前言:
KOOM是快手开源的一款针对线上OOM问题排查和解决的框架,其于2020年开源,有效的解决了LeakCanary无法用于线上的问题。
针对KOOM原理的讲解我准备分别两篇文章,分别为:
上篇:检测java内存状态的原理分析;
下篇:检测native内存状态的原理分析。
本篇是该系列文章的第一篇,主要讲解KOOM如何针对java层的内存问题如何发现并找出其泄漏路径。
一.使用入门
使用KOOM需要做进行三步操作:
1.app下的build.gradle文件进行相关依赖声明,如下:
implementation "com.kuaishou.koom:koom-native-leak:${VERSION_NAME}"
implementation "com.kuaishou.koom:koom-monitor-base:${VERSION_NAME}"
implementation "com.kuaishou.koom:koom-java-leak:${VERSION_NAME}"
implementation "com.kuaishou.koom:koom-thread-leak:${VERSION_NAME}"
PS:VERSION_NAME = 2.2.0
2.Application中进行相关代码的初始化:
这里是用的是默认的初始化方法,其实也可以自己进行参数上的定制,这里就不演示的,具体可以参考DefaultInitTask中的init方法进行相关初始化。
DefaultInitTask.INSTANCE.init(this);
3.Activity或者Service中开启内存分析检测
相关初始化代码如下:
OOMMonitorInitTask.init(DemoApplication.getInstance())
OOMMonitor.startLoop(true, false, 5000L)这里OOMMonitorInitTask类是我直接从官方demo中拷贝出来的,核心逻辑其实就是init方法。该方法中,主要也是对各种参数进行配置,然后通过以下方法进行设置。
MonitorManager.addMonitorConfig(config)
4.验证效果
我们构造一个内存泄漏的Activity,如下,然后启动这个Activity。
public class LeakedActivity extends Activity {
public static Instance instance;
static byte[] bytes;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
instance = new Instance();
bytes = new byte[1 * 1024 * 1024];
instance.uselessObjectList.add(this);
this.finish();
}
public static class Instance {
public List<Activity> uselessObjectList = new ArrayList<>();
}
}
测试代码如下:
startActivity(Intent(requireContext(), LeakedActivity::class.java))这时候,理论上KOOM应该能够帮助我们检测到LeakActivity已经泄漏了,并且还泄漏了1M的内存,但是实际上,并没有任何提示。这是为何?
别急,这里就留一个伏笔,我们接下来讲解原理,讲解完原理之后,这里的答案也就有了。
二.内存检测流程
2.1 启动内存检测流程
OOMMonitor.startLoop():
override fun startLoop(clearQueue: Boolean, postAtFront: Boolean, delayMillis: Long) {
...上面的代码都是各种初始化检查,可以忽略
//开启检查,
super.startLoop(clearQueue, postAtFront, delayMillis)
//分析上一次的内存文件
getLoopHandler().postDelayed({ async { processOldHprofFile() } }, delayMillis)
}主要做了3件事:
1.各种初始化检测
2.开启检测流程
3.分析上一次的内存文件。因为很有可能因为OOM导致崩溃了,崩溃了自然无法分析,所以检查上一次的内存文件判断是否已经处理过。
2.2 LoopMonitor.startLoop中进行定时监测
LoopMonitor.startLoop方法中,则更简单了,根据postAtFront标记位,判断是否要延时执行。所以核心的检测逻辑在mLoopRunnable方法中。
open fun startLoop(
clearQueue: Boolean = true,
postAtFront: Boolean = false,
delayMillis: Long = 0L
) {
if (clearQueue) getLoopHandler().removeCallbacks(mLoopRunnable)
if (postAtFront) {
getLoopHandler().postAtFrontOfQueue(mLoopRunnable)
} else {
getLoopHandler().postDelayed(mLoopRunnable, delayMillis)
}
mIsLoopStopped = false
}
2.3 mLoopRunnable定时执行检测任务
mLoopRunnable如下,其主要逻辑是每隔固定时间进行一次检测,而检测的核心逻辑在call方法中。实现类是OOMMonitor,所以call方法也在这个类中。
private val mLoopRunnable = object : Runnable {
override fun run() {
if (call() == LoopState.Terminate) {
return
}
if (mIsLoopStopped) {
return
}
getLoopHandler().removeCallbacks(this)
getLoopHandler().postDelayed(this, getLoopInterval())
}
}
2.4 单次检测
call方法如下,如果SDK不匹配或者已经开始dump内存了,则退出执行检测。KOOM如果发现泄漏后,只会执行一次内存DUMP和分析,执行完成中就会退出检测流程。
override fun call(): LoopState {
if (!sdkVersionMatch()) {
return LoopState.Terminate
}
if (mHasDumped) {
return LoopState.Terminate
}
return trackOOM()
}
2.5 检测流程
接着看一下trackOOM方法:
private fun trackOOM(): LoopState {
SystemInfo.refresh()
mTrackReasons.clear()
for (oomTracker in mOOMTrackers) {
if (oomTracker.track()) {
mTrackReasons.add(oomTracker.reason())
}
}
if (mTrackReasons.isNotEmpty() && monitorConfig.enableHprofDumpAnalysis) {
if (isExceedAnalysisPeriod() || isExceedAnalysisTimes()) {
MonitorLog.e(TAG, "Triggered, but exceed analysis times or period!")
} else {
async {
MonitorLog.i(TAG, "mTrackReasons:${mTrackReasons}")
dumpAndAnalysis()
}
}
return LoopState.Terminate
}
return LoopState.Continue
}首先,通过SystemInfo.refresh()方法刷新当前的内存相关数据。
然后清空集合mTrackReasons,然后对mOOMTrackers集合中的所有类型进行相关的检测,如果监测到有问题,则加入到mTrackReasons集合中。
最后,如果mTrackReasons集合不为空,则说明已经满足了开启内存分析的条件,则调用dumpAndAnalysis方法去进行内存的dump和分析,同时返回LoopState.Terminate退出检测循环。
mOOMTrackers中共有5种类型,具体如何执行检测的我们下一章来讲解。
如何进行内存dump和分析的,我们第四章来讲解。
2.6 检测总结
所以总结一下,检测流程可以成下图所示:
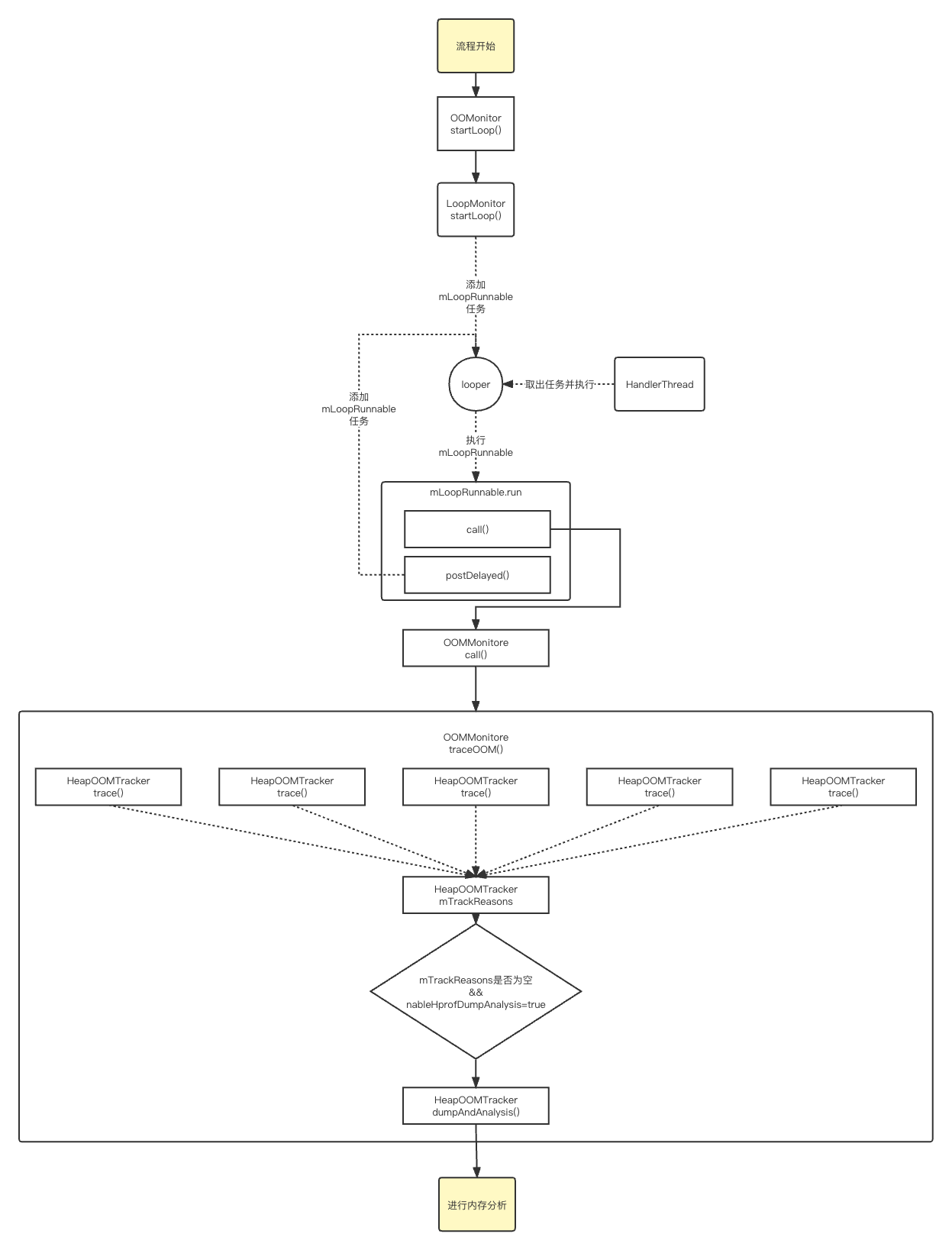
三.5种检查类型
mOOMTrackers中有五种类型,分别为:HeapOOMTracker,ThreadOOMTracker,FdOOMTracker,PhysicalMemoryOOMTracker,FastHugeMemoryOOMTracker。
3.1.APP内存使用检查HeapOOMTracker
首先要获取几个数据,这几个数据其实是上面SystemInfo.refresh()方法中获取的,不过因为这里用到,我们就放到这里来讲了。几个数据如下
最大内存:javaHeap.max = Runtime.getRuntime().maxMemory()
总内存:javaHeap.total = Runtime.getRuntime().totalMemory()
空闲内存:javaHeap.free = Runtime.getRuntime().freeMemory()
使用内存=最大内存-空闲内存:javaHeap.used = javaHeap.total – javaHeap.free
使用占比=使用内存/最大内存:javaHeap.rate = 1.0f * javaHeap.used / javaHeap.max
判断条件如下:
override fun track(): Boolean {
val heapRatio = SystemInfo.javaHeap.rate
if (heapRatio > monitorConfig.heapThreshold
&& heapRatio >= mLastHeapRatio - HEAP_RATIO_THRESHOLD_GAP) {
mOverThresholdCount++
MonitorLog.i(TAG,
"[meet condition] "
+ "overThresholdCount: $mOverThresholdCount"
+ ", heapRatio: $heapRatio"
+ ", usedMem: ${SizeUnit.BYTE.toMB(SystemInfo.javaHeap.used)}mb"
+ ", max: ${SizeUnit.BYTE.toMB(SystemInfo.javaHeap.max)}mb")
} else {
reset()
}
mLastHeapRatio = heapRatio
return mOverThresholdCount >= monitorConfig.maxOverThresholdCount
}总结一下,就是连续3次(默认值,可配置)检测中,内存使用占比超过80%(不同内存大小占比不一样,可配置),并且内存状态没有呈明显下降趋势,则说明内存存在问题,需要进行检查。
3.2 线程数检查ThreadOOMTracker
每个进程中,对线程数量上限是有严格定义的,如果超出了线程数上限,也会报OOM问题。
同样需要先获取当前进程的线程数量,这个操作同样也是上面SystemInfo.refresh()方法中获取的,这里只是使用。(3.3,3.4,3.5下同,不赘述)
通过读取”/proc/self/status“文件来获取线程数量,文件内容如下,读取Threads这一行的值就是当前进程的线程数。
Name: adbd
Umask: 0000
State: S (sleeping)
Tgid: 1373
Ngid: 0
Pid: 1373
PPid: 1
TracerPid: 0
Uid: 2000 2000 2000 2000
Gid: 2000 2000 2000 2000
FDSize: 64
Groups: 1004 1007 1011 1015 1028 1078 1079 3001 3002 3003 3006 3009 3011
VmPeak: 11080372 kB
VmSize: 11010628 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 5860 kB
VmRSS: 4740 kB
RssAnon: 1972 kB
RssFile: 2504 kB
RssShmem: 264 kB
VmData: 39480 kB
VmStk: 132 kB
VmExe: 1856 kB
VmLib: 3388 kB
VmPTE: 232 kB
VmPMD: 44 kB
VmSwap: 452 kB
Threads: 10 //线程数
...
判断方法如下:
override fun track(): Boolean {
val threadCount = getThreadCount()
if (threadCount > monitorConfig.threadThreshold
&& threadCount >= mLastThreadCount - THREAD_COUNT_THRESHOLD_GAP) {
mOverThresholdCount++
MonitorLog.i(TAG,
"[meet condition] "
+ "overThresholdCount:$mOverThresholdCount"
+ ", threadCount: $threadCount")
dumpThreadIfNeed()
} else {
reset()
}
mLastThreadCount = threadCount
return mOverThresholdCount >= monitorConfig.maxOverThresholdCount
}和内存检查相似的逻辑,就是连续3次(默认值,可配置)检测中,线程数量超过450(不同机型和安卓版本不一样,可配置),并且线程数量没有呈明显下降趋势,则说明线程数量存在问题,需要进行检查。
3.3 FD数量检查FdOOMTracker
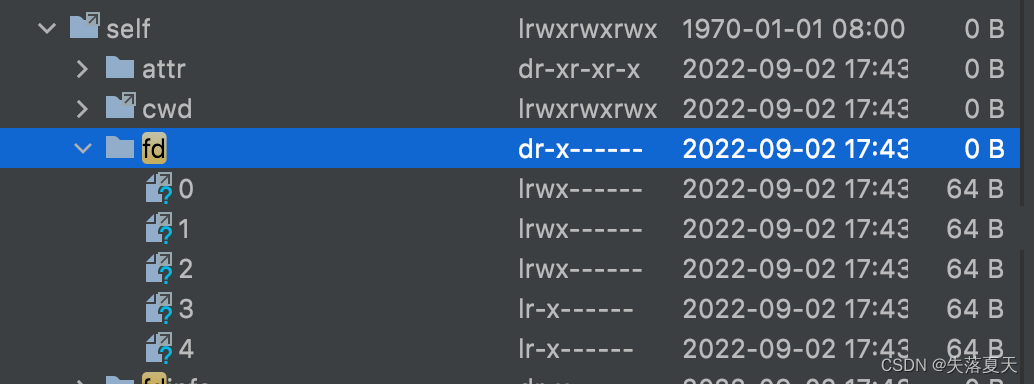
进程中,FD越多,资源消耗越大,自然FD也是要有数量限制的。
同样要获取FD数量,通过读取/proc/self/fd下文件数量来进行判断。如下图就是5个FD。
判断方法如下:
override fun track(): Boolean {
val fdCount = getFdCount()
if (fdCount > monitorConfig.fdThreshold && fdCount >= mLastFdCount - FD_COUNT_THRESHOLD_GAP) {
mOverThresholdCount++
MonitorLog.i(TAG,
"[meet condition] "
+ "overThresholdCount: $mOverThresholdCount"
+ ", fdCount: $fdCount")
dumpFdIfNeed()
} else {
reset()
}
mLastFdCount = fdCount
return mOverThresholdCount >= monitorConfig.maxOverThresholdCount
}就是连续3次(默认值,可配置)检测中,FD数量超过1000(可配置),并且线程数量没有呈明显下降趋势(每次递减50),则说明FD数量存在问题,需要进行检查。
3.4 设备内存监控 PhysicalMemoryOOMTracker
首先,仍然是获取一些数据,这里获取的是设备内存使用占比。
方式是通过读取/proc/meminfo文件,文件内容如下,具体的解释这里不讲了,有兴趣的可以参考这一篇文章:
/proc/meminfo 解析_FoGoiN的博客-CSDN博客_proc/meminfo
MemTotal: 6391304 kB
MemFree: 719044 kB
MemAvailable: 2314468 kB
Buffers: 161840 kB
Cached: 1950736 kB
SwapCached: 77708 kB
Active: 2833588 kB
Inactive: 1407620 kB
Active(anon): 1709496 kB
Inactive(anon): 425888 kB
Active(file): 1124092 kB
Inactive(file): 981732 kB
Unevictable: 3044 kB
Mlocked: 3044 kB
SwapTotal: 1048572 kB
SwapFree: 846352 kB
Dirty: 188 kB
Writeback: 0 kB
AnonPages: 2131644 kB
Mapped: 666392 kB
Shmem: 4312 kB
Slab: 271600 kB
SReclaimable: 115712 kB
SUnreclaim: 155888 kB
KernelStack: 66592 kB
PageTables: 81600 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 4244224 kB
Committed_AS: 84518516 kB
VmallocTotal: 263061440 kB
VmallocUsed: 183232 kB
VmallocChunk: 0 kB
CmaTotal: 401408 kB
CmaFree: 398172 kB
不过这里并没有进行相关的判断,应该是为了以后做准备吧,目前该方法返回的都是false。
3.5 快速增长大内存检测 FastHugeMemoryOOMTracker
仍然是先获取一些数据,内存占比,这个值3.1中已经讲过了。
这里判断的是如果内存使用率超过90%,或者内存增长两次之间超过350M(可配置),则触发内存检测。
3.6 检测总结
所以回顾我们第一章的问题,我们也就知道第一章中为什么Activity泄漏,或者泄漏1M数据没有触发检测了。因为KOOM本身就不适用于检测内存泄漏的,而是一个用来检查内存健康状态的工具。
举个例子,我的APP内存占比很少,只有十几M内存,这时候,假设我泄漏了很多Activity,也不会有什么问题,因为内存占比很少,并不会触发OOM了。而且Activity对象经过若干次GC之后会进入老年代,所以也不会导致频繁GC的问题。
再举一个反面例子,我的APP内存占比很多,虽然只泄漏了一个Activity,但是这个Activity内容很多,占用几百M内存,那么有可能就因为这一个Activity的泄漏导致程序OOM。
所以KOOM是用来保证我们程序可以在内存方面稳定安全运行的一款工具,而不是单纯用来检查内存泄漏的。
为了方便一些新手,在略微啰嗦一下,此时你们知道如何处罚KOOM的内存检查了吗?方式很简单,开启检查之后,瞬间创建超过450个线程,内存使用率提升到80%以上并且持续不释放,内存使用率提高到90%,再或者new一个超级大的对象(超过350M),这些就都会触发KOOM检查了。
四.如何dump内存快照
4.1为什么LeakCanary不能用于线上?
我们知道内存发生了问题后,那么如何处理呢?这就进入了dump并分析内存的流程(dumpAndAnalysis)。
一般来说,我们分析内存是通过如下操作进行的,比如LeakCanary就是这样的流程:
1.dump被fork出来的进程的内存;
2.分析内存文件hprof;
3.输出内存结果。
但是这样存在一个很大的问题,dump内存时,需要挂起对应进程中所有的线程,而且需要持续一段时间。在安卓中我们都知道,一旦线程(包含主线程)被挂起,那么自然就无法响应用户操作了,会发生ANR的问题。即使没有到ANR的阈值(5S),也会给用户一个卡顿的感受,严重影响用户的体验。
所以这就是为什么LeakCanary不能用于线上的原因。
4.2 KOOM是如何分析的?
但是我们如果用过KOOM,就会发现KOOM的内存健康检查是实时的,而且根据其官方说法是可以用于线上的,那么肯定是影响用户体验为前提的,所以,KOOM是如何解决卡顿问题的呢?
这里有一个核心思路就是进程fork。如果你知道APP启动流程的原理,就会知道所有APP的启动,其APP进程其实都是由zygote进程fork而来的。没看过的可以参考我的另外一篇文章:
android源码学习- APP启动流程(android12源码)_失落夏天的博客-CSDN博客_androidapp源码
所以安卓系统为什么要fork一个进程而不是完完全全创建一个呢?答案就是复制一个进程,要比重新创建一个进程资源消耗少的多。通常我们启动APP的话,你会感觉到启动流程一闪而过,实际上fork一个进程只需要几十毫秒,这么短的时间对用户的影响是极小的。
所以KOOM内存分析的核心就是这个原理,进行内存分析时,首先fork主进程,因为被fork的进程内存状态和主进程是一模一样的,所以对被fork进程的内存分析,就等同于分析主进程的内存状态。而fork完成的主进程后,则可以继续响应用户的操作,所以对用户的影响很小。
4.3 KOOM中dump内存流程
看完上一小节,我们知道了fork主进程的好处。那么这样实现,会有什么问题呢?我们先列一下KOOM的流程,然后慢慢来讲。
1.挂起所有子线程
2.fork当前主进程
3.恢复当前所有子线程
4.dump被fork出来的进程的内存
5.结束fork出来的进程
6.启动service对dump出来的内存文件进行分析
对应的部分代码在ForkJvmHeapDumper.java类的dump方法中,相关注释已添加
public synchronized boolean dump(String path) {
MonitorLog.i(TAG, "dump " + path);
if (!sdkVersionMatch()) {
throw new UnsupportedOperationException("dump failed caused by sdk version not supported!");
}
init();//获取挂起线程相关的方法
if (!mLoadSuccess) {
MonitorLog.e(TAG, "dump failed caused by so not loaded!");
return false;
}
boolean dumpRes = false;
try {
MonitorLog.i(TAG, "before suspend and fork.");
int pid = suspendAndFork();//挂起线程,然后fork主进程
if (pid == 0) {
// Child process
Debug.dumpHprofData(path);//返回0代表示新创建的进程,则进行内存dump
exitProcess();
} else if (pid > 0) {
// Parent process
dumpRes = resumeAndWait(pid);//返回>0代表仍然是原来的主进程,此时恢复被挂起线程
MonitorLog.i(TAG, "dump " + dumpRes + ", notify from pid " + pid);
}
} catch (IOException e) {
MonitorLog.e(TAG, "dump failed caused by " + e);
e.printStackTrace();
}
return dumpRes;
}看完整个流程,如果基础比较弱的读者,也会有一点懵逼,会产生以下的疑问:
1.流程中说要先挂起所有子线程,为什么进程fork时需要提前挂起所有子线程呢?
2.exitProcess之后不就退出进程了,后面的代码如何执行的?
别急,我们下两小节依次来讲。
4.5 为什么fork进程前要挂起子线程?
其实fork进程前是不需要挂起子线程的,这里之所以挂起子线程,是因为后面需要DUMP内存。
JVM虚拟机在dump的时候,需要提前挂起所有的线程,才能进行内存的dump。那么直接让JVM虚拟机在dump的时候进行挂起不可以吗?
还真不行。这就不得不提到fork进程的原理了,进程的fork,本质上是linux提供的一种机制,但是这种机制有一些问题,linux的进程fork本身是为了单线程所准备的,多进程虽然也可以fork,但会存在一些问题。比如每个线程都存在内存地址的,fork了之后,被fork进程中的线程内存地址很有可能是错的,这时候再去执行dump操作挂起线程,就会导致无法正常挂起,无法挂起的话自然后面的dump操作就无法执行,从而导致dump内存时会一直卡住迟迟没有返回值。
所以为了避免这种卡住的情况,我们就提前把进程中的所有子线程挂起,这样fork之后再去dump内存时,因为线程本身已经挂起了,自然就不需要再次执行挂起操作,从而可以顺利的进行内存dump操作了。
说到这,继续扩展一下,为什么APP启动流程中,AMS通知Zygote使用的是socket而不是Binder呢?其原因也和这个特性有一定关系,binder在server端是会有单独线程去处理的。感兴趣的可以看一下这篇文章:
android中AMS通知Zygote去fork进程为什么使用socket而不使用binder?_失落夏天的博客
我们看一下在KOOM中的代码:
hprof_dump.cpp类中Initialize方法:
void HprofDump::Initialize() {
if (init_done_ || android_api_ < __ANDROID_API_L__) {
return;
}
void *handle = kwai::linker::DlFcn::dlopen("libart.so", RTLD_NOW);
KCHECKV(handle)
if (android_api_ < __ANDROID_API_R__) {
suspend_vm_fnc_ =
(void (*)())DlFcn::dlsym(handle, "_ZN3art3Dbg9SuspendVMEv");
KFINISHV_FNC(suspend_vm_fnc_, DlFcn::dlclose, handle)
resume_vm_fnc_ = (void (*)())kwai::linker::DlFcn::dlsym(
handle, "_ZN3art3Dbg8ResumeVMEv");
KFINISHV_FNC(resume_vm_fnc_, DlFcn::dlclose, handle)
} else if (android_api_ <= __ANDROID_API_S__) {
// Over size for device compatibility
ssa_instance_ = std::make_unique<char[]>(64);
sgc_instance_ = std::make_unique<char[]>(64);
ssa_constructor_fnc_ = (void (*)(void *, const char *, bool))DlFcn::dlsym(
handle, "_ZN3art16ScopedSuspendAllC1EPKcb");
KFINISHV_FNC(ssa_constructor_fnc_, DlFcn::dlclose, handle)
ssa_destructor_fnc_ =
(void (*)(void *))DlFcn::dlsym(handle, "_ZN3art16ScopedSuspendAllD1Ev");
KFINISHV_FNC(ssa_destructor_fnc_, DlFcn::dlclose, handle)
sgc_constructor_fnc_ =
(void (*)(void *, void *, GcCause, CollectorType))DlFcn::dlsym(
handle,
"_ZN3art2gc23ScopedGCCriticalSectionC1EPNS_6ThreadENS0_"
"7GcCauseENS0_13CollectorTypeE");
KFINISHV_FNC(sgc_constructor_fnc_, DlFcn::dlclose, handle)
sgc_destructor_fnc_ = (void (*)(void *))DlFcn::dlsym(
handle, "_ZN3art2gc23ScopedGCCriticalSectionD1Ev");
KFINISHV_FNC(sgc_destructor_fnc_, DlFcn::dlclose, handle)
mutator_lock_ptr_ =
(void **)DlFcn::dlsym(handle, "_ZN3art5Locks13mutator_lock_E");
KFINISHV_FNC(mutator_lock_ptr_, DlFcn::dlclose, handle)
exclusive_lock_fnc_ = (void (*)(void *, void *))DlFcn::dlsym(
handle, "_ZN3art17ReaderWriterMutex13ExclusiveLockEPNS_6ThreadE");
KFINISHV_FNC(exclusive_lock_fnc_, DlFcn::dlclose, handle)
exclusive_unlock_fnc_ = (void (*)(void *, void *))DlFcn::dlsym(
handle, "_ZN3art17ReaderWriterMutex15ExclusiveUnlockEPNS_6ThreadE");
KFINISHV_FNC(exclusive_unlock_fnc_, DlFcn::dlclose, handle)
}
DlFcn::dlclose(handle);
init_done_ = true;
}看到这些代码是不是又有一些懵了?为什么没有调用挂起的方法,而是调用_ZN3art3Dbg9SuspendVMEv呢?另外为什么安卓10以上(含)和以下有区别呢?
这是因为安卓10开始,限制APP使调用私有API方法,所以需要使用黑科技的时候去调用挂起方法。这个我们第五章来专门讲,这里只要知道是挂起线程就好。
4.6 为什么exitProcess之后还能有返回值?
如果有这个疑问的,说明对安卓掌握不深,不过没关系,我们细细来讲,本篇文章其目的就是为了让所有读者都清楚其原理。
进程fork的示意图大体如下所示:
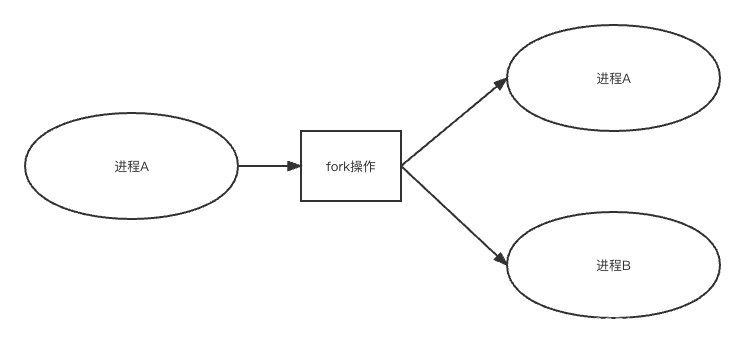
也是是说,进程fork的操作,在操作之后会有两次返回值,而不是正常理解的一个。
//执行下面这行代码后,会有两次返回。一次是返回pid=0,另外一次返回pid>0。
int pid = suspendAndFork();
if (pid == 0) {
}else{
}在这两次的返回中,其进程中内存空间是完全一样的,唯一的区别就是PID不一样,一个仍然是原进程ID的PID,而另外被fork的进程B则是0。需要注意的是,返回值0并不是进程B的PID,而只是说明子进程fork成功而已。
五.如何调用native挂起线程的方法
5.1 传统调用方式
挂起线程的方法在debugger.cc中,比如在9.0中是Dbg::SuspendVM方法(该小节都以9.0为例),在libart.so中,方法如下:
void Dbg::SuspendVM() {
// Avoid a deadlock between GC and debugger where GC gets suspended during GC. b/25800335.
gc::ScopedGCCriticalSection gcs(Thread::Current(),
gc::kGcCauseDebugger,
gc::kCollectorTypeDebugger);
Runtime::Current()->GetThreadList()->SuspendAllForDebugger();
}正常情况下,我们可以通过dlopen,dlsys的方式进行调用,代码如下:
void *handle = dlopen("libart.so", RTLD_NOW);
suspend_vm_fnc_ =(void (*)())dlsym(handle, "_ZN3art3Dbg9SuspendVMEv");
dlclose(handle);这样就可以挂起进程中所有的线程了。
dl的用法这里就不扩展了,读者可以自行百度,调用流程类似于java中的反射。

另外,这里为什么是_ZN3art3Dbg9SuspendVMEv而不是Dbg::SupsendVM呢?这个操作类似于java反射的调用方式,最后调用时需要使用的是最终生成的地址名。我们可以拷贝libart.so文件出来,使用
nm -a libart.so > show.txt命令查看该so下所有的方法名,部分方法名如下:
...
0011ae48 T _ZN3art3Dbg8ResumeVMEv
00109968 T _ZN3art3Dbg9StartJdwpEv
0011addc T _ZN3art3Dbg9SuspendVMEv
...
5.2 KOOM实现方式
我们看KOOM中的实现,用的并不是dlopen,dlsys这样的函数,而是使用的kwai::linker::DlFcn::dlopen,kwai::linker::DlFcn::dlsym这样的方法,这是为何?
在安卓7.0之后,安卓限制了APP对私有API的调用,强行调用会导致崩溃,而libart.so中的这些方法都属于私有API,所以就必须想办法绕开正常的调用方式。
这个绕开限制的方案美团有一个描述比较详细的方案,主要看:“突破7.0动态链接的限制”这一章,地址如下:
为了方便读者连续阅读,我这里简单也描述一下。正常的方式是使用dlopen,dlsys的方案行不通了,但是我们可以把libart.so映射到内存中,然后按照按照ELF文件结构计算目标方法和头地址的偏移,然后使用内存中真实的libart.so的地址+偏移来计算出目标方法在内存中的位置,从而通过访问这块内存来实现相关方法的调用,而KOOM用的也是这一套原理。
相关代码在KOOM的kwai_dlfcn.cpp类中,这里也就不扩展了,感兴趣的读者可以自行阅读。
五.内存文件分析
5.1生成内存镜像文件hprof
fork生成新的进程后,就可以dump新的进程内存状态,并且恢复主进程的刮起状态了,相关代码如下:
int pid = suspendAndFork();
if (pid == 0) {
// Child process
Debug.dumpHprofData(path);
exitProcess();
} else if (pid > 0) {
// Parent process
dumpRes = resumeAndWait(pid);
MonitorLog.i(TAG, "dump " + dumpRes + ", notify from pid " + pid);
}
5.2 内存镜像文件hprof分析
获取到了内存文件之后,就会开启一个service进行分析,这个service自然可以跑在单独的进程中,避免影响主进程的正常运行:
<service
android:name=".monitor.analysis.HeapAnalysisService"
android:process=":heap_analysis" />启动service后,主流程在onHandleIntent方法中。KOOM中内存分析使用的工具和LeakCanary都是shark,但是KOOM中的shark有一些自己的改造,主流程代码如下:
override fun onHandleIntent(intent: Intent?) {
val resultReceiver = intent?.getParcelableExtra<ResultReceiver>(Info.RESULT_RECEIVER)
val hprofFile = intent?.getStringExtra(Info.HPROF_FILE)
val jsonFile = intent?.getStringExtra(Info.JSON_FILE)
val rootPath = intent?.getStringExtra(Info.ROOT_PATH)
OOMFileManager.init(rootPath)
kotlin.runCatching {
buildIndex(hprofFile)
}.onFailure {
it.printStackTrace()
MonitorLog.e(OOM_ANALYSIS_EXCEPTION_TAG, "build index exception " + it.message, true)
resultReceiver?.send(AnalysisReceiver.RESULT_CODE_FAIL, null)
return
}
buildJson(intent)
kotlin.runCatching {
filterLeakingObjects()
}.onFailure {
MonitorLog.i(OOM_ANALYSIS_EXCEPTION_TAG, "find leak objects exception " + it.message, true)
resultReceiver?.send(AnalysisReceiver.RESULT_CODE_FAIL, null)
return
}
kotlin.runCatching {
findPathsToGcRoot()
}.onFailure {
it.printStackTrace()
MonitorLog.i(OOM_ANALYSIS_EXCEPTION_TAG, "find gc path exception " + it.message, true)
resultReceiver?.send(AnalysisReceiver.RESULT_CODE_FAIL, null)
return
}
fillJsonFile(jsonFile)
resultReceiver?.send(AnalysisReceiver.RESULT_CODE_OK, null)
System.exit(0);
}主要流程如下:
1.OOMFileManager.init方法中初始化root路径
2.buildIndex方法中加载hprof文件,构建HeapGraph对象
3.buildJson中初始化返回值json,清空历史缓存
4.filterLeakingObjects方法中对第二步构建的HeapGraph对象进行分析,遍历镜像中所有class查找可能泄漏的点。
5.findPathsToGcRoot方法中对上面可能泄漏的点寻找其泄漏路径。
6.fillJsonFile,生成对应的JSON报告。
7.resultReceiver?.send,通知APP进程已经分析好了,json和hprof文件路径为双方提前约定好的路径。
8.System.exit(0); 结束当前分析的service进程。
至于shark是如何对内存镜像文件进行分析的,文本就不扩展了,这个要讲的的话就太多了,建议读者自行百度。
六.声明
1.KOOM项目地址
2.原理分析过程中使用的demo项目地址如下:
https://github.com/aa5279aa/android_all_demo
3.本文参考的链接及咨询人员
https://github.com/KwaiAppTeam/KOOM/blob/master/README.zh-CN.md
KOOM作者团队:@薛秋实 @李锐 @紫同