
Ordering<Person> byOrdering = Ordering.natural().nullsFirst().onResultOf(new Function<Person,String>(){
@OverWirte
public String apply(Person person){
return person.age.toString();
}
});
int res = byOrdering.compare(person, ps);
System.out.println(res); //1 person的年龄比ps大 所以输出1
组合多个比较器
// 按照名字排序
Comparator<Person> nameCmp = new Comparator<Person>(){
@Override // 两个对象,而Comparable是this和一个对象
public int compare(Person o1, Person o2) {
return o1.getName().compareTo(o2.getName());
}
};
// 组合两个比较器,得到第一二排序关键字
// 年龄相同时按照名字排序
Ordering order = Ordering.from(ageCmp).compound(nameCmp);
Collections.sort(list, order);
for(Iterator<Person> iter = list.iterator(); iter.hasNext(); ){
System.out.println(iter.next());
}
Person{name='Wilma', sex='F', age=30}
Person{name='Betty', sex='F', age=32}
Person{name='Fred', sex='M', age=32}
Person{name='Barney', sex='M', age=33}
获取最小几个和最大几个
Ordering order2 = Ordering.from(nameCmp);
// 最小的两个,无序
System.out.println("least 2...");
List<Person> least = order2.leastOf(personList, 2);
for(int i = 0; i < 2; i++){
System.out.println(least.get(i));
}
// 最大的三个,无序
System.out.println("greatest 3....");
List<Person> great = order2.greatestOf(personList, 3);
for(int i = 0; i < 3; i++){
System.out.println(great.get(i));
}
least 2...
Person{name='Barney', sex='M', age=33}
Person{name='Betty', sex='F', age=32}
greatest 3....
Person{name='Wilma', sex='F', age=30}
Person{name='Fred', sex='M', age=32}
Person{name='Betty', sex='F', age=32}