女主宣言
本文将给大家介绍的是在Influxdb中Select查询请求结果中涉及到的一些数据结构,对于Influxsql的查询语句不太熟悉的同学,可以在先了解了解:
https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration
PS:丰富的一线技术、多元化的表现形式,尽在“
HULK一线技术杂谈
”,点关注哦!
数据结构
1
Series
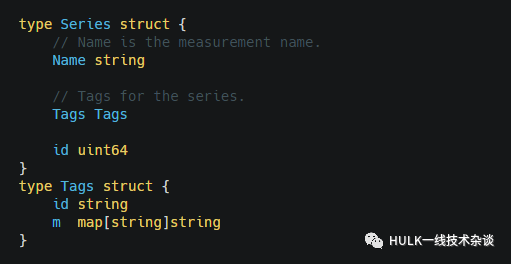
Series其实就是measurement和tags的组合,tags是tag key和tag value的map.这个Tags的id是如何产生的呢,其实就是对tag key和tag value编码到
[]byte: agkey1\0tagkey2\0…\tagvalue1\0tagvalue2\0…
具体实现定义在query/point.go中的encodeTags。
2
Row
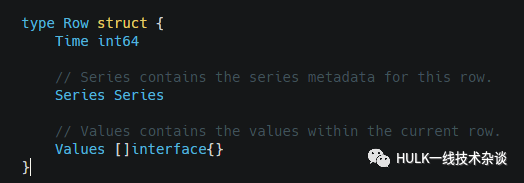
Row表示查询结果集中的每一行, 其中的Values表示是返回的Fields的集合
3
bufFloatIterator

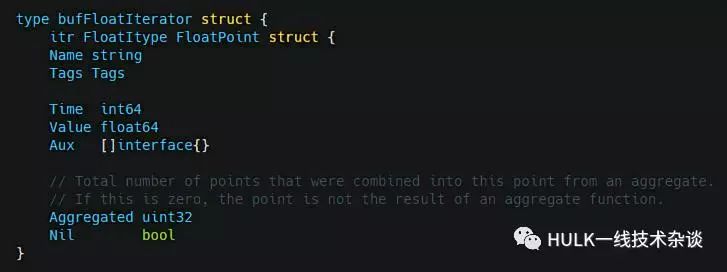
bufFloatIterator相当于c里面的链表元素,itr指向下一个元素的指针,buf表示当前元素,即FloatPoint类型的链表的迭代器。
FloatPoint
FloatPoint
定义在query/point.gen.go中, 表示一条field为float类型的数据
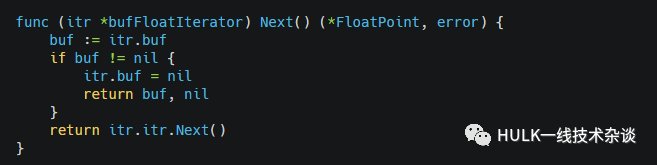
Next实现
当前Iterator的值不为空,就返回当前的buf, 当前的值为空,就返回itr.itr.Next(),即指向的下一个元素
unread: iterator回退操作

4
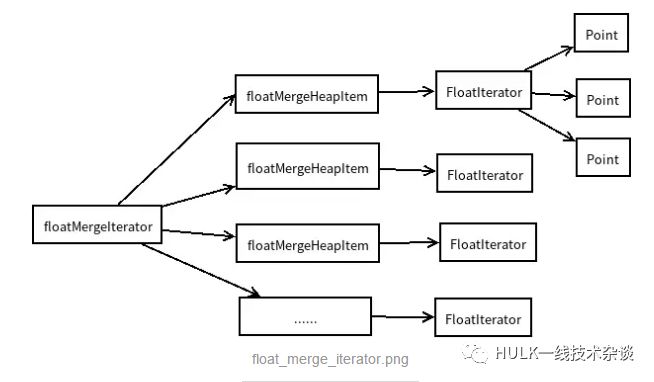
floatMergeIterator
floatMergeIterator组合了多个floatIterator
因为要作merge, 这里需要对其管理的所有Interator元素作排序,这里用到了golang的container/heap作堆排。
因为要用golang的container/heap来管理,需要实现下面规定的接口,

floatMergeIterator定义中的floatMergeHeap即实现了上面的接口,我们主要来看一下比较函数的实现,比较的其实就是FloatPoint。
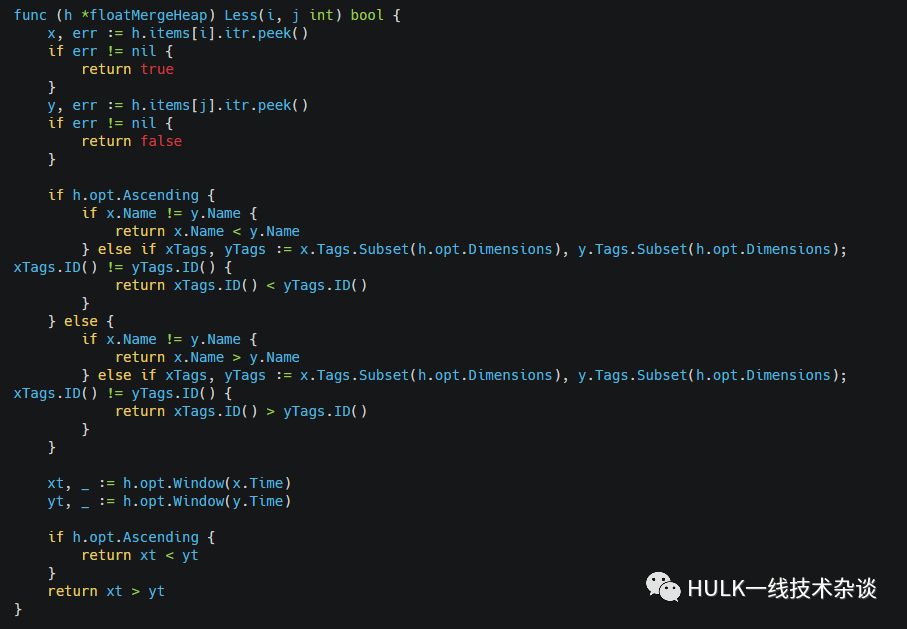
比较的优先级先是FloatPoint的measurement名,然后是tagset id, 最后是time,将这个比较函数我们就可以知道.
结构
Next函数的实现
一张长图
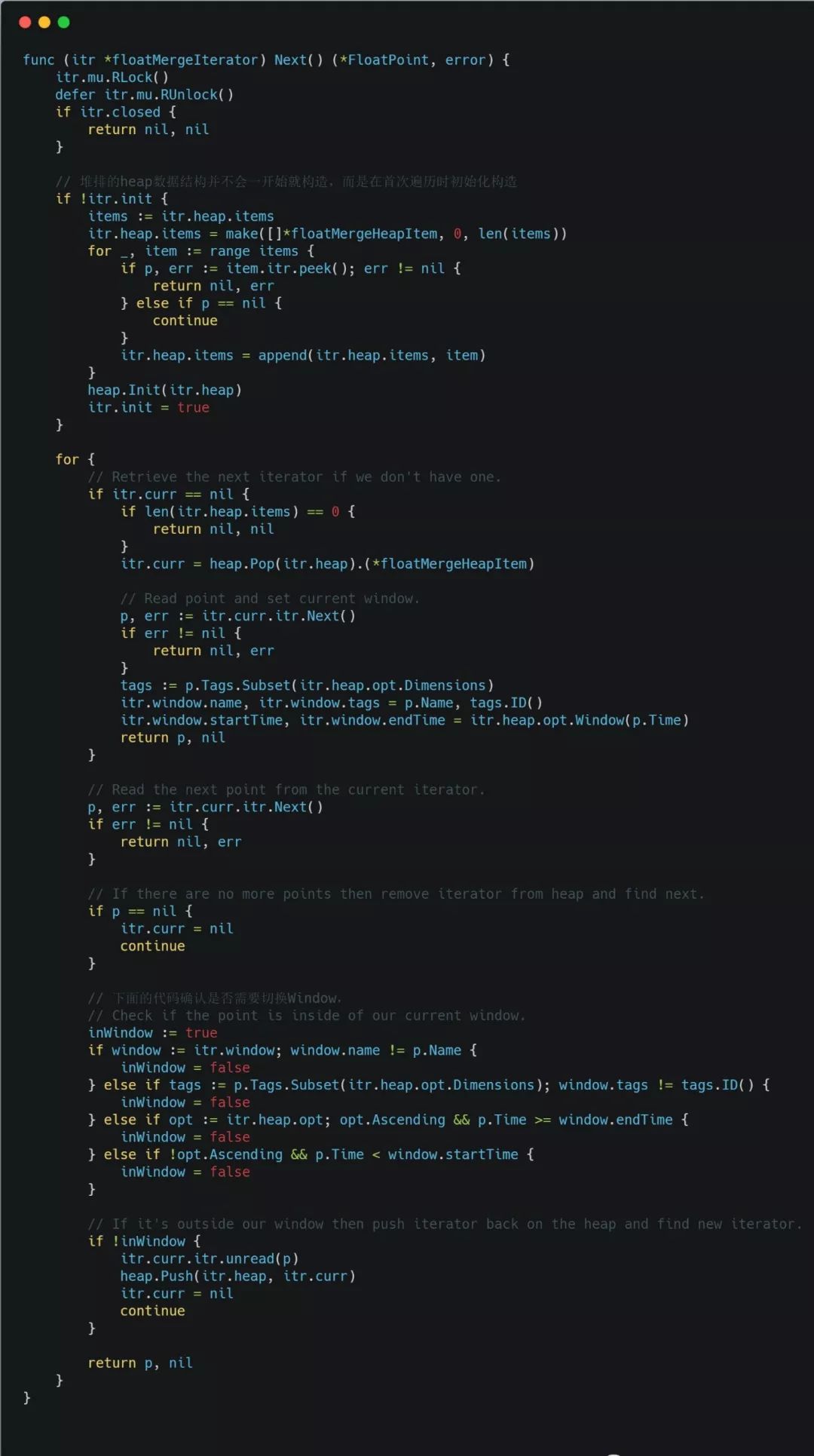
结合上面的Less函数可知,针对所有的FloatPoint, 排序的最小单位是Window(由measurement name, tagset id, time window组成),属性同一Window的FloatPoint不再排序。如果是按升级规则遍历,则遍历的结果是按Window从小到大排,但同一Window内部的多条Point,时间不一定是从小到大的。
5
floatSortedMergeIterator
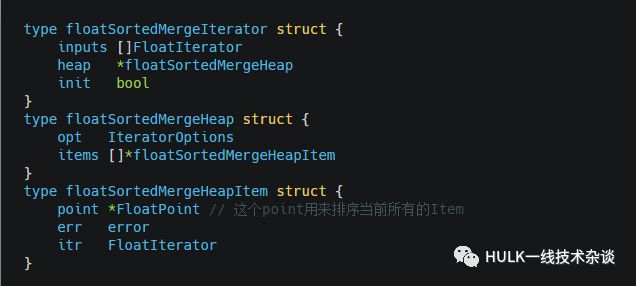
同样它也借助了golang/container中的heap, 与floatMergeIterator相比它实现了全体Point的排序遍历,我们来看一下是如何实现的;
pop函数:
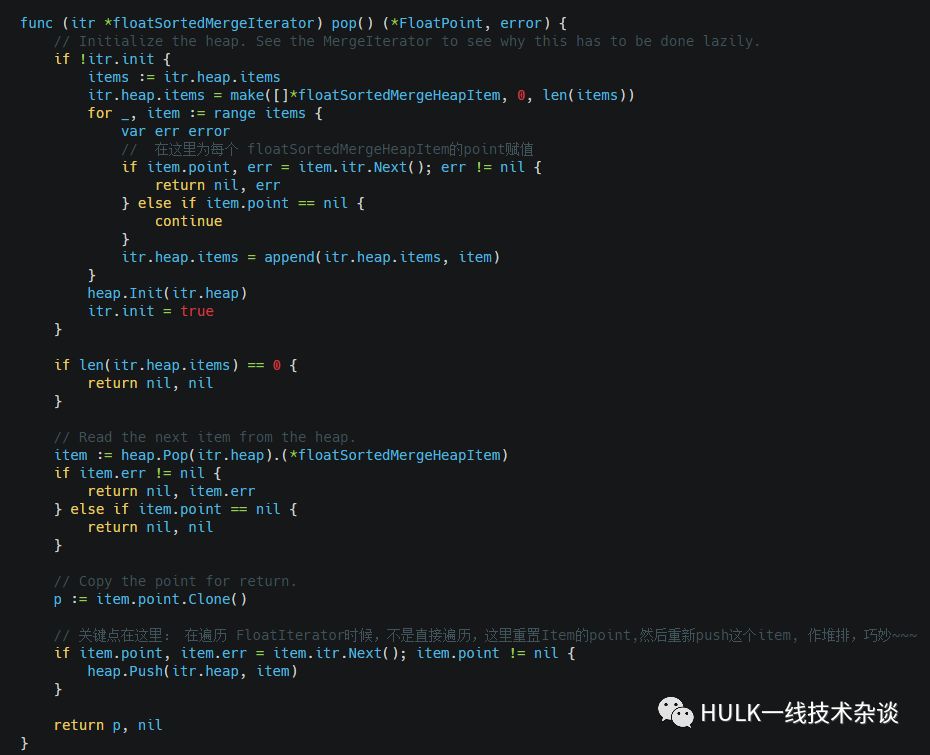
对所有Iterator包含的所在FloatPoint,都从排序,没有Window的概念.
6
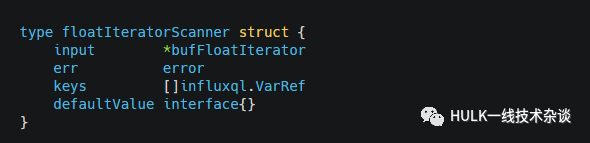
floatIteratorScanner
floatIteratorScanner
将floatIterator的值扫描到map里。
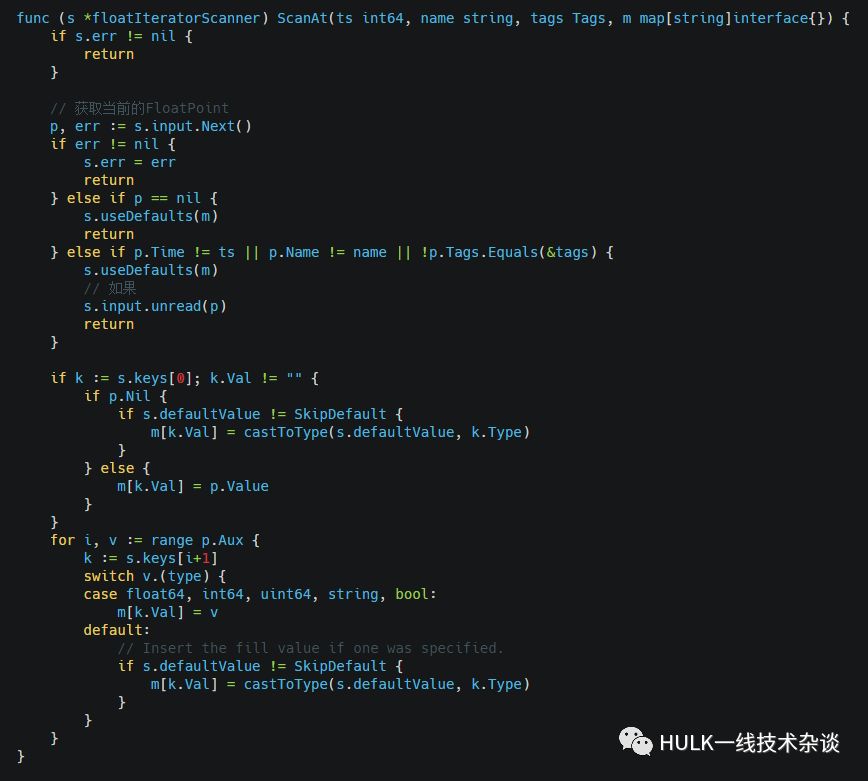
ScanAt
在floatIterator中找满足条件的Point, 条件是ts, name, tags均相等,实现比较简单
7
floatParallelIterator
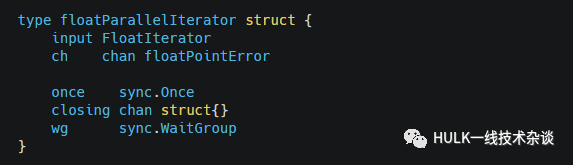
在一个单独的goroutine里面循环调用floatIterator.Next获取FloatPoint,然后写入到chan中:
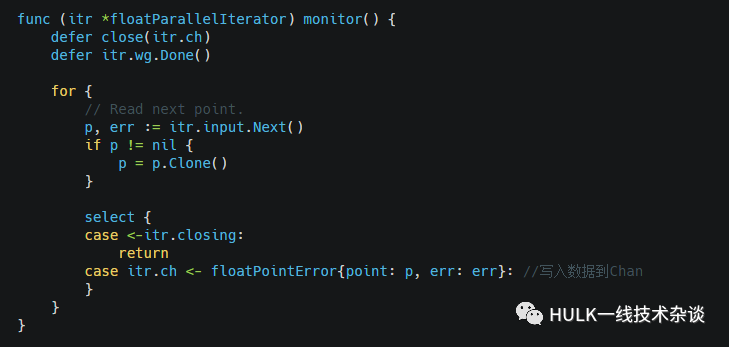
使用的时候,调用Next, 从上面的Chan中读数据:
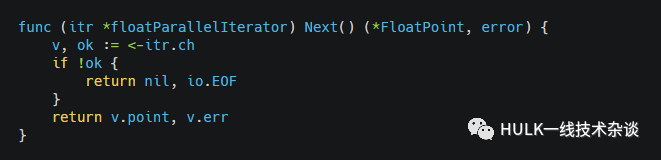
8
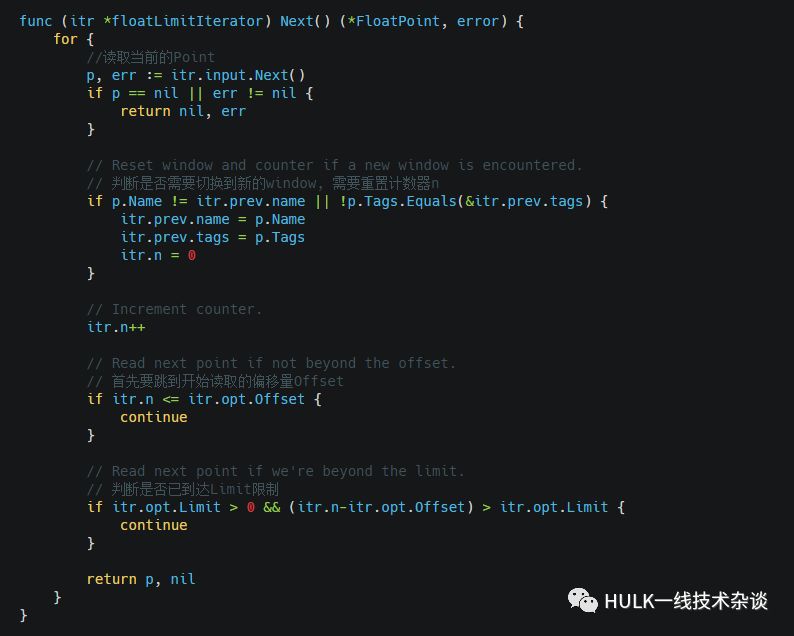
floatLimitIterator
限制在每个window中读取的Point个数
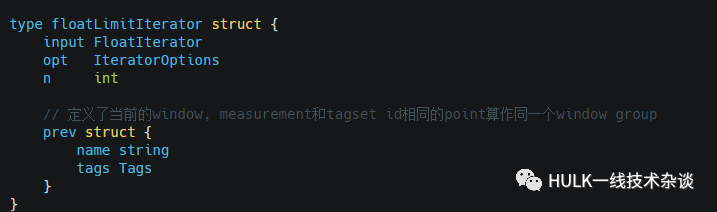
next
9
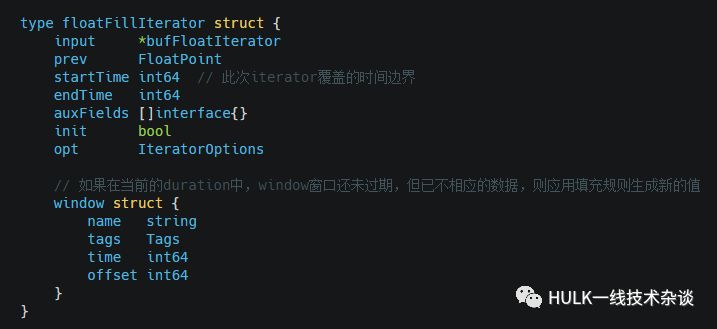
floatFillIterator
运行在select中的Group by time fill(…), 在当前的interval的window中,如果没有查询到值,则使用相应的添充规则生成相应的值
具体可参见:
group-by-time-intervals-and-fill
定义:
10
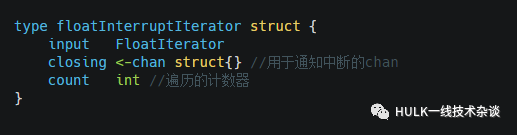
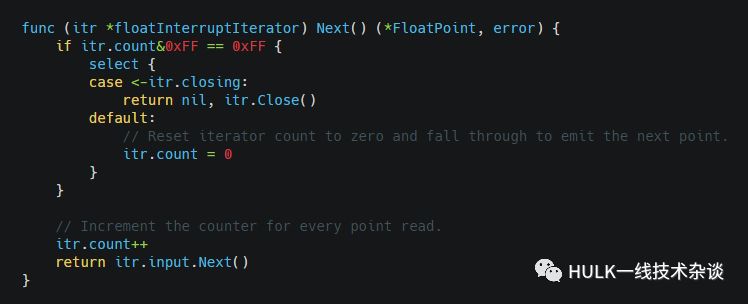
floatInterruptIterator
每遍历N条数据后,检测下遍历是否需要中断
定义:
Next
11
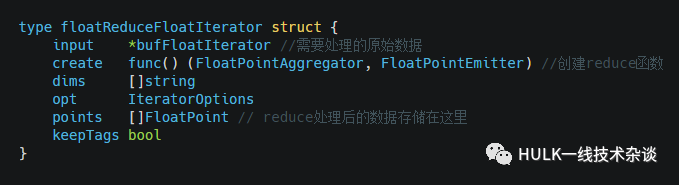
floatReduceFloatIterator
对每个interval内的数据作reduce操作
定义:
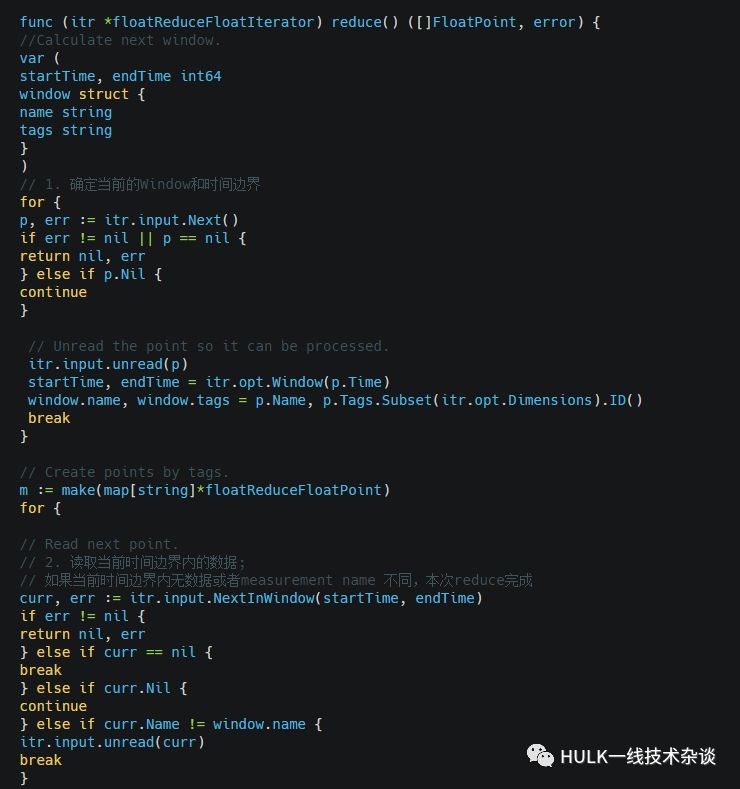
reduce()
返回处理后的points, 函数较长,但逻辑比较简单
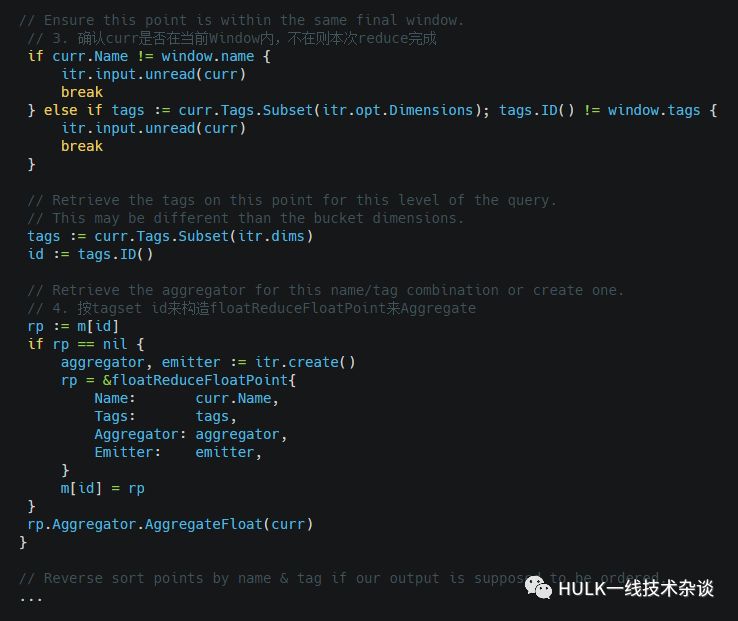
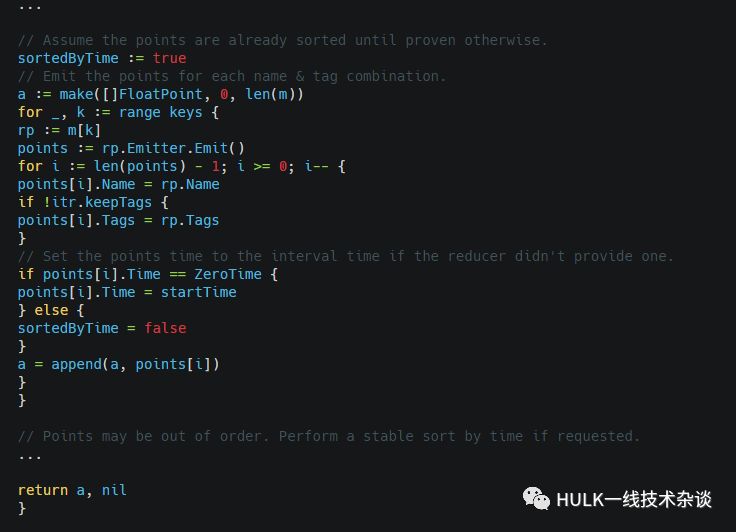
12
CallIterator
CallIterator实现了聚合函数的Iterator: count, min, max, sum, first, last, mean, distinct,Median….主要是使用我们上面介绍的一系列的ReduceIterator,提供相应的Reducer, 实现AggregateFloat和Emit这两个函数
13
IteratorOptions
构建Iterator时用到的一些配置选项, 包含的内容较多
定义:
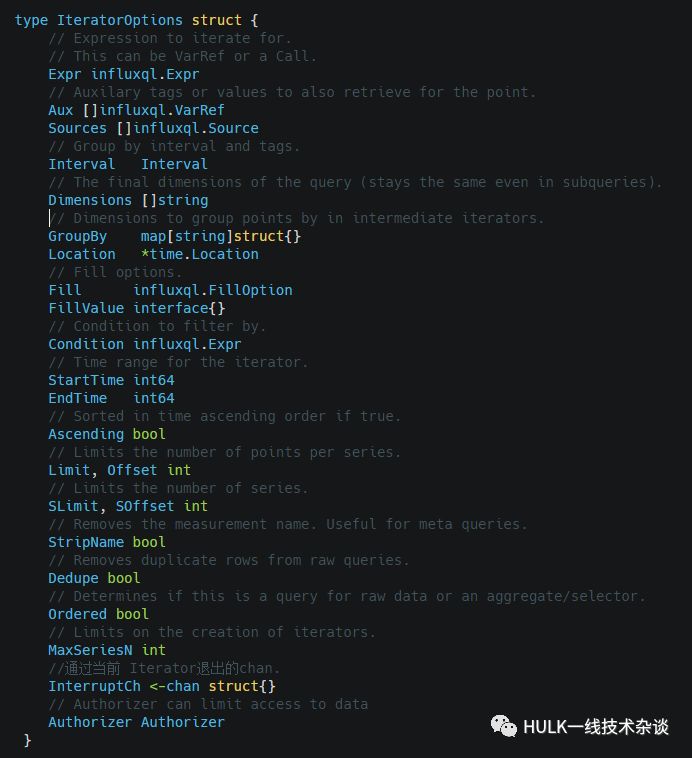
14
Cursor
select后会得到这个cursor,用来遍历查询结果
定义:
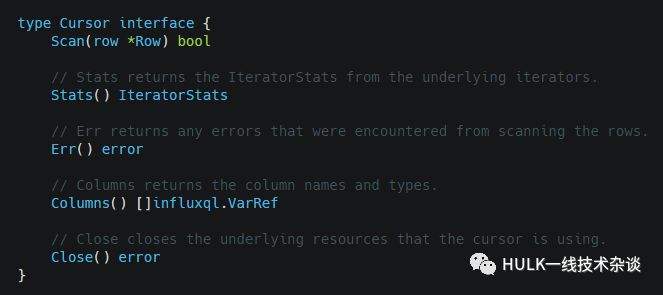
Scan
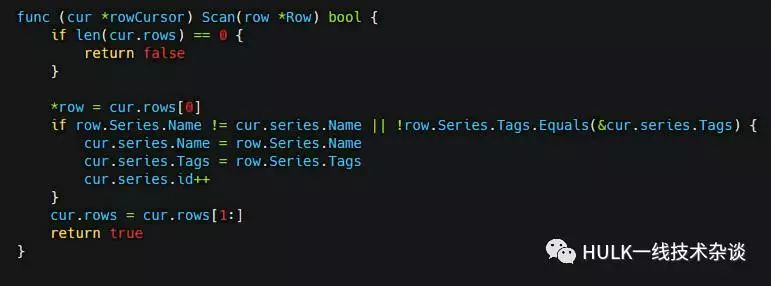
15
floatIteratorMapper
*IteratorMapper系列, 主要作用是遍历cursor
定义
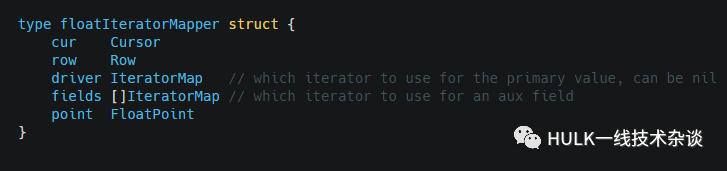
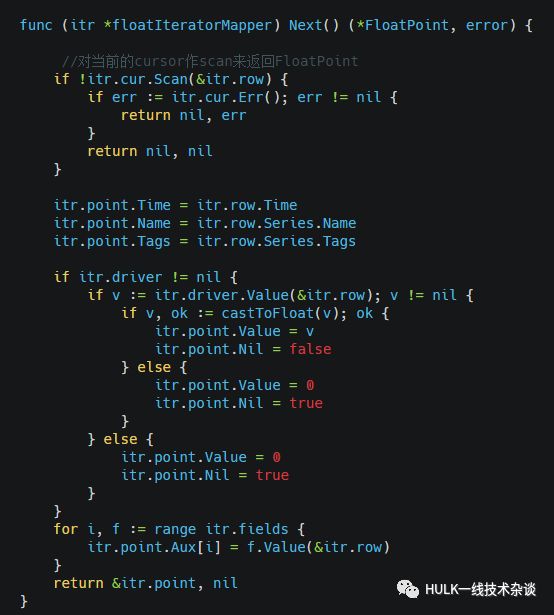
我们来看一下Next接口, 对当前的cursor作scan来返回FloatPoint
总结
以上就是Influxdb的select查询请求结果涉及到的一些数据结构
HULK一线技术杂谈
由360云平台团队打造的技术分享公众号,内容涉及
云计算
、
数据库
、
大数据
、
监控
、
泛前端
、
自动化测试
等众多技术领域,通过夯实的技术积累和丰富的一线实战经验,为你带来最有料的技术分享
