文章目录
一.Redis简介
1.NoSQL简介
NoSQL,全名为Not Only SQL,指的是非关系型的数据库。随着访问量的上升,网站的数据库性能出现了问题,于是NoSQL被设计出来。

(1)NoSQL的优缺点
优点
- 高可扩展性、分布式计算、低成本
-
架构的灵活性,半结构化数据没有复杂的关系
缺点
- 没有标准化
- 有限的查询功能
- 最终一致是不直观的程序
2.Redis简介
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API并提供多种语言的 API的非关系型数据库。
(1)Redis的优缺点
(2)Redis支持的数据类型
-
String字符串:set key value
string类型是
二进制安全
的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。string类型是Redis最基本的数据类型,一个键
最大能存储512MB
。 -
Hash(哈希) hmset name key1 value1 key2 value2
Redis hash 是一个键值(key=>value)对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。 -
List(列表):
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
lpush name value: 在 key 对应 list 的头部添加字符串元素
rpush name value: 在 key 对应 list 的尾部添加字符串元素
lrem name index: key 对应 list 中删除 count 个和 value 相同的元素
llen name : 返回 key 对应 list 的长度 -
Set(集合): sadd name value
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 -
zset(sorted set:有序集合): zadd name score value
每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
(4)Redis持久化
Redis 是一个
内存数据库
,与传统的MySQL,Oracle等关系型数据库直接将内容保存到硬盘中相比,内存数据库的
读写效率
比传统数据库要快的多(内存的读写效率远远大于硬盘的读写效率)。但是保存在内存中也随之带来了一个缺点,一旦
断电或者宕机
,那么内存数据库中的
数据将会全部丢失
。
目标
:
- 持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
- Redis 提供了两种持久化方式:RDB(默认) 和AOF
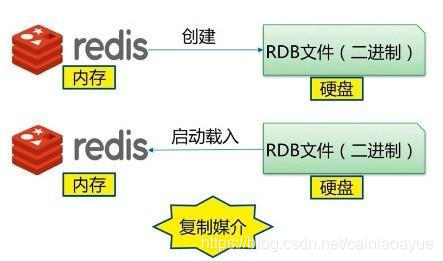
(5)Redis持久化-RDB
RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
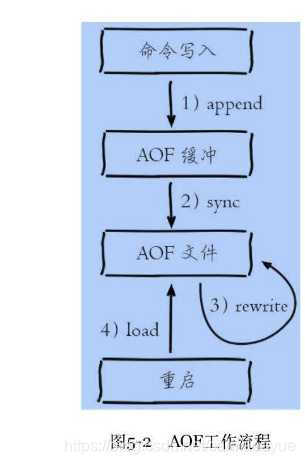
(6)Redis持久化:AOF
RDB 持久化存在一个缺点是一定时间内做一次备份,如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)。持久化方式 AOF 则是通过保存Redis服务器所执行的写命令来记录数据库状态。
二.Redis安装与配置
1.Redis的安装
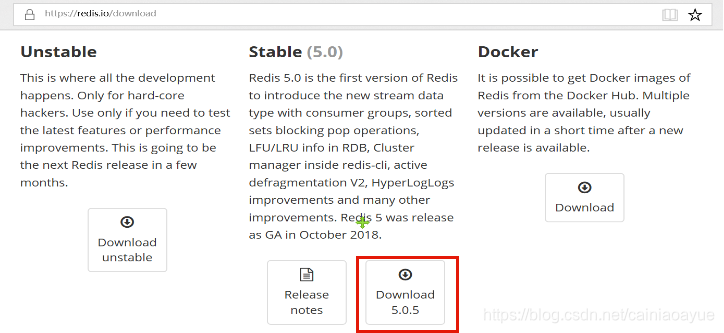
-
首先上官网下载Redis 压缩包,地址
http://redis.io/download
- 压缩包执行解压操作并进行编译
tar xzf redis-x.x.x.tar.gz
cd redis-x.x.x/
make && make install
2.Redis的部署
-
执行Redis-server 命令,启动Redis 服务
./redis-server -
客户端redisClient
redis-cli # 登录redis
> set ‘a’ ‘123’ -
当添加键值后,发现在当前运行的目录下,创建了一个文件:dump.rdb,这个文件用于将数据持久化存储
三.Redis架构模式
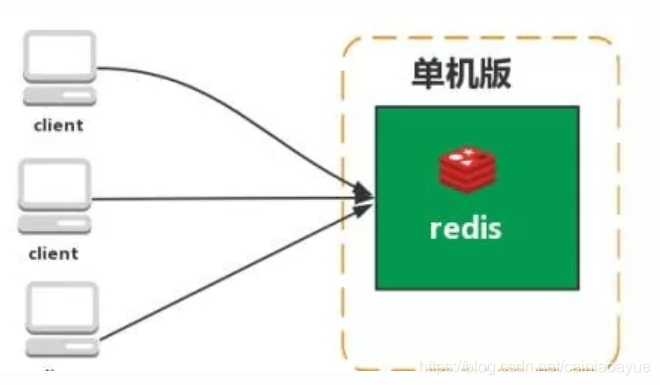
1.单机版
- 特点:简单
-
问题:内存容量有限、处理能力有限 、无法高可用。
2.主从复制
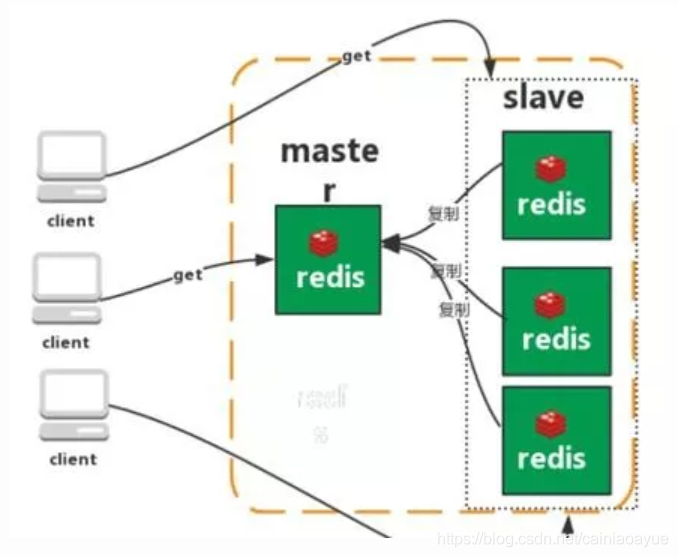
Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为
主服务器(master)
,而通过复制创建出来的服务器复制品则为
从服务器(slave)
。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步给从服务器,从而一直保证
主从服务器的数据相同。
-
主从复制的特点
:
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交从库 -
主从复制的问题
:
1.无法保证高可用
2.没有解决 master 写的压力
四.Python与Redis
- 引入模块
import redis
- 连接
try:
r = redis.StrctRedis(host="localhost", port=6379)
except Exception, e:
print e.message
- 方式一:根据数据类型的不同,调用相应的方法,完成读写
r.set("name", "hello")
r.get("name")
- 方式二:pipline
- 缓冲多条命令,然后一次性执行,减少服务器-客户端之间TCP数据包,从而提高效率
pipe = r.pipeline()
pipe.set("name", "world")
pipe.get("name")
pipe.execute()
-
封装:连接redis服务器部分是一致的,将string类型的读写进行封装
