概念
对kafka概念有所了解的可以直接跳过去看环境搭建。
kafka基本结构
消息生产者Producer、消费者Consumer、Kafka集群。
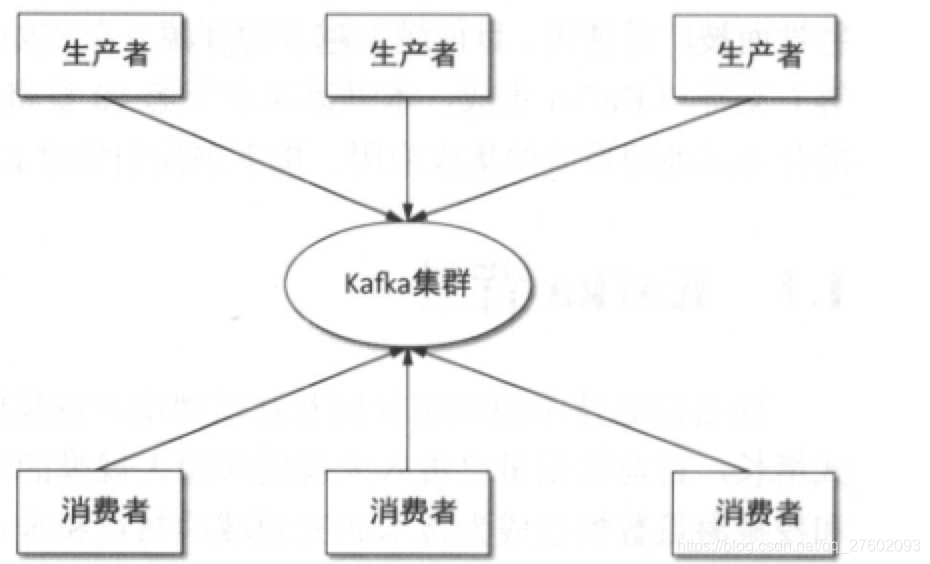
kafka基本概念
1.主题
主题就是对消息的一个分类。生产者将消息发送到特定主题,消费者订阅这个主题或主题的某些分区进行消费。
2.消息(Message/Record)
消息是kafka通信基本单位,由一个固定长度的消息头和一个可变长度的消息体构成。
3.分区和副本
分区
:将一组消息归纳为一个主题,而每个主题又分为一个或多个分区(Partition)。每个分区是一个有序队列。每个分区在物理上对应一个文件夹。每条消息追加到相应的分区中,是顺序写磁盘(速度超快)。
副本
:副本分布在集群的不同代理上,提高可用性。分区的副本与日志对象一一对应。
4.Leader副本与Follower副本
为了确保分区的多个副本之间数据的一致性,Kafka会选择该分区的一个副本作为Leader副本,其他副本为Follower副本。这样做简化了数据一致性。
5.偏移量
任何发布的消息都会被直接追加到日志文件尾部(文件后缀为.log)。每条消息在日志文件的位置都会对应一个按序递增的偏移量。偏移量是分区下严格有序的逻辑值,并不表示消息在磁盘上的物理位置。消费者可以通过控制消息偏移量来对消息进行消费。为保证消息被顺序消费,旧版消费者将消费偏移量保存在Zookeeper中,新盘消费者将消息偏移量保存在Kafka内部一个主题当中。当然消费者可以在自己系统中保存偏移量。
6.日志段
日志段是Kafka日志对象分片的最小单位。一个日志段对应磁盘上一个具体日志文件和两个索引文件。两个索引文件分别以”.index”和”.timeindex”作为文件名后缀,分别表示消息偏移量索引文件和消息时间戳索引文件。
7.代理
Kafka集群就是有1个多多个Kafka实例组成的,每个Kafka实例称为代理。每个代理都有唯一的标识id。Kakka代理是无状态的,所以通过ZK来维护集群状态。
8.生产者
负责将消息发送给代理,即就是向Kafka代理发送消息的客户端。
9.消费者和消费组
消费者以拉取方式拉取数据。每个消费者都属于一个特定的消费组。如果不指定消费组,则消费者默认属于默认消费组tet-consumer-group。同一条消息只能被同一个消费组中某个消费者消费,但不同消费组的消费者可同时消费该消息。如果想要广播,每个消费者属于不同消费组就行。单播,让所有消费组在同一个消费组。
1
0.ISR
ISR保存同步的副本列表,该列表中保存的是与Leader副本保持消息同步的所有副本对应的代理节点id。
11.Zookeeper
Kafka利用Zookeeper保存相应元数据信息(代理节点信息、主题信息、分区状态信息等)
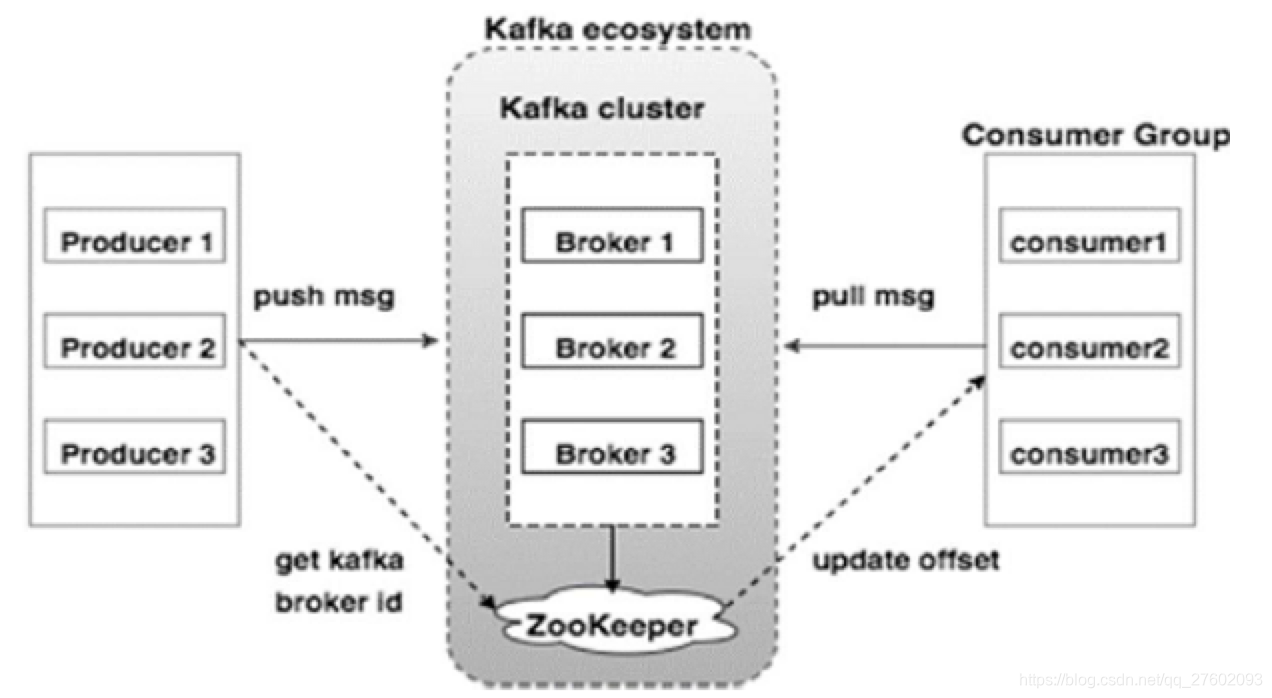
环境搭建(我的是linux centos6.x)
1.确保自己安装了jdk
yum install java-1.8.0-openjdk.x86_64
接着配置JAVA环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64/jre
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
通过
java -version
查看是否安装完成。
2.安装jps
yum install java-1.8.0-openjdk-devel.x86_64
这是用来查看有哪些java进程在运行。 zk启动后可以检查是否启动。
3.下载zookeeper
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
将该压缩包解压后进入zk目录。
先创建一个data目录,存日志用。
进入zk目录下的conf目录,里面有zoo_sample.cfg,备份后,修改该文件名称为zoo.cfg。
接着编辑
vim zoo.cfg
文件。dataDir的路径是
刚才你创建的dada全路径,别照抄!

然后返回上一级目录进入bin目录,启动ZK。

4.下载kafka
wget http://mirror.bit.edu.cn/apache/kafka/2.3.0/kafka_2.12-2.3.0.tgz
启动kafka,后台运行
bin/kafka-server-start.sh -daemon config/server.properties
你可能想这就完了?发现起不来,或者测试生产者消费者无法通信?接着往下看!
遇到的问题及解决
1.kafka无法申请过大内存
错误信息:
kafka启动:Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memor
解决:
vim /bin/kafka-server-start.sh
更改最大堆内存xmx,堆初始内存xms。
-Xmx256M -Xms128M
2.kafka运行过程中localhost.localdomain: 未知的名称或服务
错误信息:
ERROR Unknown error when running consumer: (kafka.tools.ConsoleConsumer$)
java.net.UnknownHostException: localhost.localdomain: localhost.localdomain: 未知的名称或服务
at java.net.InetAddress.getLocalHost(InetAddress.java:1475)
at kafka.consumer.ZookeeperConsumerConnector.<init>(ZookeeperConsumerConnector.scala:122)
at kafka.consumer.ZookeeperConsumerConnector.<init>(ZookeeperConsumerConnector.scala:146)
at kafka.consumer.Consumer$.create(ConsumerConnector.scala:109)
解决:
我们需要编辑
config/server.properties
将
host.name=localhost
改为ip地址也就是
host.name=xxxx.xxxx.xxxx.xxxx
如果生产者创建不了 那么需要查看下面链接
错误信息:
WARN [Producer clientId=console-producer] Connection to node -1 could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
解决:
编辑
config/server.properties

listeners需要配置,然后根据配置连接topic。
原来如果是:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
改为
bin/kafka-console-producer.sh --broker-list master:9092 --topic test
参考文章
linux启动zk
生产者问题
kafka运行过程中localhost.localdomain: 未知的名称或服务
kafka启动:Native memory allocation (mmap) failed to map 1073741824 bytes for committing reserved memor