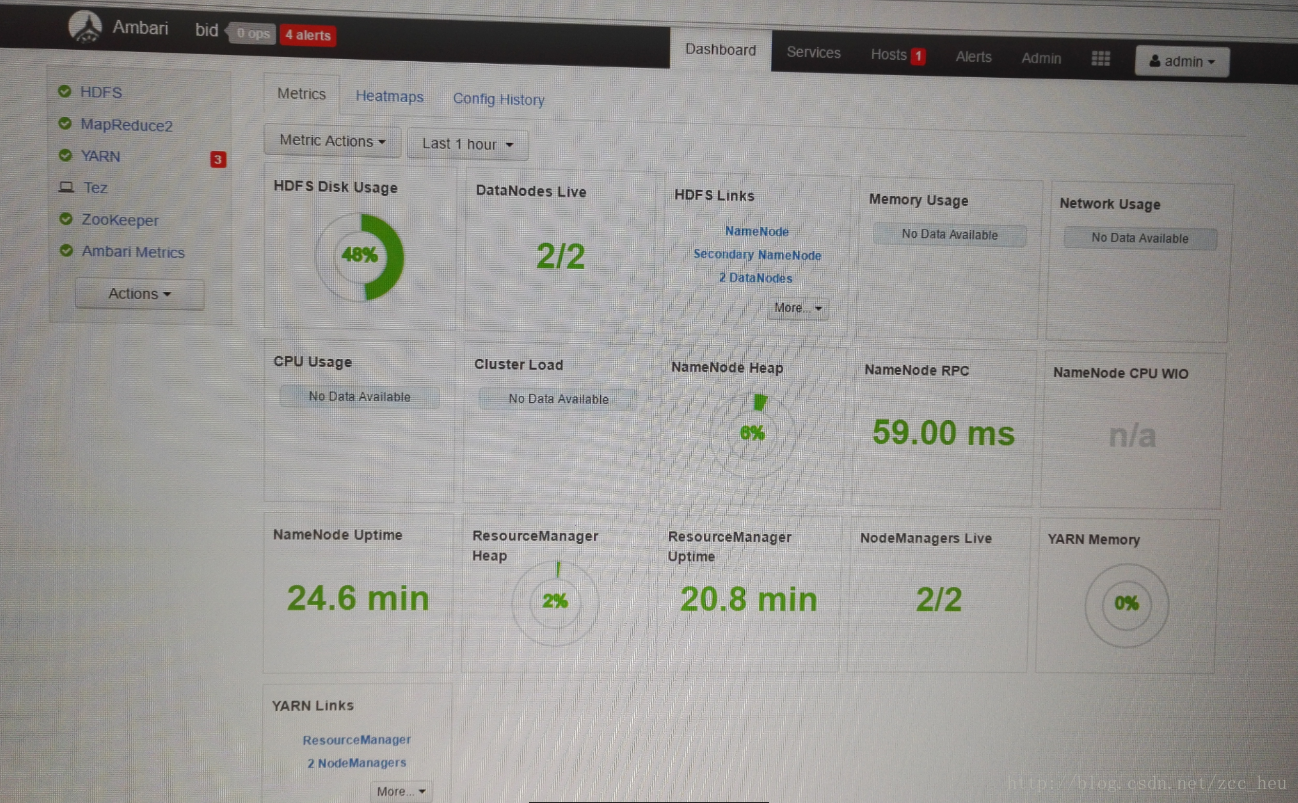
一、环境准备
在使用ambari搭建hadoop集群之前需要准备一些环境。本文使用三台机器搭建hadoop集群。IP分别为:
ubuntu 的 IP :192.168.127.138
hadoop1 的 IP: 192.168.127.135
hadoop2 的 IP:192.168.127.134
1.三台机器之间相互注册IP并且需要配置全域名
打开ubuntu的host文件配内容如下:
$ vim /etc/hosts
#127.0.0.1 localhost
#127.0.1.1 ubuntu
# The following lines are desirable for IPv6 capable hosts
#::1 ip6-localhost ip6-loopback
#fe00::0 ip6-localnet
#ff00::0 ip6-mcastprefix
#ff02::1 ip6-allnodes
#ff02::2 ip6-allrouters
192.168.127.138 ubuntu.test.com ubuntu
#192.168.127.139 agent.test.com agent
192.168.127.134 hadoop2.test.com hadoop2
192.168.127.135 hadoop1.test.com hadoop1
把次hosts文件复制到其他两台机器上。
2.安装ntp服务
需要在每台主机上安装ntp协议。这时一种用于在多台主机之间进行时间同步的协议。在每台主机上使用以下命令即可。
$ sudo apt-get install ntp
$ service ntp start
3.安装jdk
此处就不在赘述jdk的安装了可以看我前一篇文章
ubuntu14.04安装ambari
中jdk的安装配置
4.安装ssh服务并开启远程登录到root账户功能
安装ssh服务使机器可以远程使用ssh登录。
$ sudo apt-get install openssh-server
安装完成后配置ssh的配置文件/etc/ssh/sshd_config使远程ssh登录时可以使用root账户登录.
注释PermitRootLogin without-password后添加PermitRootLogin yes。
# sudo vim /etc/ssh/sshd_config
# Authentication:
LoginGraceTime 120
#PermitRootLogin without-password
PermitRootLogin yes
StrictModes yes
5.配置ssh免密码登录
在ambari-server机器ubuntu上使用root用户在根目录执行以下命令:
# ssh-keygen -t rsa
# cd .ssh
# cat id_rsa.pub >>authorized_keys
# scp authorized_keys root@hadoop1:/root/.ssh
# 输入密码
# scp authorized_keys root@hadoop2:/root/.ssh
# 输入密码
在ubuntu机器上验证是否可以免密码登录到机器hadoop1和机器hadoop2上
# ssh hadoop2
# ssh hadoop1
二、使用ambari搭建hadoop集群
1.启动ambari-server服务
执行ambari-server start命令启动ambari服务并在浏览器中输入
http://192.168.127.138:8080
或者
http://ubuntu:8080出现如下界面:
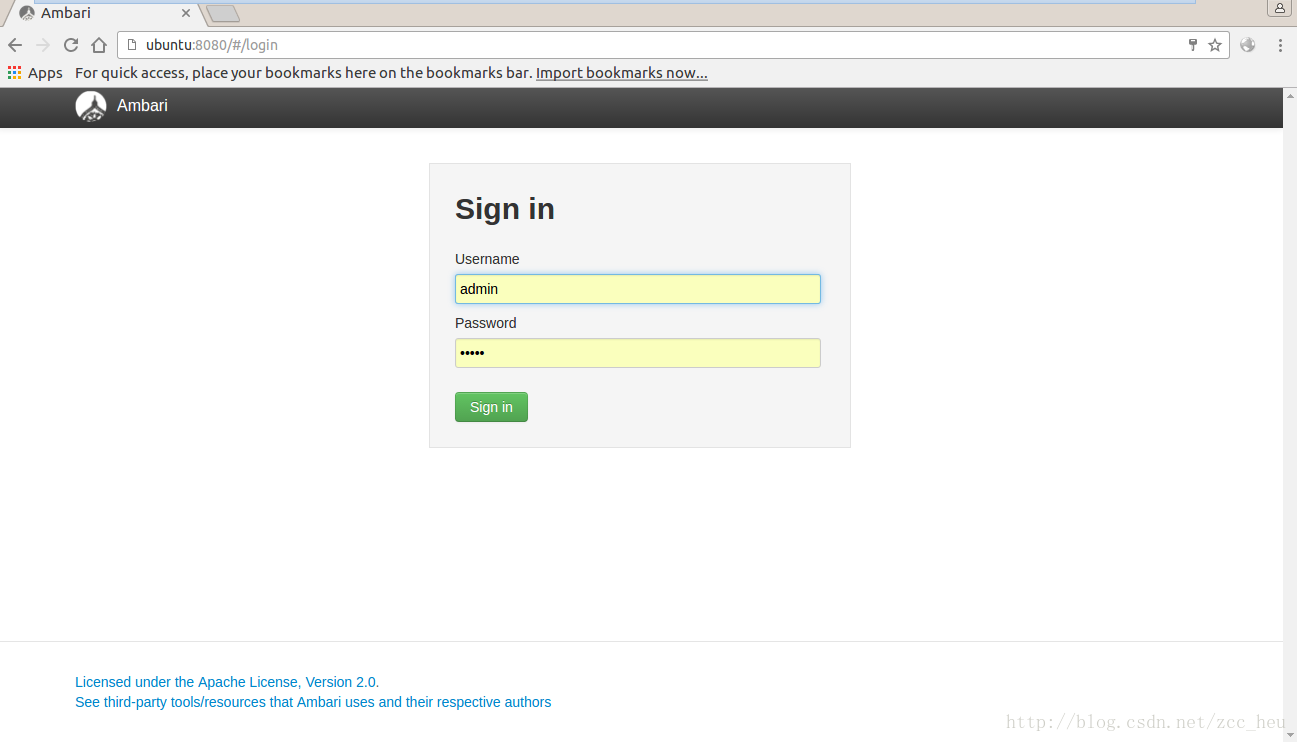
登录之后出现hadoop搭建界面:
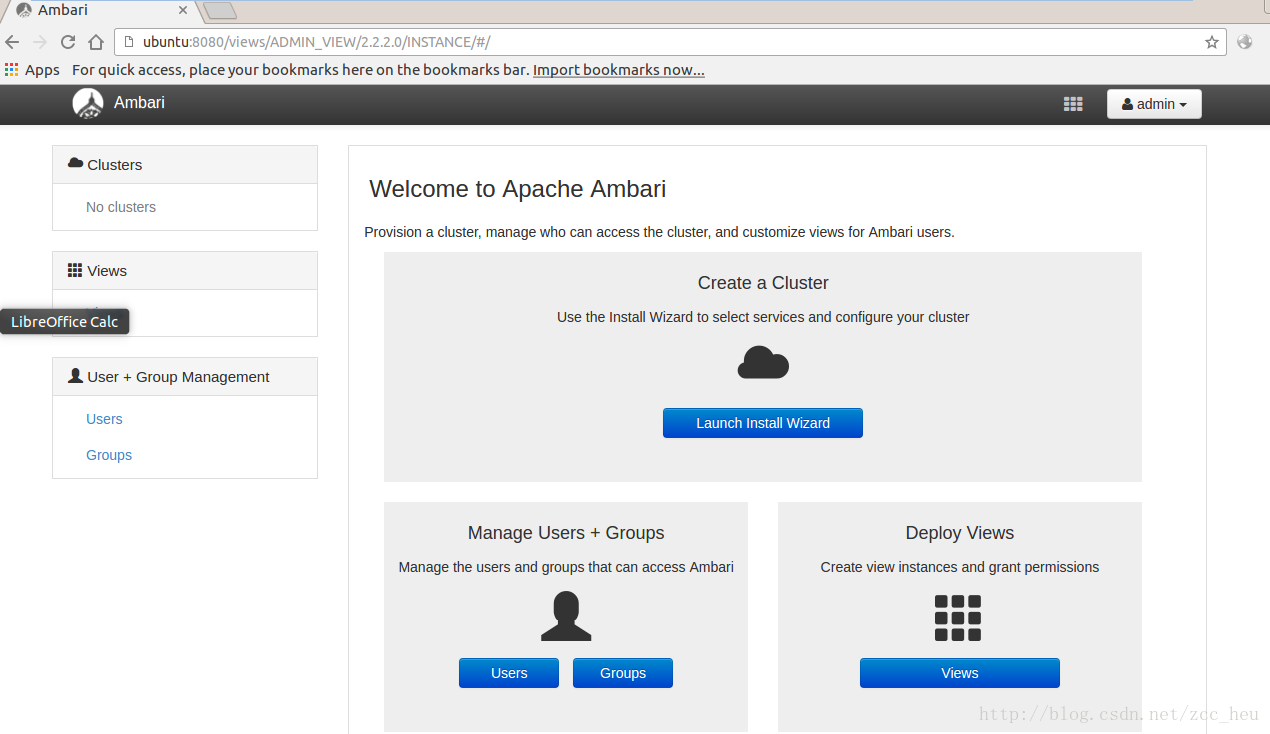
2.Get Started.填入集群的名称
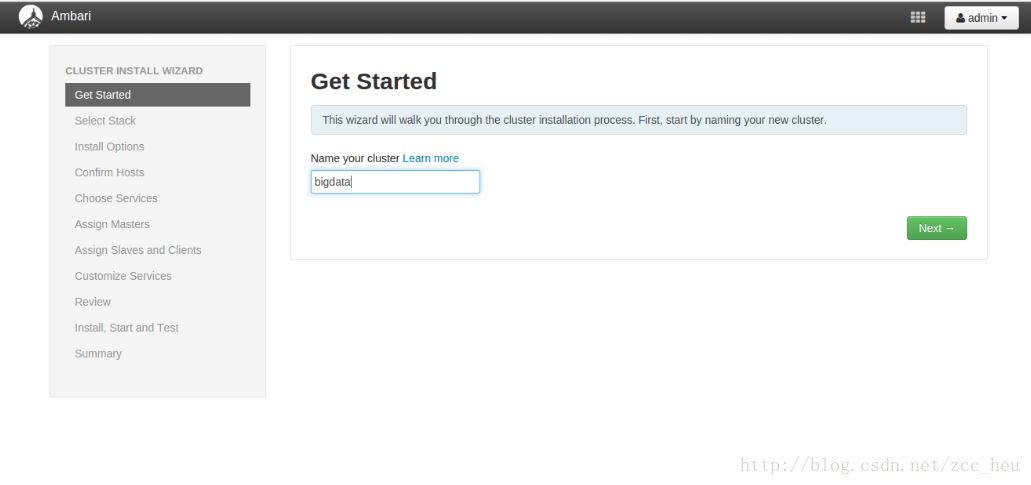
3.Select Stack.选择要安装的版本,这里我选择了HDP2.4
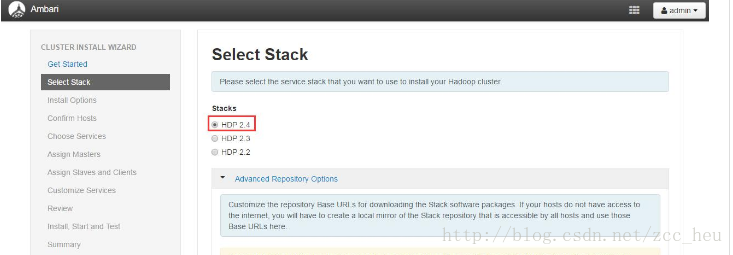
4.Confirm Hosts.选择要安装hadoop集群的集群
我在这步卡了好久,在这里有一点需要注意target hosts必须填入FQDN即形如:xxx.xxx.com的形式,而并不是简单的hostname。
可以通过hostname和hostname -f来验证域名是否一样。
(PS:第一次这一步的时候这样配置没有任何问题。第二次的时候出现了ambari-server的/var/log/ambari-server/ambari-server.log中出现找不到hostname的错误,我也不知道为什么,我在网上搜索了很多都说是中文版本的问题,应该安装英文版本的。但是我后来调了调hosts文件就好使了感觉很莫名其妙。)
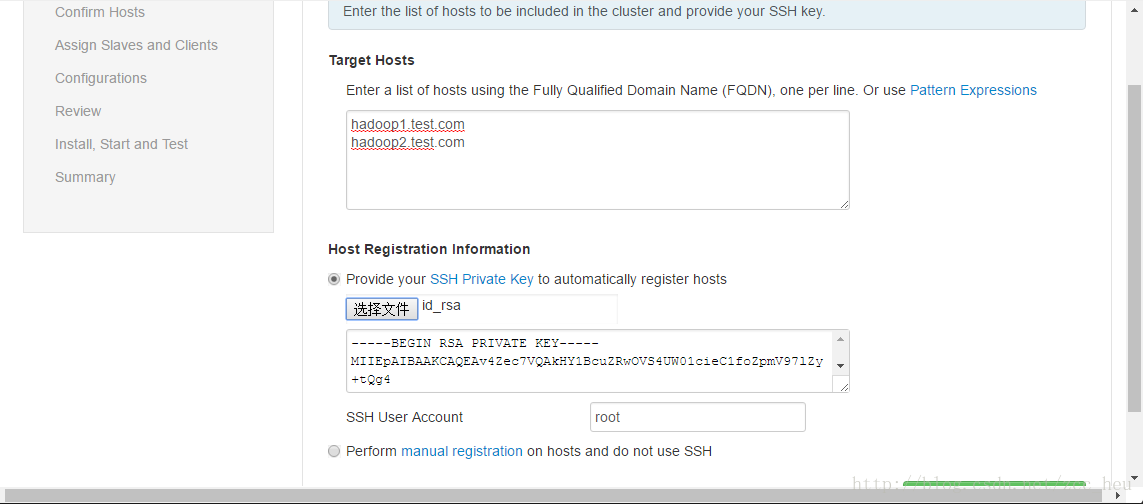
5.Confirm Hosts.等待在每一台hadoop集群机器上安装ambari-agent

(PS:这图是盗别人的结果和我的一样知识前面配置的域名不一样。忘了截图了)
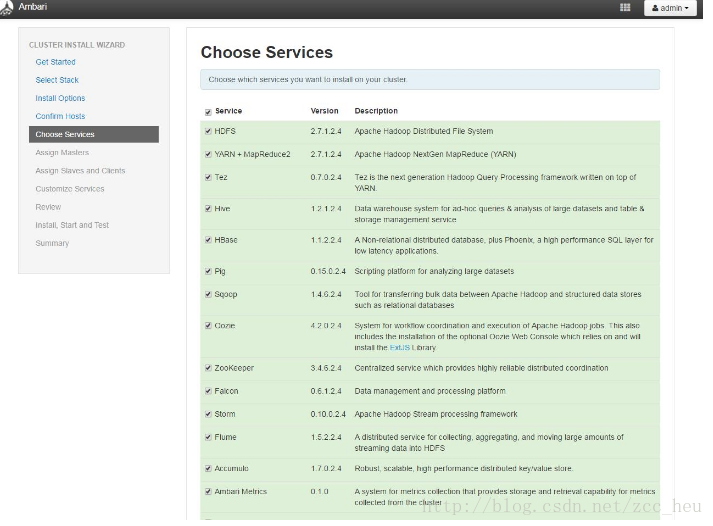
6.Choose Services.选择要安装的服务。这里我只选择了HDFS 和YARN这两个。可以根据自己的实际情况安装服务。
7.Assign Masters各个服务master配置,这里我选择了默认配置

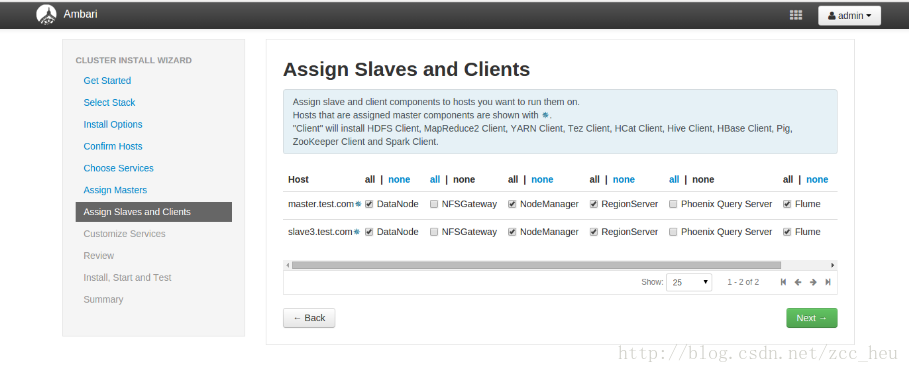
8.Assign Slaves and Clients服务的Slaves和Clients节点配置
9.Customize Services服务的客制化配置(会提示必须配置的选项)
10.Review.显示配置信息

11.开始安装各种服务(真正的坑才刚刚开始)
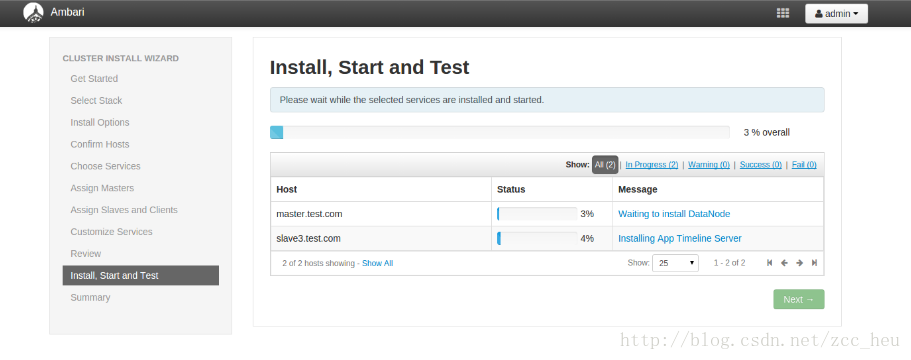
安装过程报的错误
(1)错误1
Ambari agent process is not heartbeating on the hostambari-agent没有运行,我在hadoop1和hadoop2上启动了之后还是报同样的错误。打开/var/log/ambari-agent/ambari-agent.log发现报ascii codec can’t decode byte 0xe8 in position 0:ordinal not in range(128)这个错误。
Solution:找到param.py文件在其中加入
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
然后重新启动
(2) 错误2
Execution of '/usr/bin/apt-get -q -o Dpkg::Options::=--force-confdef --allow-unauthenticated --assume-yes install 'hadoop-2-4-.*-client'' returned 100. E: dpkg was interrupted, you must manually run 'dpkg --configure -a' to correct the problem.
Solution:
dpkg --configure -a
(3)错误3
Traceback (most recent call last):
File "/var/lib/ambari-agent/cache/stacks/HDP/2.0.6/hooks/before-START/scripts/hook.py", line 39, in <module>
BeforeStartHook().execute()
File "/usr/lib/python2.6/site-packages/resource_management/libraries/script/script.py", line 219, in execute
method(env)
File "/var/lib/ambari-agent/cache/stacks/HDP/2.0.6/hooks/before-START/scripts/hook.py", line 28, in hook
import params
File "/var/lib/ambari-agent/cache/stacks/HDP/2.0.6/hooks/before-START/scripts/params.py", line 158, in <module>
ambari_db_rca_password = config['hostLevelParams']['ambari_db_rca_password'][0]
TypeError: 'int' object has no attribute '__getitem__'
Solution:找到/var/lib/ambari-agent/cache/stacks/HDP/2.0.6/hooks/before-START/scripts/params.py这个文件把155行到158行换成如下代码
ambari_db_rca_url = config['hostLevelParams']['ambari_db_rca_url']
ambari_db_rca_driver = config['hostLevelParams']['ambari_db_rca_driver']
ambari_db_rca_username = config['hostLevelParams']['ambari_db_rca_username']
ambari_db_rca_password = config['hostLevelParams']['ambari_db_rca_password']
(4)错误4
resource_management.core.exceptions.Fail: Execution of 'curl -sS -L -w '%{http_code}' -X PUT -T /usr/hdp/2.4.3.0-227/hadoop/mapreduce.tar.gz 'http://hadoop1.test.com:50070/webhdfs/v1/hdp/apps/2.4.3.0-227/mapreduce/mapreduce.tar.gz?op=CREATE&user.name=hdfs&overwrite=True&permission=444'' returned status_code=403.
{
"RemoteException": {
"exception": "IOException",
"javaClassName": "java.io.IOException",
"message": "Failed to find datanode, suggest to check cluster health."
}
}
Solution:我使用这条命令/usr/hdp/2.1.2/hadoop-hdfs/bin/hdfs datanode手动启动hostname节点发现报错
HttpServer.start() threw a non Bind IOException java.net.BindException: Port in use: localhost:0于是我在host那么文件中添加了如下代码:
127.0.0.1 localhost然后重新启动就成功了。
错误5
resource_management.core.exceptions.Fail: Execution of '/usr/sbin/ambari-metrics-grafana start' returned 1. Starting Ambari Metrics Grafana: .... FAILED
Solution:手动启动后成功了
至此彻底完成了ambari搭建hadoop集群~