分析文件类型
看题目以为会是一个pyc文件让反编译,结果是一个不能识别的后缀名,直接丢进WinHex看标识,ascll为python语法所以是一个python文件,修改后缀名为.py
算法分析
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import marshal, zlib, base64
exec(marshal.loads(zlib.decompress(base64.b64decode('eJyNVktv00AQXm/eL0igiaFA01IO4cIVCUGFBBJwqRAckLhEIQmtRfPwI0QIeio/hRO/hJ/CiStH2M/prj07diGRP43Hs9+MZ2fWMxbnP6mux+oK9xVMHPFViLdCTB0xkeKDFEFfTIU4E8KZq8dCvB4UlN3hGEsdddXU9QTLv1eFiGKGM4cKUgsFCNLFH7dFrS9poayFYmIZm1b0gyqxMOwJaU3r6xs9sW1ooakXuRv+un7Q0sIlLVzOCZq/XtsK2oTSYaZlStogXi1HV0iazoN2CV2HZeXqRQ54TlJRb7FUlKyUatISsdzo+P7UU1Gb1POdMruckepGwk9tIXQTftz2yBaT5JQovWvpSa6poJPuqgao+b9l5Aj/R+mLQIP4f6Q8Vb3g/5TB/TJxWGdZr9EQrmn99fwKtTvAZGU7wzS7GNpZpDm2JgCrr8wrmPoo54UqGampFIeS9ojXjc4E2yI06bq/4DRoUAc0nVnng4k6p7Ks0+j/S8z9V+NZ5dhmrJUM/y7JTJeRtnJ2TSYJvsFq3CQt/vnfqmQXt5KlpuRcIvDAmhnn2E0t9BJ3SvB/SfLWhuOWNiNVZ+h28g4wlwUp00w95si43rZ3r6+fUIEdgOZbQAsyFRRvBR6dla8KCzRdslar7WS+a5HFb39peIAmG7uZTHVm17Czxju4m6bayz8e7J40DzqM0jr0bmv9PmPvk6y5z57HU8wdTDHeiUJvBMAM4+0CpoAZ4BPgJeAYEAHmgAUgAHiAj4AVAGORtwd4AVgC3gEmgBBwCPgMWANOAQ8AbwBHgHuAp4D3gLuARwoGmNUizF/j4yDC5BWM1kNvvlxFA8xikRrBxHIUhutFMBlgQoshhPphGAXe/OggKqqb2cibxwuEXjUcQjccxi5eFRL1fDSbKrUhy2CMb2aLyepkegDWsBwPlrVC0/kLHmeCBQ=='))))
导入了三个模块,将base64字符串解密后执行
- marshal:提供了一种将 Python 对象序列化和反序列化的方式,序列化是将对象转换为字节流以便存储或传输的过程,而反序列化是从字节流创建对象的反向过程。dumps为序列化,loads为反序列化
- zlib:Python 内置的压缩库,提供了压缩和解压缩数据的功能。它基于 DEFLATE 压缩算法,可以在压缩数据的同时保持数据的完整性。compress为压缩,decompress为解压缩
- base64: Python 内置的编码和解码二进制数据的库。b64encode为加密函数,b64decode为解密函数
-
exec:既可以执行python语句,又可以执行编译后的字节串
loads加载的数据若不是同一版本的python解释器产生的会报错,我这里就这种情况
构建pyc文件
看其他师傅wp说exec中的字节串为python虚拟机的可执行二进制码,所以可以直接将其作为pyc文件,然后用工具还原源代码,chatgpt按理应该可以直接将二进制码还原的,不过我没弄出来,还是走pyc文件的路吧
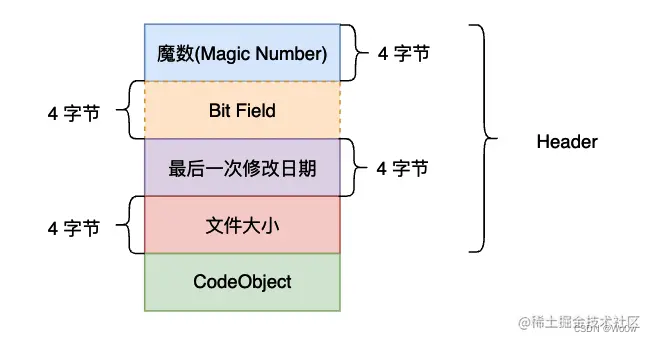
在此之前我们要清楚pyc文件结构:(python3)
- 文件头:占十六字节
- 机器码:文件头之后区域
-
python2:只有八个字节的文件头,为魔数和时间
用以下代码将解压缩字节串写入新建文件
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import marshal, zlib, base64
f =open('my.pyc','wb')
pyc =zlib.decompress(base64.b64decode('eJyNVktv00AQXm/eL0igiaFA01IO4cIVCUGFBBJwqRAckLhEIQmtRfPwI0QIeio/hRO/hJ/CiStH2M/prj07diGRP43Hs9+MZ2fWMxbnP6mux+oK9xVMHPFViLdCTB0xkeKDFEFfTIU4E8KZq8dCvB4UlN3hGEsdddXU9QTLv1eFiGKGM4cKUgsFCNLFH7dFrS9poayFYmIZm1b0gyqxMOwJaU3r6xs9sW1ooakXuRv+un7Q0sIlLVzOCZq/XtsK2oTSYaZlStogXi1HV0iazoN2CV2HZeXqRQ54TlJRb7FUlKyUatISsdzo+P7UU1Gb1POdMruckepGwk9tIXQTftz2yBaT5JQovWvpSa6poJPuqgao+b9l5Aj/R+mLQIP4f6Q8Vb3g/5TB/TJxWGdZr9EQrmn99fwKtTvAZGU7wzS7GNpZpDm2JgCrr8wrmPoo54UqGampFIeS9ojXjc4E2yI06bq/4DRoUAc0nVnng4k6p7Ks0+j/S8z9V+NZ5dhmrJUM/y7JTJeRtnJ2TSYJvsFq3CQt/vnfqmQXt5KlpuRcIvDAmhnn2E0t9BJ3SvB/SfLWhuOWNiNVZ+h28g4wlwUp00w95si43rZ3r6+fUIEdgOZbQAsyFRRvBR6dla8KCzRdslar7WS+a5HFb39peIAmG7uZTHVm17Czxju4m6bayz8e7J40DzqM0jr0bmv9PmPvk6y5z57HU8wdTDHeiUJvBMAM4+0CpoAZ4BPgJeAYEAHmgAUgAHiAj4AVAGORtwd4AVgC3gEmgBBwCPgMWANOAQ8AbwBHgHuAp4D3gLuARwoGmNUizF/j4yDC5BWM1kNvvlxFA8xikRrBxHIUhutFMBlgQoshhPphGAXe/OggKqqb2cibxwuEXjUcQjccxi5eFRL1fDSbKrUhy2CMb2aLyepkegDWsBwPlrVC0/kLHmeCBQ=='))
print(pyc)
f.write(pyc)
给文件添加文件头,由于不知道原机器码版本,所以python2,python3文件头都可以试试
winhex->edit->paste zero bytes:新添加字节会被设为0
pyc反汇编
可能是魔数不对,不能直接被还原出源码,但可以用pycdas进行反汇编,
一千行有点难顶
两千行!,没法直接输入给chatgpt了(噩梦的开始,这道题越到后面带给我的问题越多)
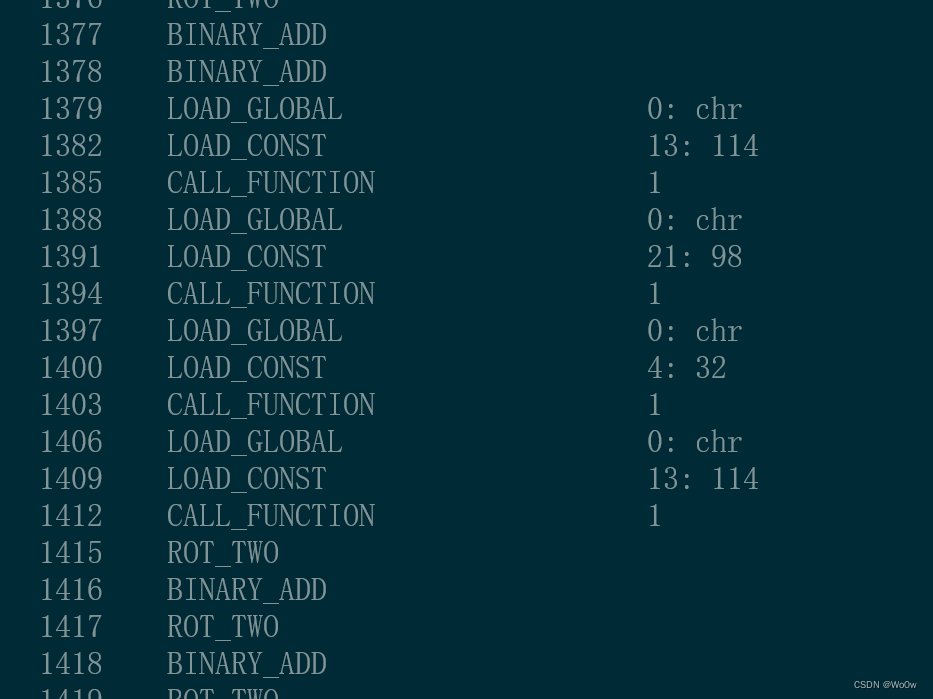
狂补字节码知识:
-
https://www.yuque.com/zhao.ming.tai.zi/ksmo0g/trma9l/edit
师傅们的意思是模拟VM的运行,让字节码跑完,将途中遇到的所有字符串保留下来且输出,由于是逐行运行的所以不会跳过不符合的情况
沐师傅的wp,VM果然对我来说还是有点难?
def BINARY_ADD(list1): # 模拟BINARY_ADD相加操作
top1=list1.pop()
top2=list1.pop()
list1.append(top2+top1)
def ROT_TWO(list1): # 模拟ROT_TWO交换操作
top1=list1.pop()
top2=list1.pop()
list1.append(top1)
list1.append(top2)
with open('3.py','r') as fd: # 将代码中的内容读取进来
lines=fd.readlines()
list1=[]
for line in lines: # 遍历每一行
if "LOAD_CONST" in line: # 包含LOAD_CONST
line = line.split()[-1] # 在每行中根据空格划分子字符串,总是赋值最后一个元素
if line.isdigit(): # 如果是数字的话直接添加该字符
list1.append(chr(int(line)))
else:
list1.append(0) # 如果不是数字的话,栈中添0。代码333行中出现了None,即添加空字符常量
else:
if "BINARY_ADD" in line: # 如果包含BINARY_ADD,就执行相加操作
BINARY_ADD(list1)
elif "ROT_TWO" in line: # 如果包含ROT_TWO,就执行交换操作
ROT_TWO(list1)
print(list1)
hitcon{Now you can compile and run Python bytecode in your brain!}
参考链接:
https://blog.csdn.net/xiao__1bai/article/details/120568154
https://blog.csdn.net/m88997766/article/details/129829565