原博客地址:http://blog.csdn.net/w412692660/article/details/49308921
Flume
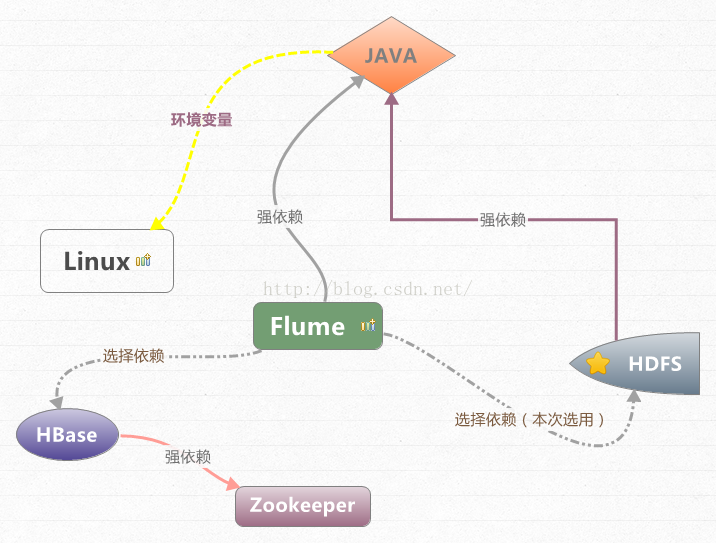
依赖关系:
JDK :Flume
源码程序是由
Java
平台编制而成,故此对
JDK
有强制依赖。
HDFS :flume
监听日志文件变化,将日志程序写入存储介质
HDFS
Hbase
:
与
HDFS
同属存储介质,用于实时查询,
flume
可藉由
zookeeper
获取
HBASE
访问实例
本次项目
flume
的职责要求:
flume
是收集日志的开源软件解决方案之一,相对于其他同类软件他具有高可用的,高可靠的,分布式等特性,对于分布式日志采集有得天独厚的优势。
此次项目中
flume
是承上启下的作用,上游为
Python
程序分割本服务器日志,下游为将日志存储
HDFS
,期间确保数据安全性及整体应用可用性,故此我们需要在每台日志收集的服务器中安装
flume
程序和
python
分割程序,如下图所示:
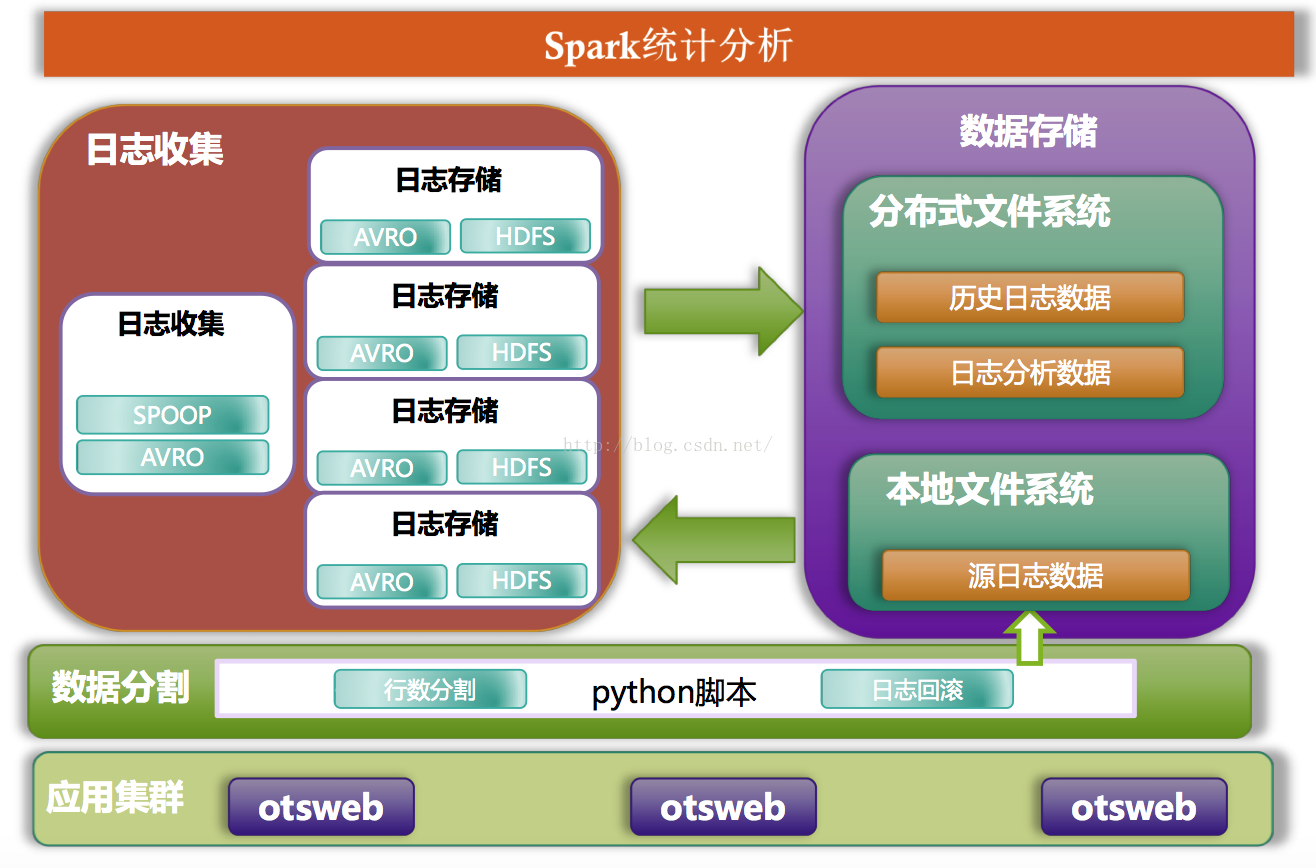
日志收集工作流程是
1.OTSWEB
生成相关日志信息,可按小时、天等(现阶段是按天)
2.PYTHON
日志分割程序,依据文件行数对
OTSWEB
日志实施分割为多个文件,同时写入
flume
客户端侦测的文件夹中
3.flume
客户端侦测文件夹变化,对新增文件读取,并提交至其他服务器的
flume
日志存储模块
4.flume
日志存储模块将收到的日志整合,按
5
分钟为时限将日志数据写入
HDFS
日志模块可参考下图所示:
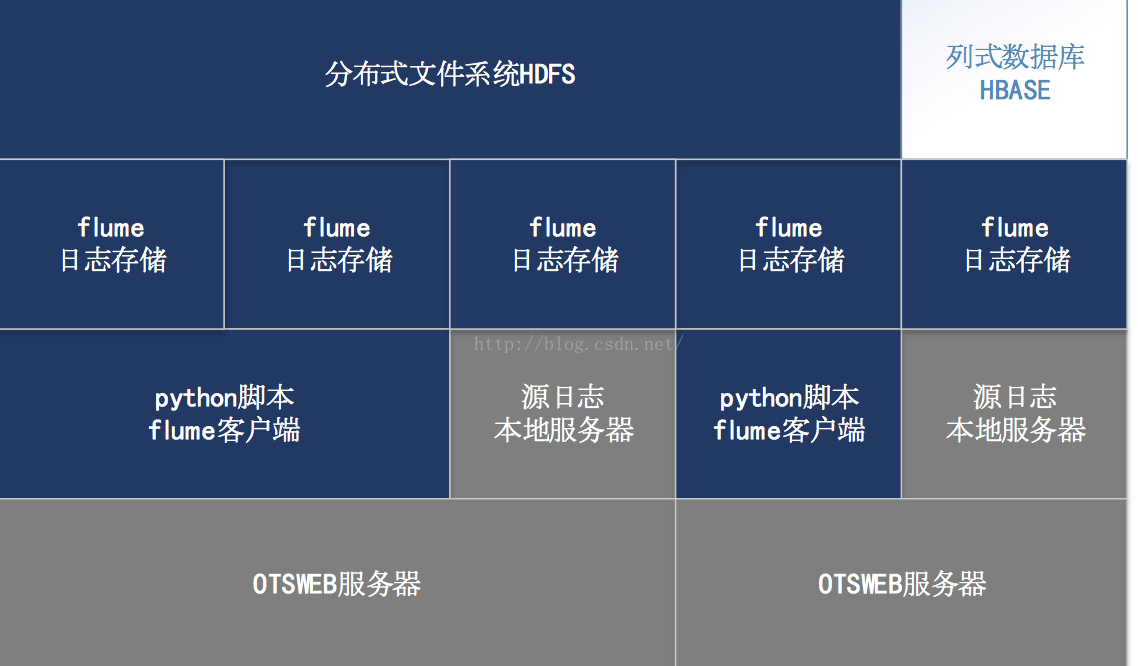
(蓝色
–
我方应用,灰色
–
依赖软件,白色
–
后续扩展)
Flume
程序安装:
依据服务器客观条件,我们应先检测是否有安装
JDK
以及
CDH
,如上述软件已安装完毕,则将软件包解压放置相关目录下。
解压后目录:
bin目录
:
放置
flume
的启动命令文件。(flume-ng)
conf目录:放置
flume
核心的配置文件,包括
flume
工作脚本(flume-conf.properties用于定制个性化日志收集,主要工作内容)、
flume
运行信息(flume-env.sh用于配置
JDK
等信息)、
flume
日志管理(log4j.properties用于配置
log4j
信息)
Cloudera目录:用于放置
CDH
管理
flume
信息,可以暂时忽略不计,独立
flume
运行,不依赖此包内容
docs目录:是记录
flume
参考文档
lib
目录:是
flume
运行依赖类库
tools目录:是配置log4j直接输出日志到flume集成配置使用的相关
jar
包
(
我们非是使用此种方式,亦可忽略不计
)
我们需要配置的内容相对简单,仅需要两步骤操作:
一、配置环境变量
vim /etc/profile
#flume
export FLUME_HOME=/home/grid/flume/apache-flume-xxx-bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
source /etc/profile
二、配置
conf/
flume-conf.properties
(
核心
)
配置
conf/
flume-conf.properties是我们工作的核心,也是
flume
需要我们定制个性化服务的支撑点。
配置源一个
JOB
,通常称之为
agent
,其主要包括三个部分,分别是数据入口(sources)、管道(channels)、数据出口(
sink
)
数据入口(sources)
:
配置数据源信息,我们主要使用SpoolingDirectory Source和Avro Source,其他支持包括Exce Source、NetCat Source、SyslogSource、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source,etc。
管道(channels):保障数据的传输高可用及高可靠,有两种分别是基于内存及硬盘,我们为了保证其安全、稳定则使用基于硬盘传输,支持断点续传等功能
数据出口(
sink
):配置数据最终的存储位置,我们主要使用HDFSSink和Avro Sink,其他支持包括Logger Sink、Thrift Sink、IRC Sink、File Roll Sink、NullSink、HBaseSinks、HBaseSink、AsyncHBaseSink、MorphlineSolrSink、ElasticSearchSink、CustomSink
flume-conf配置:
我们使用
flume
主要包括两个部分
agent
完成数据的对接工作,分别是
flume
客户端及
flume
日志存储。
flume
客户端负责
收集
otsweb
应用端的日志,与
otsweb
应用为一对一的关系,强依赖于
otsweb
应用。(
flume
客户端与
python
程序安装于
otsweb
应用服务器)
flume
日志存储
是将
flume
客户端的日志存储到
HDFS
中,同时依据相关配置信息完成文件传输及存储,
flume
客户端与
flume
日志存储是一对多的关系,此方式可以保证并行存储至
HDFS
,不会受到
HDFS
管道流写入的限制。

flume
客户端配置文件(flume-conf.properties):
# TODO
定义数据入口(sources)、管道(channels)、数据出口(
sink
)
#
定义数据入口(sources)
a1.sources= r1
#
定义两个数据出口(
sink
),此处
sink
数量是与
flume
日志存储数据相呼应,暂定为两个
SINK
a1.sinks= k1 k2
#
定义管道(channels)
a1.channels= c1
#
TODO
配置数据入口(sources)
#
定义数据源类型为监听文件夹
a1.sources.r1.type= spooldir
#
配置对接管道
a1.sources.r1.channels= c1
#
监听目录
a1.sources.r1.spoolDir= /home/grid/jboss/source
#
定义读取至管道后,删除源文件
a1.sources.r1.deletePolicy= immediate
#
定义两个拦截器,分别是添加时间戳和主机名
a1.sources.r1.interceptors=i1 i2
#
定义拦截器为HostInterceptor
a1.sources.r1.interceptors.i1.type= host
#
主机名赋值,此处也可以写其他的
a1.sources.r1.interceptors.i1.hostHeader= host
#
定义拦截器为TimestampInterceptor,默认会向
head
添加时间戳,后续
flume
日志上传的
conf
文件的
HDFS
时间则来源于此
a1.sources.r1.interceptors.i2.type= timestamp
#
TODO
数据出口(
sink
)
#
定义类型为
AVRO
方式,使用
RPC
方式调用,故此需要端口号
a1.sinks.k1.type= avro
#
配置对接管道
a1.sinks.k1.channel= c1
# flume
日志上传的
flume
组件的
host
a1.sinks.k1.hostname= my1
# flume
日志上传的
flume
组件的端口(与其
flume
日志上传的sources相呼应)
a1.sinks.k1.port= 4141
#
定义类型为
AVRO
方式,使用
RPC
方式调用,故此需要端口号
a1.sinks.k2.type= avro
#
配置对接管道
a1.sinks.k2.channel= c1
# flume
日志上传的
flume
组件的
host
a1.sinks.k2.hostname= my2
# flume
日志存储的
flume
组件的端口(与其
flume
日志存储的sources相呼应)
a1.sinks.k2.port= 4141
# TODO
配置
SINK
组,能够完成数据一个组内数据均衡发送效果
#
定义组名
a1.sinkgroups= g1
#
定义分组的
SINK
a1.sinkgroups.g1.sinks= k1 k2
#
负载均衡
a1.sinkgroups.g1.processor.type= load_balance
#
发生冲突时的强制性重传
a1.sinkgroups.g1.processor.backoff= true
#
传输数据选择机制
,
默认是轮调
,
生产机设置为随机
,
后期优化可
测试
调整
a1.sinkgroups.g1.processor.selector= random
#
TODO
管道(channels)
#
临时存储方式为硬盘
a1.channels.c1.type= file
#
检查传输及断点续传等验证文件,可原理可参考
MR
合并小文件的方式
a1.channels.c1.checkpointDir= /home/grid/flume/tmp/checkpoint
#
传输数据
a1.channels.c1.dataDirs= /home/grid/flume/tmp/data
flume
日志存储配置文件(flume-conf.properties):
# TODO
定义数据入口(sources)、管道(channels)、数据出口(
sink
)
#
定义数据入口(sources)
agent.sources= r1
#
定义数据出口(
sink
)
agent.sinks= k1
#
管道(channels)
agent.channels= c1
#
TODO
配置数据入口(sources)
#
定义数据源
AVRO
方式,使用
RPC
方式接收,故此需要端口号
agent.sources.r1.type= avro
#
配置对接管道
agent.sources.r1.channels= c1
#
限制接收数据的发送方
ID,
0.0.0.0是接收任何
IP
,不做限制
agent.sources.r1.bind= 0.0.0.0
#
接收端口(与其
flume
客户端的
sink
相呼应)
agent.sources.r1.port= 4141
#
TODO
数据出口(
sink
)
#
定义类型为
HDFS
方式存储
agent.sinks.k1.type= hdfs
#
配置对接管道
agent.sinks.k1.channel= c1
#
配置
HDFS
存储目录,此处也可使用
%{host}
主机名
agent.sinks.k1.hdfs.path= hdfs://my1:9000/log/%Y%m%d/%H/
#
设置压缩与非压缩,此处非压缩
agent.sinks.k1.hdfs.fileType=DataStream
#
格式化文件
,
可选“Text” or “Writable”,此处选择文本方式
agent.sinks.k1.hdfs.writeFormat= Text
#
文件头前缀名,亦可增加/%Y%m%d/%H/等属性
agent.sinks.k1.hdfs.filePrefix= processlog
#
读取到指定记录数
,
将一次写入数据存入HDFS中,
0
则表示不启用
agent.sinks.k1.hdfs.rollCount= 0
#
读取到指定
KB
的文件大小,将一次写入数据存入HDFS中,
0
则表示参数不启用
agent.sinks.k1.hdfs.rollSize= 0
#
读取到指定秒数的日志读取,将一次写入数据存入HDFS中,
300
则
60
×
5
(
5
分钟)
agent.sinks.k1.hdfs.rollInterval= 300
#
一次事件写入hdfs的个数
agent.sinks.k1.hdfs.batchSize = 1000
0
#
TODO
管道(channels)
#
临时存储方式为硬盘
agent.channels.c1.type= file
#
检查传输及断点续传等验证文件,可原理可参考
MR
合并小文件的方式
agent.channels.c1.checkpointDir= /home/grid/flume/tmp/checkpoint
#
传输数据
agent.channels.c1.dataDirs= /home/grid/flume/tmp/data