Part1
L4T ubuntu
GPU架构抽象、GPU硬件平台、基于ARM 的GPU平台架构和CUDA并行计算模式
(1)GPU架构抽象
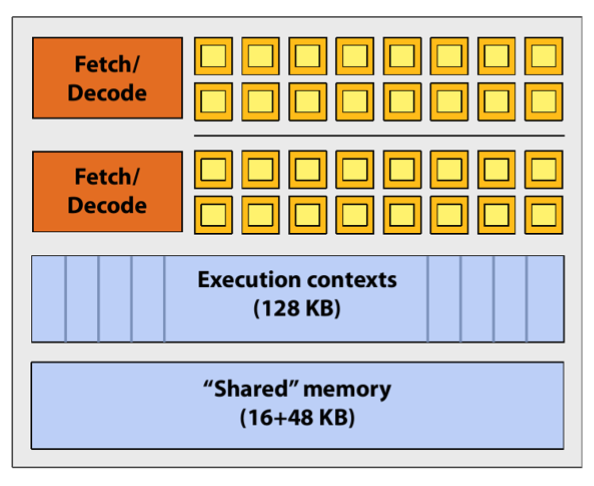
GPU
包含多个流多处理器(
SM
),上图为一个
SM
示意图,其中黄色方块为
CUDA core。
(2)GPU硬件平台

上图为NVIDIA于2020年发布的GA100的核心架构图,由图可看出该架构共包含108个SM。
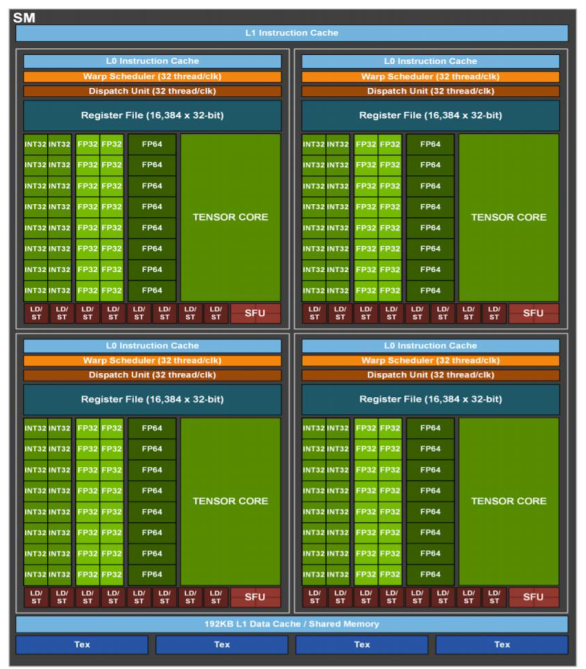
上图为GA100架构中一个流多处理器的架构,由上图得知GA100架构中的SM包含64个INT32核心,64个FP32核心,32个FP64核心和4个Tensor核心。
(3)基于ARM的GPU平台架构
主要介绍了Jetson nano和Jetson Xavier NX开发者套件的技术规格。参见下表:
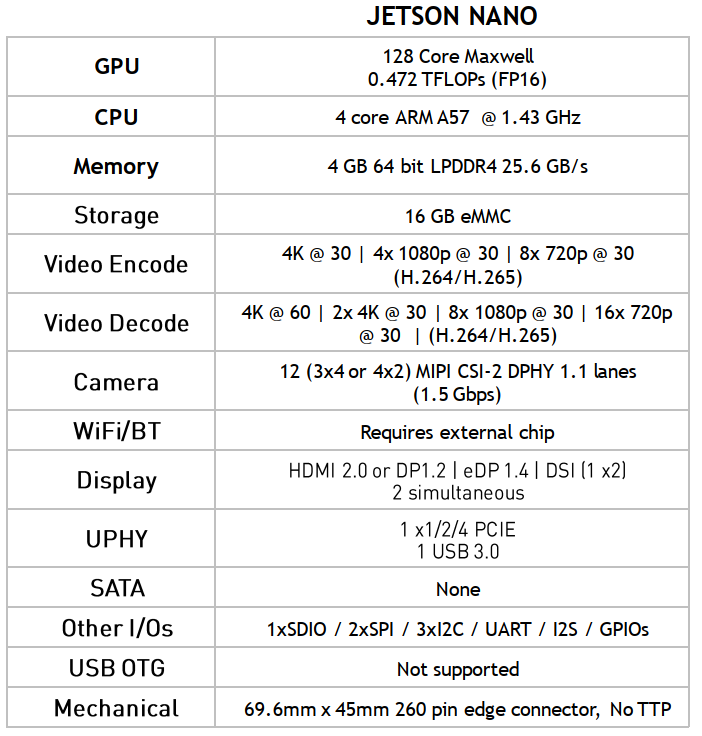
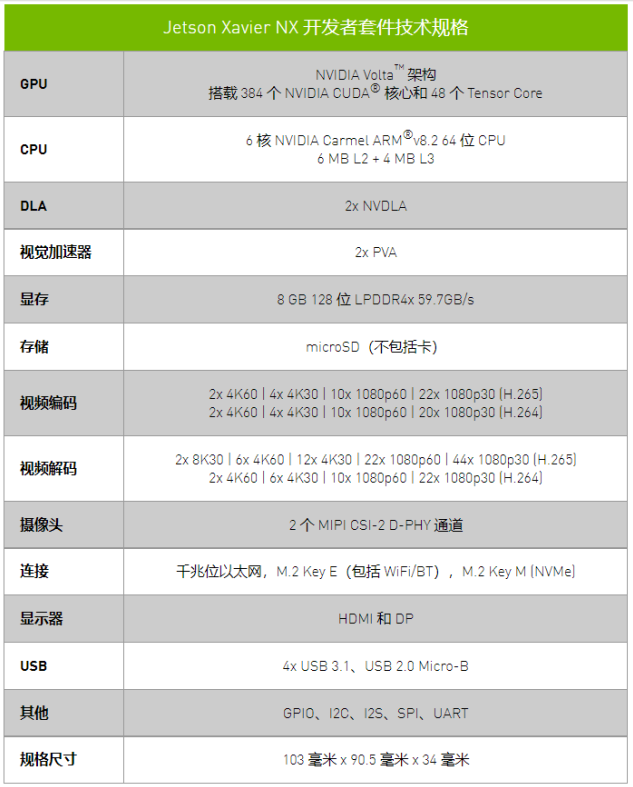
(4)CUDA并行计算模式
并行计算是同时应用多个计算资源解决一个计算问题,对计算密集型任务友好。
CUDA程序编写
执行空间说明符:__global__、__device__和__host__(概念简单看看没鸟用,写多了就记住了)
__global__
用于声明一个核函数,该函数
(1)在设备(指老黄的卡)上执行
(2)可从主机(CPU)调用,可在计算能力为3.2(老黄的不同类型的卡拥有不同的计算能力)或更高的设备调用。
(3)必须具有void返回类型,并且不能是类的成员(但可以被类成员调用)。
(4)对(核函数)的任何调用都必须指定其执行配置(执行配置即<<<>>>)。
__global__ void add_array(const double* x, const double* y, double* z){
//...
}
int main(){
//...
add_array<<<grid_size, block_size>>>(d_x, d_y, d_z);
//...
}(5)(核函数)的执行是异步的,意思是还没算完它就返回了(主要突出一个怪)。
__device__
用于声明一个函数,该函数
(1)在设备上执行
(2)只能在设备上调用
(3)不能和__global__一起使用(包含一样的buff,冲突了)。
__host__
用于声明一个函数,该函数
(1)在主机上执行
(2)只能从主机调用
(3)不能和__global__一起使用,
但是
能和__device__使用(被__device__和__host__同时声明的函数,在两种设备上都可以执行)。比如下边这个鸟函数
// w0, w1, w2, and w3 are the four cubic B-spline basis functions
__host__ __device__ float w0(float a) {
// return (1.0f/6.0f)*(-a*a*a + 3.0f*a*a - 3.0f*a + 1.0f);
return (1.0f / 6.0f) * (a * (a * (-a + 3.0f) - 3.0f) + 1.0f); // optimized
}对以上调用和执行方式做一个简单总结,如下:
|
|
调用位置 |
执行位置 |
|
__device__ float func() |
device |
device |
|
__global__ void func() |
host |
host & device(arch>3.0) |
|
__host__ float fun() |
host |
host |
(怎么感觉第三个有点多余呢。。。)
CUDA程序编译
nvcc XX.cu
nvcc编译器的详细命令参数等参考下方链接:
https://developer.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
CUDA程序性能分析
通过命令
nvprof app.exe即可生成GPU timeline,同时可以结合nvvp或者nsight进行可视化分析。
实验
向量加实例
#include <math.h>
#include <stdio.h>
void __global__ add(const double *x, const double *y, double *z, int count)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if( n < count)
{
z[n] = x[n] + y[n];
}
}
void check(const double *z, const int N)
{
bool error = false;
for (int n = 0; n < N; ++n)
{
if (fabs(z[n] - 3) > (1.0e-10))
{
error = true;
}
}
printf("%s\n", error ? "Errors" : "Pass");
}
int main(void)
{
const int N = 1000;
const int M = sizeof(double) * N;
double *h_x = (double*) malloc(M);
double *h_y = (double*) malloc(M);
double *h_z = (double*) malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1;
h_y[n] = 2;
}
double *d_x, *d_y, *d_z;
cudaMalloc((void **)&d_x, M);
cudaMalloc((void **)&d_y, M);
cudaMalloc((void **)&d_z, M);
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, h_y, M, cudaMemcpyHostToDevice);
const int block_size = 128;
const int grid_size = (N + block_size - 1) / block_size;
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost);
check(h_z, N);
free(h_x);
free(h_y);
free(h_z);
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
return 0;
}