目录
2.1统计聚合(交集,差集,并集,补集(属于全集U不属于集合A))
1.面对LBS(local-based-services)引用的GEO数据类型
一.String不在适用Redis底层数据结构
1.String类型的内存消耗问题
String类型提供的是“一个键一个值”的保存方式
例如存储图片:图片ID和图片存储对象ID都是10位数,保存了1亿张图片的信息,用了约6.4GB的内存。一个图片id和图片存储地址平均使用了64字节。
photo_id: 3301000051
photo_obj_id :3301000051String类型的短板:保存的数据越多,消耗的内存空间越多
图片ID和图片存储对象ID都是10位数,我们可以用两个8字节的Long类型表示这两个ID因为8字节的Long类型最大可以表示2的64次方的数值,所以肯定可以表示10位数。但是,为什么String类型却用了64字节呢?
其实,除了记录实际数据,String类型还需要额外的内存空间记录数据长度、空间使用等信息,这些信息叫作元数据。当实际保存的数据较小时,元数据的空间开销就显得比较大了,有点“喧宾夺主”的意思。
2:String类型怎么保存数据
当保存64位有符号整数,String类型会把他保存到一个8字节的long类型整数,这种方式叫做int编码方式。
保存的数据有字符是,String类型会使用简单动态字符串结构体来保存(Simple Dynamic String,SDS):、
SDS中,buf保存实际的数据,len和alloc本身就是SDS结构体额外的开销

- len:占4个字书,表示buf的已用长度。
- alloc:也占个4字节,表示buf的实际分配长度,一般大于len。
- buf:字节数组。保存实际数据。为了表示字节数组的结束,Redis会自动在数组最后加一个“1O”,这就会额外占用1个字节的开销。
对于String类型来说,除了SDS的额外开销,还有一个来自于RedisObject结构体的开销。
因为Redis的数据类型有很多,而且,不同数据类型都有些相同的元数据要记录(比如最后一次访问的时间、被引用的次数等),所以,Redis会用一个RedisObject结构体来统一记录这些元数据,同时指向实际数据。
2.1RedisObject结构体:
RedisObject:一个RedisObject包含了8字节的元数据和一个8字节指针,这个指针再进一步指向具体数据类型的实际数据所在,例如指向String类型的SDS结构所在的内存地址,RedisObject结构体:
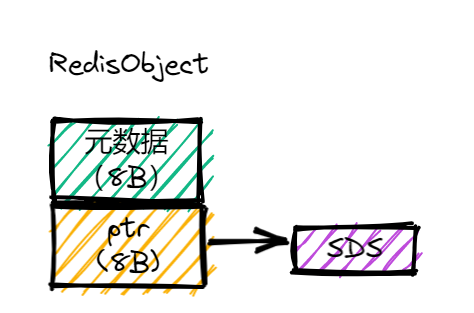
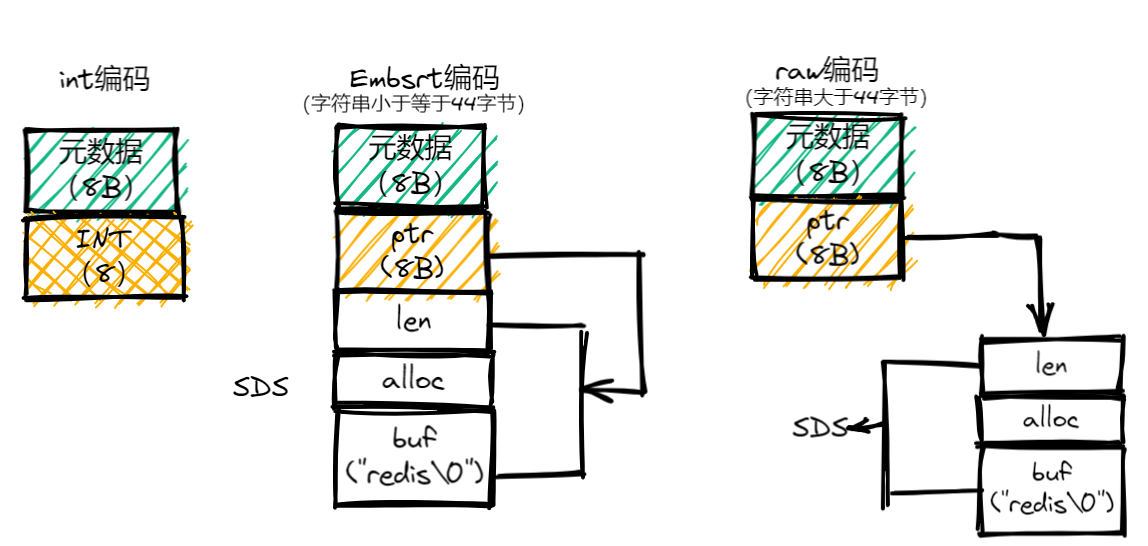
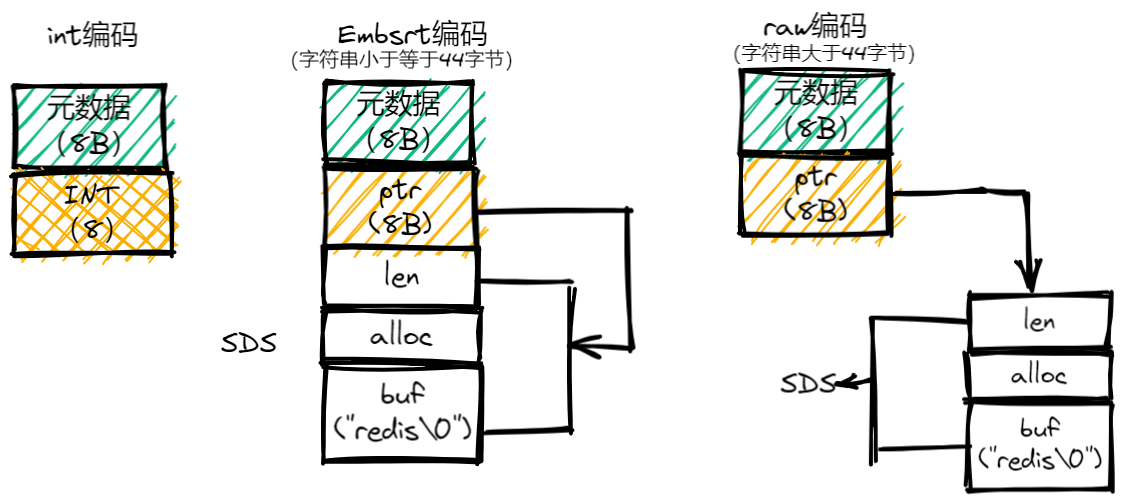
- 为了节省内存空间,Redis还对Long类型整数和SDS的内存布局做了专门的设计。当保存的是Long类型整数时,RedisObject中的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
- 当保存的是字符串数据,并且字符串小于等于44字节时,RedisObject中的元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片。这种布局方式也被称为embstr编码方式。
- 当字符串大于44字节时,SDS的数据量就开始变多了,Redis就不再把SDS和RedisObject布局在一起了,而是会给SDS分配独立的空间,并用指针指向SDS结构。这种布局方式被称为raw编码模式。
2.2int、embstr和raw这三种编码模式
int、embstr和raw这三种编码模式,我画了一张示意图,如下所示:
2.3计算String的内存量
因为10位数的图片ID和图片存储对象ID是Long类型整数,所以可以直接用int编码的RedisObject保存。每个int编码的Redisobject元数据部分占8字节,指针部分被直接赋值为8字节的整数了。此时,每个ID会使用16字节,加起来一共是32字节。但是,另外的32字节去哪儿了呢?
Redis会使用一个全局哈希表保存所有键值对,哈希表的每一项是一个dictEntry的结构体,用来指向一个键值对。dictEntry结构中有三个8字节的指针,分别指向key、value以及下一个
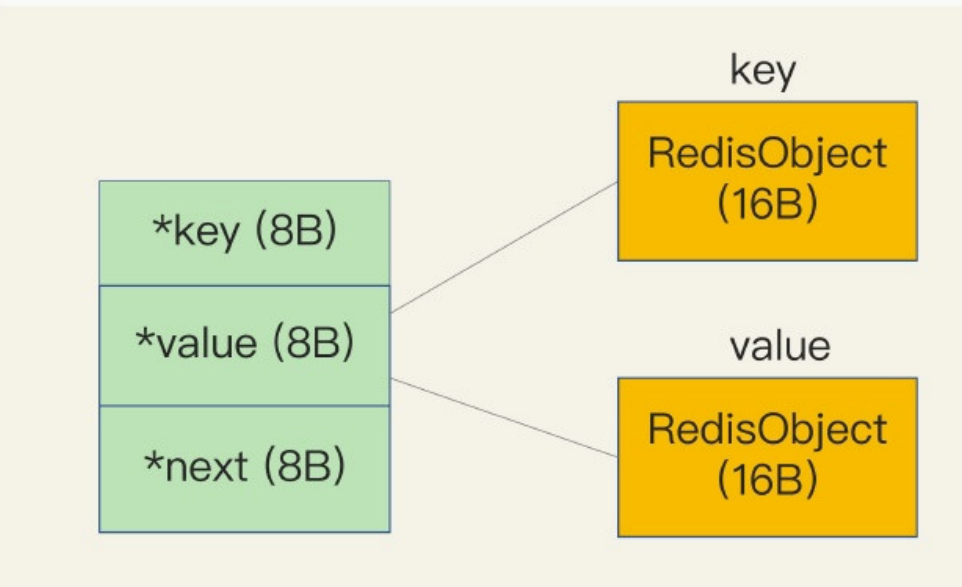
这三个指针只有 24 字节,为什么会占用了 32 字节呢?这就要提到 Redis 使用的内存分配库 jemalloc 了。
jemalloc在分配内存时,会根据我们申请的字节数N,找一个比N大,但是最接近N的2的幂次数作为分配的空间,这样可以减少频繁分配的次数。
举个例子。如果你申请6字节空间,jemalloc实际会分配8字节空间;如果你申请24字节空间,jemalloc则会分配32字节。所以,在我们刚刚说的场景里,dictEntry结构就占用了32字节
明明有效信息只有16字节,使用String类型保存时,却需要64字节的内存空间,有48字节都没有用于保存实际的数据。我们来换算下,如果要保存的图片有1亿张,那么1亿条的图片ID记录就需要6.4GB内存空间,其中有4.8GB的内存空间都用来保存元数据了,额外的内存空间开销很大。
那么,有没有更加节省内存的方法呢?
2.4节省内存的数据结构?
使用Redis的底层数据结构:压缩列表(zipList)
2.4压缩列表(ZipList)的构成
表头有三个字段zlbytes、zltail和zllen,分别表示列表长度、列表尾的偏移压缩列表尾还有一个zlend,表示列表结束。
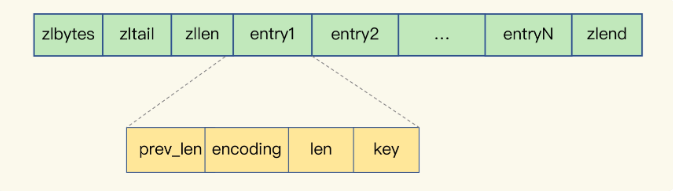
压缩列表之所以能节省内存,就在于它是用一系列连续的 entry 保存数据。每个 entry 的元数据包括下面几部分。
- prev_len,表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节。虽然 1 字节的值能表示的数值范围是 0 到 255,但是压缩列表中 zlend 的取值默认是 255,因此,就默认用 255 表示整个压缩列表的结束,其他表示长度的地方就不能再用 255 这个值了。所以,当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。
- len:表示自身长度,4 字节;
- encoding:表示编码方式,1 字节;
- content:保存实际数据。
这些entry会挨个儿放置在内存中,不需要再用额外的指针进行连接,这样就可以节省指针所占用的空间。连续排列,不需要额外的使用指针。
以保存图片存储对象ID为例,来分析一下压缩列表是如何节省内存空间的。
每个entry保存一个图片存储对象ID(8字节),此时,每个entry的prev_len只需要1个字节就行,因为每个entry的前一个entry长度都只有8字节,小于254字节。这样一来,一个图片的存储对象ID所占用的内存大小是14字节(1+4+1+8=14),实际分配16字节。
Redis基于压缩列表实现了List、Hash和Sorted Set这样的集合类型,这样做的最大好处就是节省了
dictEntry的开销。当你用String类型时,一个键值对就有一个dictEntry,要用32字节空间。但采用集合类型时,一个key就对应一个集合的数据,能保存的数据多了很多,但也只用了一个dictEntry,这样就节省了内存。
2.5如何用集合类型保存单键值对?
在保存单值的键值对时,可以采用基于Hash类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为Hash集合的key,后一部分作为Hash集合的value,这样一来,我们就可以把单值数据保存到Hash集合中了
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。
Redis 中插入了一组图片 ID 及其存储对象 ID 的记录,并且用 info 命令查看了内存开销,增加一条记录后,内存占用只增加了 16 字节:
127.0.0.1:6379> info memory
# Memory
used_memory:1039120
127.0.0.1:6379> hset 1101000 060 3302000080
(integer) 1
127.0.0.1:6379> info memory
# Memory
used_memory:1039136在使用 String 类型时,每个记录需要消耗 64 字节,这种方式却只用了 16 字节,所使用的内存空间是原来的 1/4,满足了我们节省内存空间的需求。
疑惑:“二级编码一定要把图片 ID 的前 7 位作为 Hash 类型的键,把最后 3 位作为 Hash 类型值中的 key 吗?”其实,二级编码方法中采用的 ID 长度是有讲究的。
解释:Redis Hash 类型的两种底层实现结构,分别是压缩列表和哈希表。
Hash 类型底层结构什么时候使用压缩列表,什么时候使用哈希表呢?
其实,Hash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。
这两个阈值分别对应以下两个配置项:
- hash-max-ziplist-entries:表示用压缩列表保存时哈希集合中的最大元素个数。
- hash-max-ziplist-value:表示用压缩列表保存时哈希集合中单个元素的最大长度。
如果我们往 Hash 集合中写入的元素个数超过了 hash-max-ziplist-entries,或者写入的单个元素大小超过了 hash-max-ziplist-value,Redis 就会自动把 Hash 类型的实现结构由压缩列表转为哈希表。一旦从压缩列表转为了哈希表,Hash 类型就会一直用哈希表进行保存,而不会再转回压缩列表了。在节省内存空间方面,哈希表就没
有压缩列表那么高效了。
为了能充分使用压缩列表的精简内存布局,我们一般要控制保存在 Hash 集合中的元素个数。所以,在刚才的二级编码中,我们只用图片 ID 最后 3 位作为 Hash 集合的 key,也就保证了 Hash 集合的元素个数不超过 1000,同时,我们把 hash-max-ziplist-entries 设置为 1000,这样一来,Hash 集合就可以一直使用压缩列表来节省内存空间了。

3.总结
以前,认为String是“万金油”,什么场合都适用,但是,在保存的键值对本身占用的内存空间不大时(例如提到的的图片ID和图片存储对象ID), String类型的元数据开销就占据主导了,这里面包括了RedisObject结构、SDS结构、dictEntry结构的内存开销。
针对这种情况,我们可以使用压缩列表保存数据。当然,使用Hash这种集合类型保存单值键值对的数据时,我们需要将单值数据拆分成两部分,分别作为Hash集合的键和值,就像刚才案例中用二级编码来表示图片ID,希望你能把这个方法用到自己的场景中。
最后,我还想再给你提供一个小方法:如果你想知道键值对采用不同类型保存时的内存开销,可以在
这个网址
里输入你的键值对长度和使用的数据类型,这样就能知道实际消耗的内存大小了。建议你把这个小工具用起来,它可以帮助你充分地节省内存。
除了String类型和Hash类型,你觉得,还有其他合适的类型可以应用在这节课所说的保存图片的例子吗?
答案:除了String和Hash,我们述可以使用Sorted Set类型进行保存。Sorted Set的元素有member值和score值,可以像Hash那样,使用二级编码进行保存。具体做法是,把图片ID的前7位作为Sorted Set的key,把图片ID的后3位作为member值,图片存储对象ID作为score值。
Sorted Set中元素较少时,Redis会使用压缩列表进行存储,可以节省内存空间。不过,和Hash不一样,Sorted Set插入数据时,需要按score值的大小排序。当底层结构是压缩列表时,Sorted Set的插入性能就比不上Hash。上边存储图片描述的场景中,Sorted Set类型虽然可以用来保存,但并不是最优选项。
一个key对应一个集合的处理
1.应用场景
在Web和移动应用的业务场景中,我们经常需要保存这样一种信息:一个key对应了一个数据集合。我举几个例子。
- 手机App中的每天的用户登录信息:一天对应一系列用户ID或移动设备ID;
- 电商网站上商品的用户评论列表:一个商品对应了一系列的评论;
- 用户在手机App上的签到打卡信息:一天对应一系列用户的签到记录;
- 应用网站上的网页访问信息:一个网页对应一系列的访问点击。
Redis集合类型的特点就是一个键对应一系列的数据,所以非常适合用来存取这些数据。
除了记录数据还需要对数据进行统计:
- 在移动应用中,需要统计每天的新增用户数和第二天的留存用户数;
- 在电商网站的商品评论中,需要统计评论列表中的最新评论;
- 在签到打卡中,需要统计一个月内连续打卡的用户数;
- 在网页访问记录电,需要统计独立访客(Unique Visitor,UV)量。
要想选择合适的集合,我们就得了解常用的集合统计模式。介绍集合类型常见的四种统计模式,包括聚合统计、排序统计、二值状态统计和基数统计。以刚刚提到的这四个场景为例。
2.集合统计模式
2.1统计聚合(交集,差集,并集,补集(属于全集U不属于集合A))
统计聚合:就是指统计多个集合元素聚合结果。包括:统计多个集合的共有元素(交集统计)﹔把两个集合相比,统计其中一个集合独有的元素(差集统计)﹔统计多个集合的所有元素〈并集统计)。
场景一:统计手机App每天的新增用户数和第二天的留存用户数。
要完成这个统计任务,我们可以用一个集合记录所有登录过App的用户ID,同时,用另一个集合记录每一天登录过App的用户ID。然后,再对这两个集合做聚合统计。我们来看下具体的操作。
记录所有登录过App的用户ID还是比较简单的,我们可以直接使用Set类型,把key设置为user280680,表示记录的是用户ID,value就是一个Set集合,里面是所有登录过App的用户ID,我们可以把这个Set叫作累计用户Set,如下图所示:
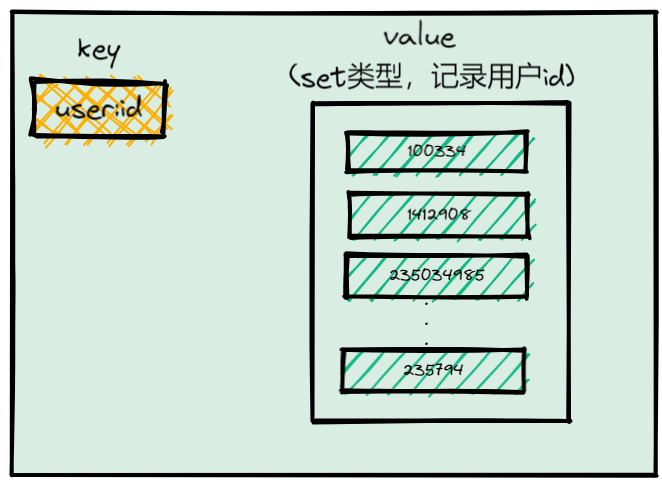
需要注意的是,累计用户Set中没有日期信息,我们是不能直接统计每天的新增用户的。所以,我们还需要把每一天登录的用户ID,记录到一个新集合中,我们把这个集合叫作每日用户Set,它有两个特点:
1.key是user280680以及当天日期,例如user280680:20200803;
2.value是Set集合,记录当天登录的用户ID。
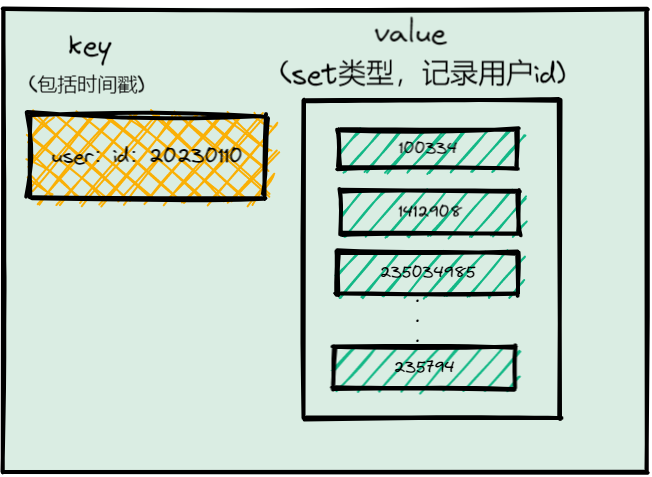
统计每天新增的用户
在统计每天的新增用户时,只用计算每日用户Set和累计用户Set的差集就行。
假设我们的手机App在2020年8月3日上线,那么,8月3日前是没有用户的。此时,累计用户Set是空集,当天登录的用户ID会被记录到 key为user280680:20200803的Set中。所以,user280680:20200803这个Set中的用户就是当天的新增用户(用id:时间:set存放当天新增用户)。
然后,我们计算累计用户Set和user280680:20200803 Set的并集结果(当天与总集合的并集)(和),结果保存在user280680这个累计用户Set中,如下所示:
SUNIONSTORE user280680 user280680 user280680:20200803统计每天存留的用户
此时,user280680这个累计用户Set中就有了8月3日的用户ID。等到8月4日再统计时,我们把8月4日登录的用户ID记录到user280680:20200804的Set中。接下来,我们执行SDIFFSTORE命令计算累计用户Set和
user280680:20200804 Set的差集(所有属于A不属于B的数据),结果保存在key为user:new的Set中,如下所示:(A中存在B中不存在的元素)
SDIFFSTORE user: new user280580:2020B804 user280680可以看到,这个差集中的用户ID在user280680:20200804的Set中存在,但是不在累计用户Set中。所以,user:new这个Set中记录的就是8月4日的新增用户。
当要计算8月4日的留存用户时,我们只需要再计算user280680:20200803和user280680:20200804两个Set的交集(共同元素),就可以得到同时在这两个集合中的用户ID了,这些就是在8月3日登录,并且在8月4日留存的用户。执行的命令如下:
SINTERSTORE user280680:rem user280680:20200803 user280680:20200804Set集合保存数据的缺点
Set的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致Redis实例阻塞。所以,一个小建议∶你可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计,这样就可以规避阻塞主库实例和其他从库实例的风险了。
2.2排序统计
场景二:在电商网站的商品评论中,需要统计评论列表中的最新评论;
最新评论列表包含了所有评论中的最新留言,这就要求集合类型能对元素保序,也就是说,集合中的元素可以按序排列,这种对元素保序的集合类型叫作有序集合。
在Redis常用的4个集合类型中(List、Hash、Set、Sorted Set) , List和Sorted Set就属于有序集合。
List是按照元素进入List的顺序进行排序的,而Sorted Set可以根据元素的权重来排序我们可以自己来决定每个元素的权重值。比如说,我们可以根据元素插入Sorted Set的时间确定权重值,先插入的元素权重小,后插入的元素权重大。
List和Sorted Set的选择
用List实现:每个商品对应一个List,这个List包含了对这个商品的所有评论,而且会按照评论时间保存这些评论,每来一个新评论,就用LPUSH命令把它插入List的队头。
在只有一页评论的时候,可以很清晰地看到最新的评论,但是,在实际应用中,网站一般会分页显示最新的评论列表,一旦涉及到分页操作,List就可能会出现问题了。
假设当前的评论List是A B,C,E,F}(其中,A是最新的评论,以此类推,F是最早的评论),在展示第一页的3个评论时。我们可以用下面的命令,得到最新的三条评论A、B、C:
LRANGE product1 0 2
1)"A"
2)"B"
3)"C"
LRANGE product1 3 5
1)"D"
2)"E"
3)"F"但是,如果在展示第二页前,又产生了一个新评论G,评论G就会被LPUSH命令插入到评论List的队头,评论List就变成了[G,A,B,C,D,E,F}。此时,再用刚才的命令获取第二页评论时,就会发现,评论C又被展示出来了,也就是C、D、E。(更新页面的时候,新数据插入,数据会重复展示)
LRANGE product1 3 5
1)"C"
2)"D"
3)"E"原因:
关键原因就在于,List是通过元素在List中的位置来排序的,当有一个新元素插入时,原先的元素在List中的位置都后移了一位,比如说原来在第1位的元素现在排在了第2位。所以,对比新元素插入前后,List相同位置上的元素就会发生变化,用LRANGE读取时,就会读到旧元素。
和List相比,Sorted Set就不存在这个问题,因为它是根据元素的实际权重来排序和获取数据的。
我们可以按评论时间的先后给每条评论设置一个权重值,然后再把评论保存到Sorted Set中。Sorted Set的ZRANGEBYSCORE命令就可以按权重排序后返回元素。这样的话,即使集合中的元素频繁更新,Sorted Set也能通过ZRANGEBYSCORE命令准确地获取到按序排列的数据。
假设越新的评论权重越大,目前最新评论的权重是N,我们执行下面的命令时,就可以获得最新的10条评论:(往前取九位)
ZRANGEBYSCORE comnents N-9 N所以,在面对需要展示最新列表,排行榜等场景时,如果数据更新频繁或者需要分页显示,建议你优先考虑使用Sorted Set。
优先选择Sorted Set
Sorted Set:根据元素的实际权重ZRANGEBYSCORE来排序和获取数据的。
使用场景:展示最新列表,排行榜等场景时,数据更新频繁或者需要分页显示
2.3二值状态统计
第三个场景:二值状态统计。这里的二值状态就是指集合元素的取值就只有0和1两种。在签到打卡的场景中,记录签到(1)或未签到(0),所以它就是非常典型的二值状态,
场景三:用户在手机App上的签到打卡信息:一天对应一系列用户的签到记录;
在签到统计时,每个用户一天的签到用1个bit位就能表示,一个月(假设是31天)的签到情况用31个bit位就可以,而一年的签到也只需要用365个bit位,根本不用太复杂的集合类型。可以选择Bitmap。这是Redis提供的扩展数据类型。
Bitmap说明
Bitmap本身是用String类型作为底层数据结构实现的一种统计二值状态的数据类型。String类型是会保存为二进制的字节数组,所以,Redis就把字节数组的每个bit位利用起来,用来表示一个元素的二值状态。你可以把Bitmap看作是一个bit数组。
Bitmap提供了GETBIT/SETBIT操作,使用一个偏移值offset对bit数组的某一个bit位进行读和写。不过,需要注意的是,Bitmap的偏移量是从0开始算的,也就是说offset的最小值是0。当使用SETBIT对一个bit位进行写操作时,这个bit位会被设置为1。Bitmap还提供了BITCOUNT操作,用来统计这个bit数组中所有“1”的个数。
BitMap具体使用:
假设我们要统计ID 3000的用户在2020年8月份的签到情况,就可以按照下面的步骤进行操作。
第一步,执行下面的命令,记录该用户8月3号已签到。
SETBIT uid:sign:3000:202008 2 1第二步,检查该用户8月3日是否签到。
GETBIT uid:sign:3000:202008 2第三步,统计该用户在8月份的签到次数。
BITCOUNT uid:sign:3000:202008思考一个问题:如果记录了1亿个用户10天的签到情况,你有办法统计出这10天连续签到的用户总数吗?
Bitmap支持用BITOP命令对多个Bitmap按位做“与”“或”“异或”的操作,操作的结果会保存到一个新的Bitmap中。
从下图中,可以看到,三个Bitmap bm1、bm2和bm3,对应bit位做“与”操作,结果保存到了一个新的Bitmap中(示例中,这个结果Bitmap的key被设为resmap)

根据上边的bitMap描述,分别将一亿个用户,的10个Bitmap做“与”操作,得到的结果也是一个Bitmap。在这个Bitmap中,只有10天都签到的用户对应的bit位上的值才会是1。最后,我们可以用BITCOUNT统计下Bitmap中的1的个数,这就是连续签到10天的用户总数了。
计算一下记录了10天签到情况后的内存开销。每天使用1个1亿位的Bitmap,大约占12MB。10天的Bitmap的内存开销约为120MB,内存压力不算太大。
不过,在实际应用时,最好对Bitmap设置过期时间,让Redis自动删除不再需要的签到记录,以节省内存开销。
所以,如果只需要统计数据的二值状态,例如商品有没有、用户在不在等,就可以使用Bitmap,因为它只用一个bit位就能表示0或1。在记录海量数据时,Bitmap能够有效地节省内存空间。
2.4基数统计
统计场景︰基数统计。基数统计就是指统计一个集合中不重复的元素个数。对应到我们刚才介绍的场景中,就是统计网页的UV。
场景四:应用网站上的网页访问信息:一个网页对应一系列的访问点击。
网页UV的统计有个独特的地方,就是需要去重,一个用户一天内的多次访问只能算作一次。在Redis的集合
类型中,Set类型默认支持去重,所以看到有去重需求时,最常使用的是set类型。
Set使用说明:
有一个用户user1访问page1时,你把这个信息加到Set中:
SADD page1:uv user1用户1再来访问时Set的去重功能就保证了不会重复记录用户1的访问次数,这样,用户1就算是一个独立访客。当你需要统计UV时,可以直接用SCARD命令,这个命令会返回一个集合中的元素个数。
数据量大Set存在的问题:内存消耗过大:
但是,如果page1非常火爆,UV达到了千万,这个时候,一个Set就要记录千万个用户ID。对于一个搞大促的电商网站而言,这样的页面可能有成千上万个,如果每个页面都用这样的一个Set,就会消耗很大的内存空间。
HASH类型记录数据
用户访问的时候,用HASH存储数据,HSet进去用户的访问值设置为1,表示一个独立的访客:
Hset page1:uv user1 1重复执行命令,也只是把用户下面的值设置成1.
但是,数据量越来越多,也还是会出现Set集合中,内存消耗过大的问题。
HyperLogLog说明:集合数据,数据空间固定小且固定不变
HyperLogLog是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
在Redis中,每个HyperLogLog只需要花费12KB 内存,就可以计算接近2^64个元素的基数。你看,和元素越多就越耗费内存的Set和Hash类型相比,HyperLogLog就非常节省空间。
在统计UV时,你可以用PFADD命令(用于向HyperLogLog中添加新元素)把访问页面的每个用户都添加到HyperLogLog:
PFADD pagei:uv user1 user2 usera user4 user5接下来,就可以用PFCOUNT命令直接获得page1的Uv值了,这个命令的作用就是返回HyperLogLog的统计结果。
注意:HyperLogLog计算的数据不准确,存在0.19的误差
,HyperLogLog的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是0.81%。这也就意味着,你使用HyperLogLog统计的UV是100万,但实际的UV可能是101万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用Set或Hash类型。
2.5总结
结合统计新增用户数量和留存的用户数量、最新评论列表,用户签到数以及网页独立访问量这四种典型场景:引用四种统计方法:集合统计(set)、排序统计(sorted set)、二值状态统计(bitmap),基数统计(HyperLogLog)
|
数据类型 |
聚合统计 |
排序统计 |
二值状态统计 |
基数统计 |
|
Set |
支持差集、并集、交集计算 |
不支持 |
不支持 |
精确统计,大数据量时, 效率低,内存消耗大 |
|
Sorted Set |
支持交集、并集 |
支持 |
||
|
Hash |
不支持 |
不支持 |
||
|
List |
不支持 |
支持 |
不支持,元素没有去重 |
|
|
BitMap |
与、或、异或 |
不支持 |
支持,数据量大时,效率高,省内存 |
精确统计,大数据量时,内存到与hyperLogLog |
|
HyperLogLog |
不支持 |
不支持 |
不支持 |
概率统计,大数据量时,非常节省内存 |
说明:
- Set和Sorted Set都支持多种聚合统计,不过,对于差集计算来说,只有Set支持。Bitmap也能做多个Bitmap间的聚合计算包括与、或和异或操作。
- 当需要进行排序统计时,List中的元素虽然有序,但是一旦有新元素插入,原来的元素在List中的位置就会移动,那么,按位置读取的排序结果可能就不准确了。而Sorted Set本身是按照集合元素的权重排序,可以准确地按序获取结果,所以建议优先使用它。
- 记录的数据只有0和1两个值的状态,Bitmap会是一个很好的选择,这主要归功于Bitmap对于一个数据只用1个bit记录,可以节省内存。
- 基数统计来说,如果集合元素量达到亿级别而且不需要精确统计时,我建议你使用HyperLogLog
有效学习方法:Redis的应用场景非常多,这张表中的总结不一定能覆盖到所有场景。建议你也试着自己画一张表,把遇到的其他场景添加进去。长久积累下来,一定能够更加灵活地把集合类型应用到合适的实践项目中。
介绍了4种典型的统计模式,分别是聚合统计、排序统计、二值状态统计和基数统计,以及它们各自适合的集合类型。你还遇到过其他的统计场景吗?用的是什么集合类型呢?
答案:一种场景:使用List+Lua统计最近200个客户的触达率。具体做法是,每个List元素表示一个客户,元素值为0,代表触达;元素值为1,就代表未触达。在进行统计时,应用程序会把代表客户的元素写入队列中。当需要统计触达率时,就使用LRANGE key 0-1取出全部元素,计算0的比例,这个比例就是触达率。
这个例子需要获取全部元素,不过数据量只有200个,不算大,所以,使用List,在实际应用中也是可以接受的。但是,如果数据量很大,又有其他查询需求的话((例如查询单个元素的触达情况),List的操作复杂度较高,就不合适了,可以考虑使用Hash类型。
Redis三种扩展数据类型之GEO
Redis 提供了5大基本数据类型:Set,Sorted Set,Hash,List String 他们可以满足大多数的基本数据存储需求,但是面对海量数据,大数据级别的数据量时,他们开销会很大,而且对于特殊场景无法支持,Redis提供了三种扩展数据类型:分别是Bitmap、HyperLogLog和GEO。
1.面对LBS(local-based-services)引用的GEO数据类型
在日常生活中,我们越来越依赖搜索、在打车软件上叫车,这些都离不开基于位置信息服务(Location-Based Service,的应用。LBS应用访问的数据是和人或物关联的一组经纬度信息,要能查询相邻的经纬度范围,而且GEO就非常适合应用在LBS服务的场景中.
1.1GEO底层数据结构
一般来说,在设计一个数据类型的底层结构时,首先需要知道,要处理的数据有什么访问特点。
位置信息是怎么被存储的?
叫车服务为例,分析LBS应用中经纬度的存取特点。
1.每一辆网约车都有一个编号(例如33),网约车需要将自己的经度信息(例如116.034579)和纬度信息
(例如39.000452)发给叫车应用。
2.用户在叫车的时候,叫车应用会根据用户的经纬度位置(例如经度116.0‘54579,纬度39.030452),查找
用户的附近车辆,并进行匹配。
3.等把位置相近的用户和车辆匹配上以后,叫车应用就会根据车辆的编号,获取车辆的信息,并返回给用
户。
一辆车(或一个用户)对应一组经纬度,并且随着车(或用户)的位置移动,相应的经纬度也会变化。需要的业务有添加数据跟查找数据(查找数据就需要数据有序)
1.1.1Hash基本数据类型使用情况
这种数据记录模式属于一个key(例如车ID)对应一个value (一组经纬度)。当有很多车辆信息要保存时,就需要有一个集合来保存一系列的key和value。Hash集合类型可以快速存取一系列的key和value,正好可以用来记录一系列车辆ID和经纬度的对应关系,所以,我们可以把不同车辆的ID和它们对应的经纬度信息存在Hash集合中,如下图所示:
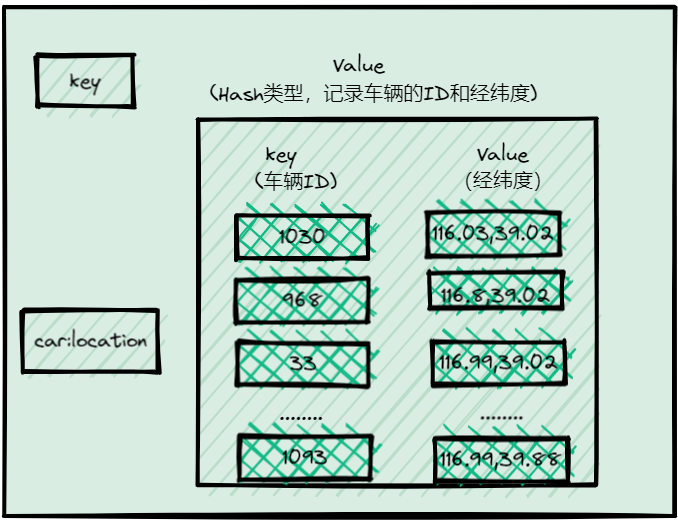
同时,Hash类型的HSET操作命令,会根据key来设置相应的value值,所以,可以用它来快速地更新车辆变化的经纬度信息。但是,对于一个LBS应用来说,除了记录经纬度信息,还需要根据用户的经纬度信息在车辆的Hash集合中进行范围查询。一旦涉及到范围查询,就意味着集合中的元素需要有序但Hash类型的元素是无序的,Hash不符合要求。
1.1.2Sorted Set数据类型的使用
Sorted Set 数据类型也支持一个key对应一个value的记录模式。key就是Sorted Set 中的元素,value是数据的权重分数。主要是,Sorted Set 可以根据元素权重分数排序,支持范围查询,满足LDS范围查找,查找相邻位置。
GEO的底层数据结构就是Sorted Set数据类型。
用Sorted Set来保存车辆的经纬度信息时,Sorted Set的元素是车辆ID,元素的权重分数是经纬度信息,如下图所示:
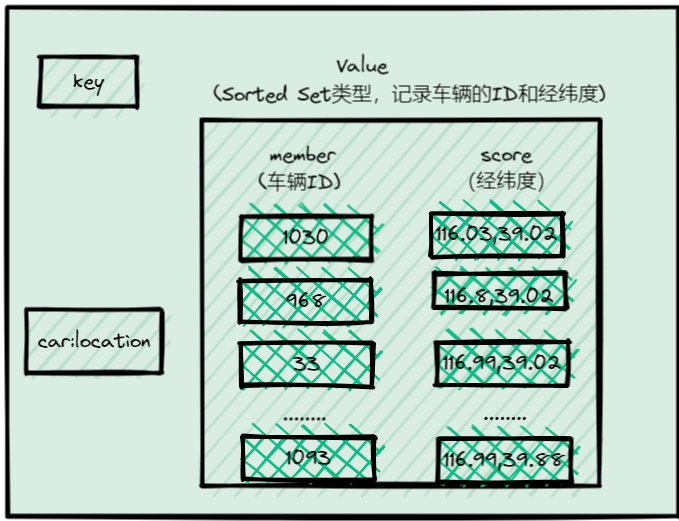
Sorted Set 元素的权重是一个浮点数(float类型),而一组经纬度包括经度和纬度两个值,是没办法保存为一个浮点数的,这个问题怎么解决呢?
GEO中的GEOHash编码方式
1.2GEO的GEOHash编码方式
GeoHash编码方法,这个方法的基本原理就是“二分区间,区间编码”
GeoHash方法可以高效的对进位度进行比较,对经纬度进行GeoHash编码时,需要对经纬度重新编码,然后在组合起来成为一个新的最终编码。
1.2.1经度和纬度的单独编码过程。
经度范围【-180,180】,GeoHash将一个经度编码成一个N位的二进制。
首先对【-180,180】进行N次二分区间操作,N可以自定义。
第一次二分区间:经度范围【-180,180】会被分成两个子区间:【-180,0】和【0,180】(左、右分区),查看编码的经度值落在了哪个区间。落在左区间,就用0表示,落在右区间使用1表示。没做完一次二分区就能得到一个编码值。
然后在对经度值进行N次二次分区,同时再次查看经度值落在了左后分区的那个分区,对照规则再做一次1位编码。做完N次后,经度值就可以用一个N位bit的数来表示。
例子:编码的经度值是【116.37,39.86】,用五位编码值(N=5,做五次分区)
先做第一次二分区操作,把经度区间[-180,180]分成了左分区[-180,0)和右分区[0,180],此时,经度值116.37是属于右分区[0,180],用1表示第一次二分区后的编码值。
做第二次二分区:把经度值116.37所属的[0,180]区间,分成[0,90)和[90,180]。此时,经度值116.37还是属于右分区[90,180],所以,第二次分区后的编码值仍然为1。
等到第三次对[90,180]进行二分区,经度值116.37落在了分区后的左分区[90,135)中,所以,第三次分区后的编码值就是0。
做完5次分区后,我们把经度值116.37定位在[112.5,123.75]这个区间,并且得到了经度值的5位编码值,即11010这个经度116.37编码过程如下表所示:
|
分区次数 |
最小经度值 |
二分后的中间值 |
最大经度值 |
经度116.37所在区间 |
经度GEOHash编码 |
|
第一次分区 |
-180 |
0 |
180 |
【0,180】 |
1 |
|
第二次分区 |
0 |
90 |
180 |
【90,180】 |
1 |
|
第三次分区 |
90 |
135 |
180 |
【90,135】 |
0 |
|
第四次分区 |
90 |
112.5 |
135 |
【90,112.5】 |
1 |
|
第五次分区 |
112.5 |
123.75 |
135 |
【112.5,123.75】 |
0 |
对纬度的分区,跟对经度的是一样的过程,只是纬度的范围是【-90,90】,经过五次分区,得到一个5位bit的编码,纬度39.86编码过程如下:
|
分区次数 |
最小纬度值 |
二分后的中间值 |
最大纬度值 |
纬度39.86所在区间 |
纬度GEOHash编码 |
|
第一次分区 |
-90 |
0 |
90 |
【0,90】 |
1 |
|
第二次分区 |
0 |
45 |
90 |
【0,45】 |
0 |
|
第三次分区 |
0 |
22.5 |
45 |
【22.5,45】 |
1 |
|
第四次分区 |
22.5 |
33.75 |
45 |
【33.75,45】 |
1 |
|
第五次分区 |
33.75 |
39.375 |
45 |
【39.375,45】 |
1 |
当经纬度编码完成后,在把经纬度编码组合起来,组合规则:编码值依次组合,按照下标从1开始排列,纬度只放奇数为下标的位置,经度支行下标为偶数的位置。一个编码放一个位置,最终读出这个组合就可以的得到一个最终的编码。
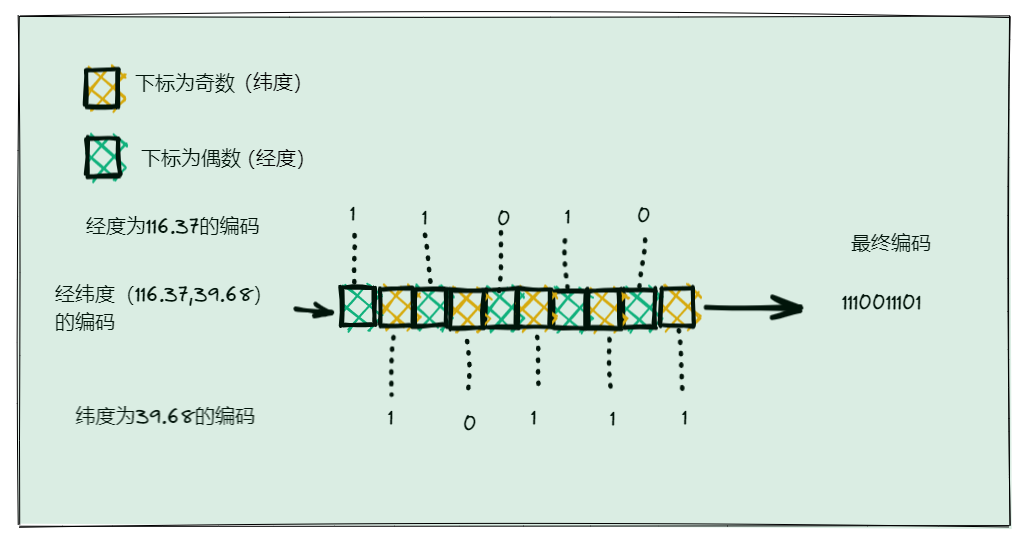
用了GeoHash编码后,原来无法用一个权重分数表示的一组经纬度(116.37,39.86)就可以用1110011101这一个值来表示,就可以保存为Sorted Set的权重分数了。
当然,使用GeoHash编码后,我们相当于把整个地理空间划分成了一个个方格,每个方格对应了GeoHash中的一个分区。
举个例子。我们把经度区间[-180,180]做一次二分区,把纬度区间[-90,90]做一次二分区,就会得到4个分区。我们来看下它们的经度和纬度范围以及对应的GeoHash组合编码。
·分区一:[-180,0)和[-90,0),编码00;
·分区二:[-180,0)和[0,90],编码01;
·分区三:[0,180]和[-90,0),编码10;
·分区四:[0,180]和[0,90],编码11。
这4个分区对应了4个方格,每个方格覆盖了一定范围内的经纬度值,分区越多,每个方格能覆盖到的地理空间就越小,也就越精准。把所有方格的编码值映射到一维空间时,相邻方格的GeoHash编码值基本也是接近的,如下图所示:
两两编码,判断位置,通过最后的跳动,大概确定位置信息
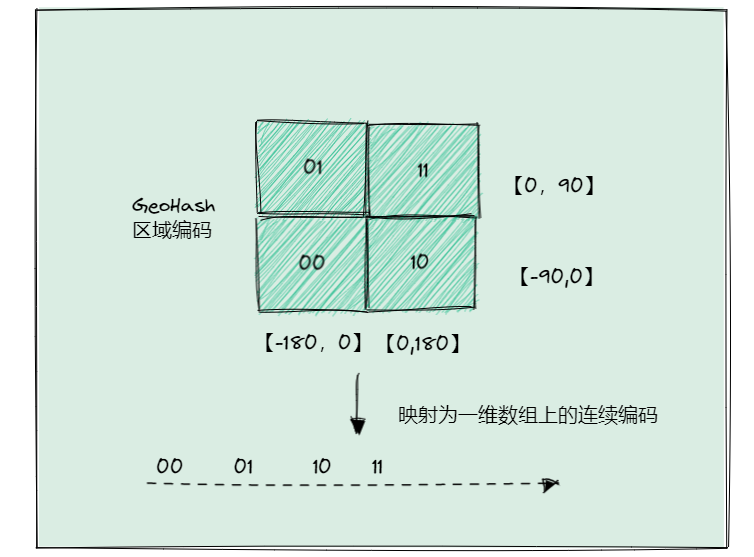
所以使用Sorted Set范围查询可以得到相近编码值,在实际地理位置上,也是相邻的方格,可以实现LBS“搜索附近的人或者车”的功能了。
注意:有些编码值虽然大小很接近,但是实际对应的方格距离较远。为了避免误差,可以同时查询给定经纬度所在方格周围的4个或者8个方格。
GEO类型是把经纬度所在的区间编码作为Sorted Set中元素的权重分数,把和经纬度相关的车辆ID作为Sorted Set中元素本身的值保存下来,这样相邻经纬度的查询就可以通过编码值的大小范围查询来实现了。
1.3如何操作GEO类型
经常使用的命令:GEOADD、GEORADIUS->radius:半径、周围
- GEOADD命令:用于把一组经纬度信息和相对应的一个ID记录到GEO类型集合中;
- GEORADIUS命令:会根据输入的经纬度位置,查找以这个经纬度为中心的一定范围内的其他元素。当然,我们可以自己定义这个范围。
1.3.1添加车辆位置信息:GEOADD
例子:
假设车辆ID是33,经纬度位置是(116.034579,39.030452),我们可以用一个GEO集合保存所有车辆的经纬度,集合key是cars:locations。执行下面的这个命令,就可以把ID号为33的车辆的当前经纬度位置存入GEO集合中:
GEOADD cars:locations 116.034579 39.030452 33
1.3.2查找附近的车辆:GEORADIUS
例如,LBS应用执行下面的命令时,Redis会根据输入的用户的经纬度信息(116.054579,39.030452) ,查找以这个经纬度为中心的5公里内的车辆信息,并返回给LBS应用。当然,你可以修改“5”这个参数,来返回更大或更小范围内的车辆信息。
GEORADIUS cars :locations 116.054579 39.030452 5 km ASC COUNT 10
近一步限制查询条件,限制返回回来的车辆数据信息。
- ACS选项:让返回的车辆信息按照距离这个中心位置从近到远的方式来排序
- COUNT选项:指定返回的车辆信息的数量。数据过多,如果返回全部信息,会占用比较多的数据带宽,这个选项可以帮助控制返回的数据量,节省带宽。
虽然Redis有五种基本数据类型、三种扩展数据类型,但是在特殊场景下,会对特殊数据有特殊要求,基本数据类型已经无法满足要求,假如需要:需要一个数据类型既能像Hash那样支持快速的单键查询,又能像Sorted Set那样支持范围查询。所以就需要自定义数据类型。
2.自定义数据类型
需要想了解RedisObject,Redis每一个数据都保存在RedisObject里边。RedisObject包括元数据和指针。其中,元数据的一个功能就是用来区分不同的数据类型,指针用来指向具体的数据类型的值。所以,要想开发新数据类型,先了解RedisObject的元数据和指针。
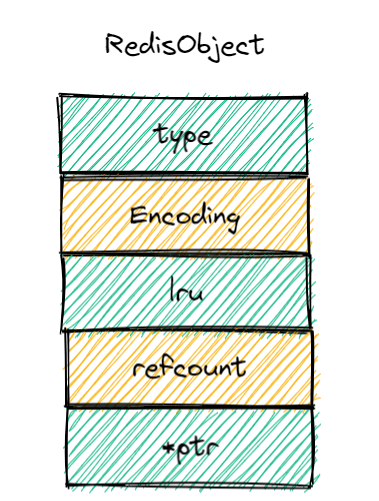
2.1RedisObject的基本对象结构
RedisObject的内部组成包括了type、encoding、Iru和refcount 4个元数据,以及1个*ptr指针。
- type:表示值的类型,涵盖了五大基本类型;
- encoding:是值的编码方式,用来表示Redis中实现各个基本类型的底层数据结构,例如SDS、压缩列表、哈希表、跳表等;
- Iru:记录了这个对象最后一次被访问的时间,用于淘汰过期的键值对;
- refcount:记录了对象的引用计数;
- *ptr:是指向数据的指针。
RedisObject结构借助*ptr指针,就可以指向不同的数据类型,例如,*ptr指向一个SDS或一个跳表,就表示键值对中的值是String类型或Sorted Set类型。所以,定义了新的数据类型后,也只要在RedisObject中设置好新类型的type和encoding,再用*ptr指向新类型的实现。
2.2新的数据类型开发

开发一个NewTypeObject
第一步:定义新类型和底层数据结构
用newtype.h文件来保存这个新类型的定义,具体定义的代码如下所示:
struCt NewTypeObject {
struct NewTypeNode *head ;
size_t len;
}NewTypeobject;
其中,NewTypeNode结构就是自定义的新类型的底层结构。
为底层结构设计两个成员变量:一个是Long类型的value值,用来保存实际数据;一个是*next指针,指向下一个NewTypeNode结构。
struct NewTypeNode {
long value;
struct NevwTypeNode *next;
};

第二步:在RedisObject中增加新类型的定义
这个定义是在Redis的server.h文件中。比如增加一个叫作OBJ_NEWTYPE的宏定义,用来在代码中指代NewTypeObject这个新类型。
#define OBJ_STRINGO
/* String object. */
#define OBJ_LIST1
/* List object. */
#define OBJ_SET 2
/* set object.*/
#define OBJ_ZSET 3
/* sorted set object. */
#define OBJ_NEWTYPE 7第三步:开发新类型的创建和释放函数
Redis把数据类型的创建和释放函数都定义在了object.c文件中。所以,可以在这个文件中增加NewTypeObject的创建函数createNewTypeObject,如下所示:
robj* createNewTypeobject( void){
NewTypeobject *h = newtypeNew( );
robj *o = ereateobject(0BJ_NEWTYPE,h);
return o;
}先说newtypeNew函数。它是用来为新数据类型初始化内存结构的。这个初始化过程主要是用zmalloc做底层结构分配空间,以便写入数据。
NewTypeobject *newtypeNew(void){
NewTypeobject*n = zmallocn->head =NULL;
n->len=0;
return n;
}newtypeNew函数涉及到新数据类型的具体创建,而Redis默认会为每个数据类型定义一个单独文件,实现这个类型的创建和命令操作,例如,t_string.c和t_list.c分别对应String和List类型。按照Redis的惯例,我们就把newtypeNew函数定义在名为t_newtype.c的文件中。
createObject是Redis本身提供的RedisObject创建函数,它的参数是数据类型的type和指向数据类型实现的指针*ptr。
我们给createObject函数中传入了两个参数,分别是新类型的type值OBJ_NEWTYPE,以及指向一个初始化过的NewTypeObjec的指针。这样一来,创建的RedisObject就能指向我们自定义的新数据类型了。
robj *createobject(int type, void *ptr) {
robj *o = zmalloc( sizeof(*o));
0- >type = type ;
0->ptr = ptr;
...
return o;
}对于释放函数来说,它是创建函数的反过程,是用zfree命令把新结构的内存空间释放掉。
第四步:开发新类型的命令操作
简单来说,增加相应的命令操作的过程可以分成三小步:
1.在t_newtype.c文件中增加命令操作的实现。比如说,我们定义ntinsertCommand函数,由它实现对NewTypeObject单向链表的插入操作:
void ntinsertcommiand(client *C{
//基于客户端传递的参数,实现在NewTypeobject链表头插入元素
}2.在server.h文件中,声明我们已经实现的命令,以便在server.c文件引用这个命令,例如:
void ntinsertCommand(client *c)3.在server.c文件中的redisComnmandTable里面,把新增命令和实现函数关联起来。例如,新增的ntinsert命令由ntinsertCommand函数实现、就可以用ntinsert命令给NewTypeObject数据类型插入元素了。
struct rediscommanarediscommandTable[] ={
...
( "ntinsert" , ntinsertCommand, 2, "m"",..)
}完成了一个自定义的NewTypeObject数据类型,可以实现基本的命令操作了。如果你还希望新的数据类型能被持久化保存,还需要在Redis的RDB和AOF模块中增加对新数据类型进行持久化保存的代码.
3.总结
Redis扩展数据类型:BitMap,HyperLogLog,GEO之GEO。有效的解决了LBS中查找相邻位置的人和车的问题。GEO可以记录经纬度形成的地理位置,广泛引用在LBS。GEO本身没有新的数据结构,是直接使用了Sorted Set集合类型。
GEO类型使用GeoHash编码方法实现了经纬度到Sorted Set中元素权重分数的转换,其中两个关键机制:二维地图做区间规划、区间编码。经纬度落到某区间,使用区间编码值表示,并使用编码值作为Sorted Set的权重分数。经纬度保存到Sorted Set 其数据特点“按权重进行有序范围查找”的特性,实现LBS服务频繁使用“附件搜索”需求。
GEO属于Redis提供的扩展数据类型。扩展数据类型有两种实现途径:一种是基于现有的数据类型,通过数据编码或是实现新的操作的方式,来实现扩展数据类型,例如基于Sorted Set和GeoHash编码实现GEO,以及基于String和位操作实现Bitmap;另一种就是开发自定义的数据类型,具体的操作是增加新数据类型的定义,实现创建和释放函数,实现新数据类型支持的命令操作。
其他数据结构?
5大基本数据类型,以及三种扩展数据类型:HyperLogLog、Bitmap、GEO,Redis还有一种数据叫作布隆过滤器。它的查询效率很高,经常会用在缓存场景中,可以用来判断数据是否存在缓存中。
Redis保存时间序列数据
需求:记录用户在网站或者App上的点击行为数据,来分析用户行为。
这里的数据一般包括用户ID、行为类型(例如浏览、登录、下单等)、行为发生的时间戳:
UserID,Type,TimeStamp时间序列数据:与发生时间相关的一组数据。这些数据的特点是没有严格的关系模型,记录的信息可以表示成键和值的关系〈例如:一个设备ID对应一条记录),所以,并不需要专门用关系型数据库(例如MySQL)来保存。可以使用Redis的键值数据模型。
1.时间序列读写特点
1.1时间序列写特点
在实际应用中,时间序列数据通常是持续高并发写入(例如:需要连续记录万个设备的实时状态)。并且,时间序列一弹写入就不会改变,不存在更新数据的操作(例如:一个设备某时刻的温度被记录下来,一旦记录,就不会改变)。
时间序列数据写入特点简单,只需要插入数据块,所以选择复杂度低,而且尽量不堵塞的数据类型。String跟Hash的插入时间复杂度都是O (1),但是String在数据量大的时候,元数据内存开销较大。
应对方式:对于时间序列数据需要“写得快”,Redis的高性能写特点可满足
1.2时间序列读特点
时间序列读数据(查询模式较多):1.单条数据查询(某一时刻设备的状态)2.多条数据查询(某个时间范围数据查询。早上八点到十点的设备状态)3.对符合条件的数据聚合查询(均值,最大值,最小值)
应对方式:针对查询模式多,需要支持单点查询,范围查询,聚合计算。两种保存时间序列方案基于Hash和Sorted Set实现和基于RedisTimeSeries实现。
2.基于Hash和Sorted Set保存时间序列
Hash和Sorted Set 组合存储,属于Redis的基本数据类型:代码成熟,性能稳定。确保系统的稳定性
保存时间序列为什么要同时使用:Hash和Sorted Set
为了满足范围查询和单点查询
2.1Hash保存时间序列
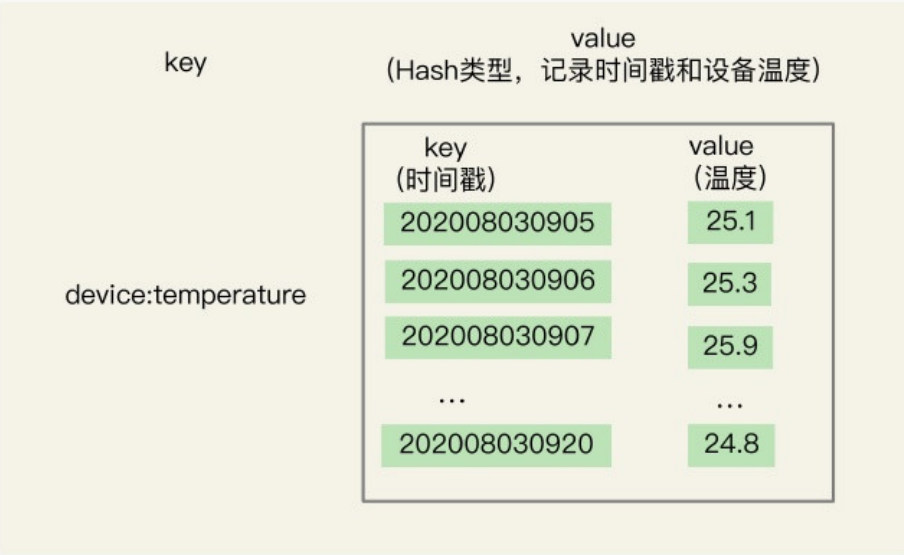
Hash特点:单键值快速查询,可以满足时间序列的单点查询。时间戳 可以记为key,设备状态可记录为value。
Hash集合记录设备问题值示意图:
直接使用HGet或者HMGet就可以获得一个key或者多个keyd的集合。
举个例子。我们用HGET命令查询202008030905这个时刻的温度值,使用HMGET查询202008030905.202008030907、202008030908这三个时刻的温度值,如下所示:
HGET device:temperature 202008030905
"25.1"
HMGET device:temperature 202008030905 202008030907 202008030908
1)"25.1"
2)"25.9"
3)“24.9"Hash存储值缺点:不支持范围查询
时间序列是按照时间递增插入数据的,但是Hash底层是哈希表(哈希表底层:数组+链表+红黑树),没有对数据进行有序索引。Hash需要范围查询,必须进行全查,把符合规则数据返回到客户端排序,才能查客户端得到想要的数据,查询效率低。
2.1Sorted Set保存时间序列
所以使用Hash和Sorted Set组合存储,Sorted Set负责解决范围查询的问题,可以根据元素的权重分数来排序。
时间戳为元素分数,时间点上记录的数据作为元素本身。
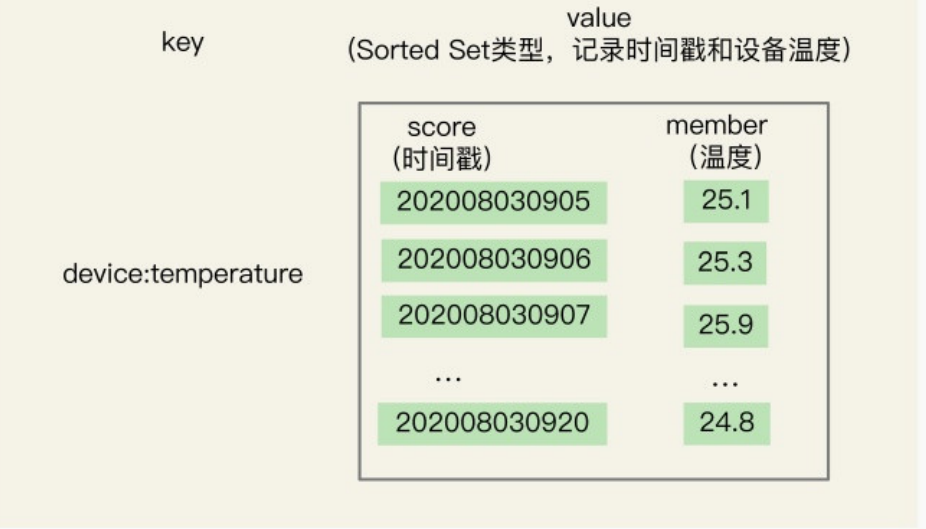
使用Sorted Set保存数据后,我们就可以使用ZRANGEBYSCORE命令,按照输入的最大时间戳和最小时间戳来查询这个时间范围内的温度值了。如下所示,我们来查询一下在2020年8月3日9点7分到9点10分间的所有温度值:
ZRANGEBYSCORE device:temperature 202008030907 202008030910
1)"25.9"
2)"24.9"
3)"25.3"
4)"25.2"如何满足写入Hash和Sorted Set是一个原子性操作问题?
原子性操作:指进行多个操作时(使用Hset和Sadd分别把数据写入Hash和Sorted Set),操作要么全部完成,要么全部不完成。
数据一致性才能保证查询到到的数据不会出错。
2.3Redis保证原子性操作
Redis简单事务的实现:MULIT和EXEC命令。
当多个命令且保证数据无误的时候,MULIT和EXEC可以保证执行这些命令的原子性。
- MULIT(mulit)命令: 表示一些列原子性操作的开始。收到这个命令,Redis会将之后的命令放在一个内部队列里,后续一起执行,保证原子性。
- EXEC命令:表示一系列原子性操作的结束。收到这个命令,表示所有需要保证原子性命令的操作都已经发送完毕。Redis开始执行,刚刚放到内部队列里的所有命令操作。
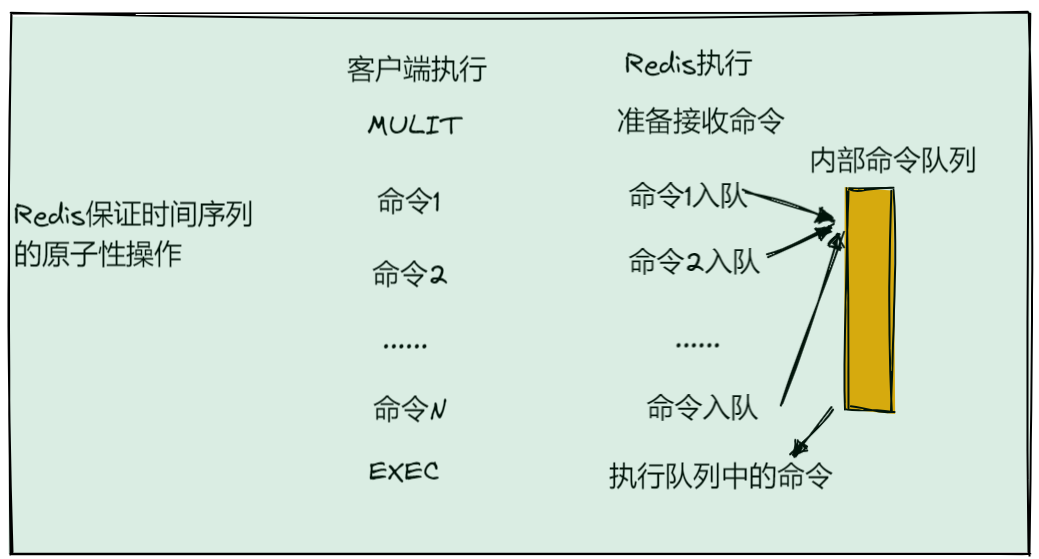
以保存设备状态信息的需求为例,把设备在2020年8月3日9时5分的温度,分别用HSET命令和ZADD命令写入Hash集合和Sorted Set集合。
127.0.0.1:6379> MULIT
127.0.0.1:6379> HSET device:temperature 202008030911 26.8
QUEUED
127.0.0.1:6379> ZADD device:temperature 202008030911 26.8
QUEUED
127.0.0.1:6379> EXEC
1)(integer)1
2)(integer)1
3.RedisTimeSeries保存时间序列
聚合计算一般被用来周期性地统计时间窗口内的数据汇总状态,在实时监控与预警等场景下会频繁执行。
Sorted Set 支持范围查询,不能进行聚合统计,需要把数据拿到客户端,客户端自行完成聚合计算。风险:
大量数据在Redis和客户端之间传输,会与其他命令抢网络资源,导致其他资源变慢。
假设我们需要每3分钟计算一次的所有设备各指标的最大值,每个设备每15秒记录一个指标值,1分钟就会记录4个值,3分钟就会有12个值。我们要统计的设备指标数量有33个,所以,单个设备每3分钟记录的指标数据有将近400个(33*12=396),而设备总数量有1万台,这样一来,每3分钟就有将近400万条 (3961万=396万)数据需要在客户端和Redis实例间进行传输。
避免大量数据在Redis和客户端之间传输,时间序列进行聚合统计?
RedisTimeSeries保存时间序列,为了实现时间序列聚合统计。
RedisTimeSeries支持直接在Redis实例上进行聚合计算。
每3分钟计算一次所有设备各指标的最大值,直接聚合,三分钟记录12条数据聚合成
一个值
,单个设备每三分钟指标数量33条数,一万台三分钟只有33万条数据。数据量大量减少,同时减少数据传输对Redis实例网络性能的影响。
所以大量数据,网络贷款条不太好,使用RedisTimeSeries存储数据。个时间点查询或是对某个时间范围查询,使用Hash和Sorted Set的组合,它们都是Redis的内在数据结构,性能好,稳定性高
RedisTimeSeries是Redis的一个扩展模块。它
为时间序列提供了专门的数据类型和接口,
并且
可以按时间范围在Redis实例上对数据进行聚合计算
因为RedisTimeSeries不属于Redis的内建功能模块,在使用时,我们需要先把它的源码单独编译成动态链接库redistimeseries.so,再使用loadmodule命令进行加载,如下所示:
loadmodule redistimeseries.so当用于时间序列数据存取时,RedisTimeSeries的操作主要有5个:
- 用TS.CREATE命令创建时间序列数据集合;
- 用TSADD命令插入数据;
- 用TS.GET命令读取最新数据;
- 用TSMGET命令按标签过滤查询数据集合;
- 用TSRANGE支持聚合计算的范围查询。
3.1用TS.CREATE命令创建时间序列数据集合;
设置时间序列key,数据过期时间(毫秒),数据集合标签(表示数据集合属性)
例如,我们执行下面的命令,创建一个key为device:temperature、数据有效期为600s的时间序列数据集合。也就是说,这个集合中的数据创建了600s后,就会被自动删除。最后,我们给这个集合设置了一个标签属性{ideviceid:1},表明这个数据集合中记录的是属于设备ID号为1的数据。
TSCREATE device:temperature RETENTION 600000 LABELS device_id 1
oK
3.2用TS.ADD命令插入数据;
插入数据key,时间戳,具体数据
TS.ADD device:temperature 1596416700 25.1
1596416700
3.3用TS.GET命令读取最新数据;
读取数据最新的一条数据
TS.GET device:temperature
25.1
3.4用TS.MGET命令按标签过滤查询数据集合;
在保存多个设备的时间序列数据时, 通常会把不同设备的数据保存到不同集合中(设备id),输入筛选条件筛选数据。可以使用TS.MGET命令,按照标签查询部分集合中的最新数据。在使用TS.CREATE创建数据集合时, 可以给集合设置标签属性。进行查询时,就可以在查询条件中对集合标签属性进行匹配,最后的查询结果里只返回匹配上的集合中的最新数据。
举个例子。假设我们一共用4个集合为4个设备保存时间序列数据,设备的ID号是1、2、3、4,我们在创建数据集合时,把device id设置为每个集合的标签。此时,我们就可以使用下列TS.MGET命令,以及FILTER设置(这个配置项用来设置集合标签的过滤条件),查询device_id不等于2的所有其他设备的数据集合,并返回各自集合中的最新的一条数据。
TS.MGET FILTER device_id!=2
1)
1)"device:temperature:1"
2) (empty list or set)
3) 1)(integer) 1596417000
2)"25.1"
2)
1) "device:temperature:3"
2) (empty list or set)
3) 1) (integer) 1596417000
2)"29.5"
3)
1) "device:temperature:4"
2) (empty list or set)
3) 1)(integer) 1596417000
2)"30.1"
3.5用TS.RANGE支持聚合计算的范围查询
指定要查询的数据的时间范围,同时可以使用用AGGREGATION参数指定要执行的聚合计算类型。RedisTiimeSeries支持的聚合计算类型很丰富,包括求均值(avg)、求最大/最小值(max/min),求和(sum)
例如,在执行下列命令时,我们就可以按照每180S的时间窗口,对2020年8月3日9时5分和2020年8月3日9时12分这段时间内的数据进行均值计算了
TS.RANGE device:temperature 1596416700 1596417120 AGGREGATION avg 180000
1) 1) (integer) 159641
2)"25.6"
2) 1) (integer
2)"25.8"
3) 1) (inteye1596417060
2) "26.1"
4.时间序列存储总结:
Redis保存时间序列的方式:时间序列数据的写入——》快速写入,查询方式有三种:
- 点查询,一个时间戳,查询相应数据。
- 范围查询,查询起始和截止时间范围内的数目。
- 聚合计算,针对起始和截止时间的范围数据进行计算,最大值,最小值,求均值等。
处理方式:
关于快速写入的要求,Redis的高性能写特性足以应对了;
而针对多样化的查询需求,Redis提供了两种方案。
第一种方案是,组合使用Redis内置的Hash和Sorted Set类型,把数据同时保存在Hash集合和Sorted Set集合中。这种方案既可以利用Hash类型实现对单键的快速查询,还能利用Sorted Set实现对范围查询的高效支持。实现了两种查询方式。
第一种方案也有两个不足:一个是,在执行聚合计算时,我把数据读取到客户端再进行聚合,当有大量数据要聚合时,数据传输开销大;另一个是,所有的数据会在两个数据类型中各保存一份,内存开销不小。不过,可以通过设置适当的数据过期时间,释放内存,减小内存压力。
第二种实现方案是使用RedisTimeSeries模块。这是专门为存取时间序列数据而设计的扩展模块。和第一种方案相比,RedisTimeSeries能支持直接在Redis实例上进行多种数据聚合计算,避免了大量数据在实例和客户端间传输。
第二种的缺点:RedisTimeSeries的底层数据结构使用了链表,它的范围查询的复杂度是O(N)级别的,同时,它的TS.GET查询只能返回最新的数据,没有办法像第一种方案的Hash类型一样,可以返回任一时间点的数据。
所以,组合使用Hash和Sorted Set,或者使用RedisTimeSeries,在支持时间序列数据存取上各有优劣势。我给你的建议是:
- 部署环境中网络带宽高、Redis实例内存大,可以优先考虑第一种方案,
- 部署环境中网络、内存资源有限,而且数据量大,聚合计算频繁,需要按数据集合属性查询,可
以优先考虑第二种方案。
问题:在用Sorted Set保存时间序列数据时,如果把时间戳作为score,把实际的数据作为member,这样保存数据有没有潜在的风险?另外,如果你是Redis的开发维护者,你会把聚合计算也设计为Sorted Set的一个内在功能吗?
答案:Sorted Set和Set一样,都会对集合中的元素进行去重,也就是说,如果我们往集合中插入的
member值,和之前已经存在的member值一样,那么,原来member的score就会被新写入的member的score覆盖。相同member的值,在Sorted Set中只会保留一个。
对于时间序列数据来说,这种去重的特性是会带来数据丢失风险的。毕竟,某一时间段内的多个时间序列数据的值可能是相同的。如果我们往Sorted Set中写入的数据是在不同时刻产生的,但是写入的时刻不同,Sorted Set中只会保存一份最近时刻的数据。这样一来,其他时刻的数据就都没有保存下来。
举个例子,在记录物联网设备的温度时,一个设备一个上午的温度值可能都是26。在Sorted Set中,我们把温度值作为member,把时间戳作为score。我们用ZADD命令把上午不同时刻的温度值写入Sorted Set。由于member值一样,所以只会把score更新为最新时间戳,最后只有一个最新时间戳(例如上午12点)下的温度值。这肯定是无法满足保存多个时刻数据的需求的。
关于是否把聚合计算作为Sorted Set的内在功能,考虑到Redis的读写功能是由单线程执行,在进行数据读写时,本身就会消耗较多的CPU资源,如果再在Sorted Set中实现聚合计算,就会进一步增加CPU的资源消耗,影响到Redis的正常数据读取。所以,如果我是Redis的开发维护者,除非对Redis的线程模型做修改,比如说在Redis中使用额外的线程池做聚合计算,否则,我不会把聚合计算作为Redis的内在功能实现的。