对超分有兴趣的同学们可直接关注微信公众号,这个号的定位就是针对图像超分辨的,会不断更新最新的超分算法解读。

正文开始
Contents
1. Introduction
这篇文章的主要目标:
- 实时性(FPS>=24),一个重要的点是SRCNN先进行bicubic interpolation,然后再输入网络,这极大增加了参数量。解决:通过使用参数可学习的deconv层代替interpolation,可以提高网络能力,并且deconv放在网络末端还能减少参数(提升实时性)。
- 精度,一个重要的点是增加mapping阶段的深度(layer),但这会以牺牲实时性为代价。解决:先通过1X1的核进行shrinking,对特征图深度进行减小,再进行映射,最后用1X1的核再对特征图深度进行增加。
- 不同的缩放因子,通过训练一种缩放尺度的网络后,再仅对deconv层进行微调,然后在微调后的网络(除deconv层外其他参数不变,类似于迁移学习)基础上进行另一种缩放因子的训练。可以快速得到另一种缩放尺度的模型。
相对于SRCNN,FSRCNN网络改进的地方:
- 移除网络输入处的插值放大操作,改为网络输出处的deconvolution操作;
- 将中间步骤的LR到SR的映射,改变为先通过s个1X1的核做shrinking(将输入的d维图像转为s维),进行mapping映射,最后通过d个1X1的核做expanding(转回d维);
-
不同于SRCNN仅用一层conv做mapping,FSRCNN用4层3X3的mapping卷积。

2. Related Work
FSRCNN相比于之前的工作,一个重要贡献是,通过在预训练好的缩放因子的基础上,通过微调deconv层结构,来完成对另一种缩放因子模型的训练,这其中用到了迁移学习的思想。
3. Fast Super-Resolution by CNN
这部分简单介绍SRCNN,详细介绍FSRCNN,并介绍FSRCNN在SRCNN基础上的改进。
3.1 SRCNN
SRCNN是最早使用dl进行SR的网络,它首先将LR图像进行bicubic interpolation放大到和HR图像一样的尺寸,然后输入3层CNN中得到重建结果。其中这3层卷积层分别称为特征提取、特征映射、图像重建。SRCNN的计算复杂度可以用下面的公式表示:
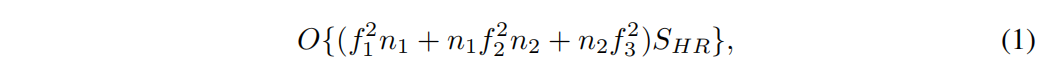
其中,f为核的size,n为每层核的数量。可以看到:1. SRCNN的计算复杂度和HR的size正相关;2. 中间层对参数量的影响较大。在接下来的FSRCNN中,将重点关注这两个方面。
SRCNN的结构如图二上半部分所示:

3.2 FSRCNN
FSRCNN的结构如图二下半部分所示。整个网络可以被分解为5个部分:特征提取、压缩、映射、扩展、去卷积。其中前四部分都是卷积层conv(fi,ni,ci),第五部分是去卷积层deconv(fi,ni,ci),其中fi,ni,ci分别为核尺寸,核数量,核通道。作者将网络中的变量分为敏感变量和不敏感变量(敏感是指微小改变即可对网络结果造成很大影响。),其中不敏感变量可以预设,而敏感变量则需根据实验比较得出其值。
特征提取
:这部分是和SRCNN相似的,不同点在于FSRCNN不经过对LR图像的插值,而是直接从LR图像提取子图块信息。参照SRCNN中插值后的提取块的大小为9X9,对应插值前的LR的块大小为5X5,因此,FSRCNN提取的块为5X5大小的。若输入图像为灰度,则核深度为1,而核的数量决定了该层卷积输出的特征图的维度d。因为经过特征提取部分的特征图即将送入真正的SR过程,所以维度d是至关重要的。因此
d是第一个敏感变量
,需要实验对比得出。因此该层可记为conv(5,d,1)。
压缩(这部分的高低维指的是特征图的通道数)
:这部分主要考虑到SRCNN中直接在高维特征图上对LR做SR,因此会通过增加滤波核的通道数和数量来增加参数(计算量)。因此,考虑如下思路:先对LR图像通道数进行减小,然后在低维LR特征图进行SR操作,这样会减少运算参数,最后再对生成的SR图像进行升维操作。
我们可以用s个1X1的滤波核,对来自特征提取层的d维图像进行降维处理(从d降到s),
s是第二个敏感变量
,这可以为后续的SR操作减少参数量。该层可记为conv(1,s,d)。
非线性映射
:前边的所有操作都是准备阶段,真正的SR操作在此步。而该步最重要的两个参数为特征图的通道数(d,即核的数量)和深度(卷积层的层数m,
m是第三个敏感变量
),深度m决定了SR的精度和复杂度。卷积核的尺寸为3X3,因此该部分可记为mXconv(3,s,s)。
扩展
:详细到这来读者都有一个疑问,就是为什么要有扩展层,不能直接由得到的低维SR特征图直接进行重建,进而得到可视化的SR(单或三通道)图像吗?这里作者通过实验证明,这样做会使重建的SR的PNSR比升维后再重建的SR至少降低0.3dB。扩展部分使用d个1X1的核,以期恢复到压缩前的图像形状。因此可以看到,压缩、非线性映射、扩展这三部分是对称的。扩展部分可记为conv(1,d,s)。
去卷积
:可视为卷积的逆操作,可以将小尺寸的图像恢复成大尺寸的图像。参照图4,我们通过在deconv前移动一个步长,得到deconv后移动的两个步长的区域,这样就可以实现对图像放大2倍的操作了。作者也提供了另一种看待此网络的角度,即将信息视为从HR向LR传播。这样可以更方便理解。同时为了保持对称结构,需要采取9X9的滤波器大小。该层可记为deconv(9,1,d)。去卷积不同于传统的插值方法,传统的方法对所有的重建像素都有一套共同的重建公式,而去卷积的核需要学习得到,它能够针对具体的任务,得出更精确的结果。

去卷积前的特征图如图三所示(举例)。

PReLU
:直接给出公式f(xi) = max(xi,0) + ai*min(0,xi),很明显,在原来relu 的基础上,对负半轴的梯度也能激活(即使很小),消除了部分梯度无法激活的情况。
全局结构
:Conv(5, d, 1) – PReLU – Conv(1, s, d)-PReLU – m×Conv(3, s, s) – PReLU-Conv(1, d, s) – PReLU – DeConv(9, 1, d)。全局看来,有三个参数d、s、m影响着网络的性能和速度,所以将网络记为FSRCNN(d,s,m),计算复杂度可由下式表示:
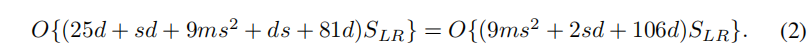
实验显示,这种对称网络结构十分有效(做超分的好像都是实验显示,没有数学推导吗)
损失函数
:使用均方误差MSE
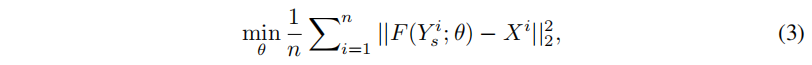
其中X为HR,Y为LR,θ为参数,n为batch size。
3.3 Differences against SRCNN: From SRCNN to FSRCNN
在这部分,作者通过逐步对SRCNN网络进行修改,以达到FSRCNN网络。每步修改后的性能如下表1所示:

- 先将SRCNN的预插值操作换成网络末端的deconv操作,伴随而来的就是输入网络图像的尺寸变化。结果是速度比SRCNN提升8.7倍。而由于deconv的核是有学习得到的,所以PSNR也提高了0.12dB。
- 单层映射被替换为压缩-4层卷积-扩展结构,虽然mapping部分由1层卷积变为了5层,但参数量却能够明显的下降,这是由于我们使用了1X1的滤波核修正特征图通道的结果(读者可以举例证明),此时速度是SRCNN的30.1倍。但是对于PSNR增加的原因,我认为作者的描述是模糊的,因为此时深度的确加深了,但是网络宽度也变窄了,很难说明具体是因为哪个原因导致的PSNR微量增加。
- 通过降低输入mapping部分的特征图深度,进一步提升了速度,41.3倍。(注意作者在此处对于降低特征图深度的描述:随着移除一些冗余的参数,网络…。所以作者认为特征图过深时,在进行卷积运算时,特征图中的很多信息是冗余的,所以不如使用更浅的特征图深度,从而降低滤波核的深度,即减少参数,减少计算量)。
由此可见,计算效率的提示并没有以牺牲网络性能为代价。这里作者留了一个点子:是否可以探索到,在保证网络性能的基础上,提升计算效率?
3.4 SR for Different Upscaling Factors
通过用一种缩放因子对网络进行预训练,然后在仅对deconv层微调的情况下,使用原来训练好的网络,对另一种缩放因子进行训练。这样由于是在除deconv层,其他层参数都高度初始化后的基础上训练的,因此网络对新的缩放因子的收敛速率非常快。如图4。
4. Experiments
4.1 Implementation Details
Training dataset
.常用于训练的91-image dataset对于深度学习来说,数据量有点小。BSD500 dataset中的图像是JPEG格式,然而JPEG格式属于有损压缩。因此作者提出了一个数据集General-100 dataset包含了100张bmp格式(无压缩)的图像,尺寸从710X704到131X112不等,这些图像有更多的边缘内容而更少的光滑区域。在训练前,需要对数据进行增强,方法如下:1. 尺寸缩小(进行4中尺寸的缩小是downscale但不是降采样downsample);2. 旋转,进行90,180,270度的旋转。最终将数据集扩大了4*5 -1= 19倍。
Test and validation dataset
.测试使用Set5 , Set14 and BSD200 dataset,验证使用从BSD500中抽取20张图
Training samples
.训练时,作者为了避免图像周围像素缺失(SRCNN的缺陷),作者在处理卷积时,根据卷积核的具体尺寸,使用padding操作。但是,在deconv时,仍无法避免像素的丢失,即期待得到的结果为(n×fsub)*2,但实际得到的为(n×fsub-n+1)**2,因此将HR图像削减(n-1)个像素。
Training strategy
. 首先,使用91数据集进行从头训练,然后当训练饱和时,再使用 General-100 dataset继续训练进行微调,实验证明,这种方法可以收敛的很快。在91数据集的卷积层学习率是0.001,去卷积的学习率是0.0001,在微调期间,各学习率削减一半。
4.2 Investigation of Different Settings
这部分作者探索了上述的三个敏感变量对网络的影响。
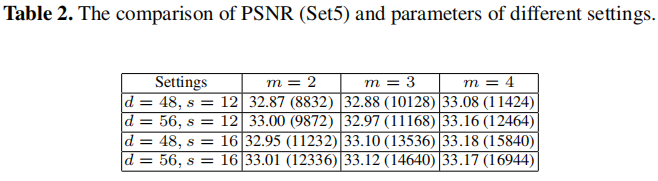
首先,固定d,s变量,探索m对网络收敛的影响,如图5a。

然后固定m,探索d,s对网络收敛的影响,如图5b所示。
在对参数量(计算量)和性能变现做综合衡量后,发现FSRCNN(56,12,4)具有最佳的综合优势。
4.3 Towards Real-Time SR with FSRCNN
探索满足人眼实时性的FPS的FSRCNN的参数设置。直接给出结论:FSRCNN(32,5,1),参数量3937,fps = 24.7。可以参考表3和表4,得到该参数下的网络对实验的影响,表中用FSRCNN-s表示FSRCNN(32,5,1)。


4.4 Experiments for Different Upscaling Factors
使用FSRCNN(56,12,4)为默认网络,训练时,先在X3尺度上训练模型,然后再微调最后一层deconv来得到对X3,X4尺度模型的训练。
4.5 Comparison with State-of-the-Arts
- Compare using the same training set.
- Compare using different training sets (following the literature).
参考表3、表4。

5. Conclusion
提出的模型能够满足实时性的要求,并且目标是针对低级的计算机视觉任务。
References