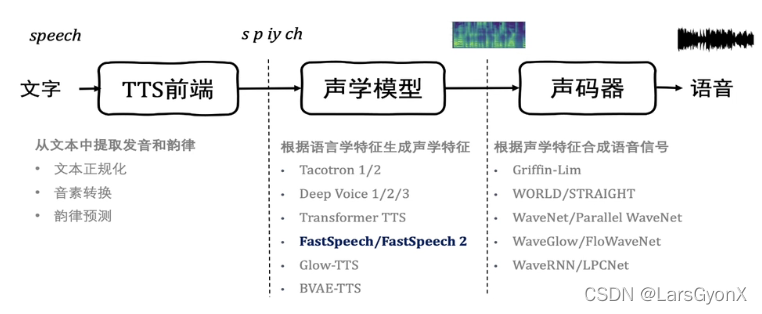
一、语音合成流程
二、端到端自回归语音合成
基于深度数据和对应的文本进行训练,无需繁琐的人工提取过程。可以合成非常学习的语音合成模型,直接使用非常学习的语音合成骂醒直接使用录音接近真实录音音质的语音。
Tacotron
Encoder:BLSTM
Decoder:BLSTM
Attention: Location sensitive attention(串行训练过程)
Input:Char/Phoneme(字符,音素)
Output:Mel-spectrograms

如何将文本转成Mel频谱
编码:将每一个字符进行编码(word embedding),进行context交互(双向LSTM),获取读音信息
交互:Location Sensitive Attention ,将两个模态中的数据进行连接
解码:经过几层LSTM生成Mel频谱。
LSTM是自回归结构,每一步会输入上一步的输出,并生成这一步的信息。
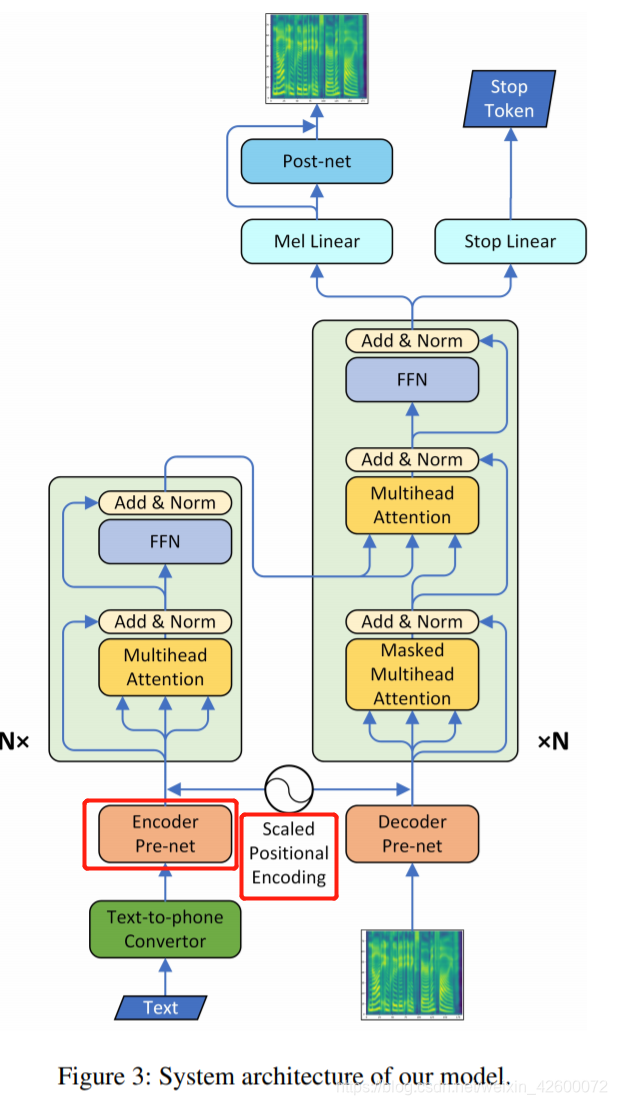
Transformer TTS
Encoder: Transformer Encoder
Decoder: Transformer Decoder
Attention: Multi-head Attention(并行训练过程)
Input: Phoneme
Output: Mel-spectrograms
Deep voice
Encoder: CNN blocks
Decoder: Causal CNN blocks
Attention: Attention
Input: Char+Phoneme
Output:Mel-spectrograms+World vocoder features

特点:输入和输出都有两种,采取不同声码器转成波形。
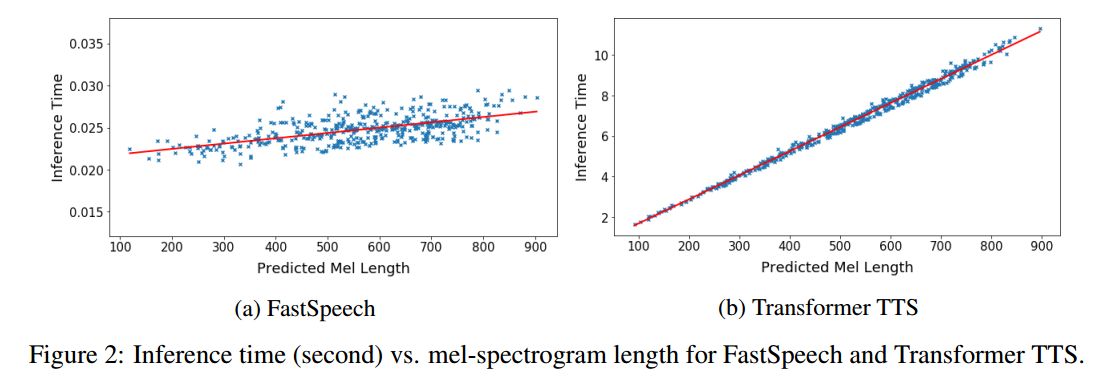
自回归方法语音合成缺陷
-
传统的端到端方法的
合成速度非常慢
,它在一 些对速度和实时性要求较高的场合下较难应用,并且受限于合成速度,这种方法的扩展成本非常高,在高流量高并发的场景下很难提供稳定的服务。 -
传统的端到端语音合成会出现
重复吐词或漏词
现象,这对商用的语音合成系统来说是非常致命和难以容忍的。 -
传统的端到端方法无法
细粒度地控制
语速、韵律和停顿等。
如何解决这三大痛点?
三、非自回归语音合成方法——FastSpeech
-
FastSpeech使用
全并行的非自回归架构
,解决了生成速度慢的问题,同时引入
知识蒸馏
来使得生成音频的性能接近自回归模型。 -
FastSpeech引入了
duration predictor
来预测文本和频谱之间的
强对齐
,消除了生成语音的跳词、漏词等现象。 -
FastSpeech引入了
length regulator
来解决自回归模型的可控性问题。将文本与语音的隐特征建立联系。

声音质量

加速比