文章目录
-
一、Spark内核概述
-
二、Spark通信架构概述
-
三、Spark部署模式
-
********************
-
任务调度机制,job任务提交,Spark Shuffle解析,内存管理 见下篇
一、Spark内核概述
Spark内核泛指Spark的核心运行机制,包括Spark核心组件的运行机制、Spark任务调度机制、Spark内存管理机制、Spark核心功能的运行原理等,熟练掌握Spark内核原理,能够帮助我们更好地完成Spark代码设计,并能够帮助我们准确锁定项目运行过程中出现的问题的症结所在。
1.1 Spark核心组件回顾
1.1.1 Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责:
-
将用户程序转化为作业(Job);
-
在Executor之间调度任务(Task);
-
跟踪Executor的执行情况;
-
通过UI展示查询运行情况;
1.1.2 Executor
Spark Executor节点是负责在Spark作业中运行具体任务,任务彼此之间相互独立。Spark 应用启动时,Executor节点被同时启动,并且始终伴随着整个Spark应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。
Executor有两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器(Driver)
这是driver为什么能够监控executor执行情况
- 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
1.2 Spark通用运行流程概述
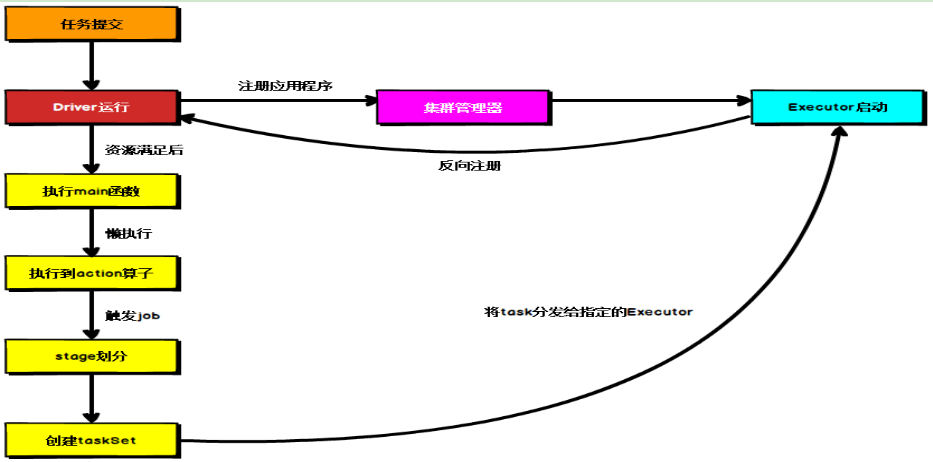
上图为Spark通用运行流程图,体现了基本的Spark应用程序在部署中的基本提交流程。
这个流程是按照如下的核心步骤进行工作的:
-
任务提交后,都会先启动Driver程序;
-
随后Driver向集群管理器注册应用程序;
-
之后集群管理器根据此任务的配置文件分配Executor并启动;
-
Driver开始执行main函数,Spark查询为懒执行,当执行到Action算子时开始反向推算,根据宽依赖进行Stage的划分,随后每一个Stage对应一个Taskset,Taskset中有多个Task,查找可用资源Executor进行调度;
-
根据本地化原则,Task会被分发到指定的Executor去执行,在任务执行的过程中,Executor也会不断与Driver进行通信,报告任务运行情况。
二、Spark通信架构概述
2.1 Spark中通信框架的发展:
Ø Spark早期版本中采用Akka作为内部通信部件。
Ø Spark1.3中引入Netty通信框架,为了解决Shuffle的大数据传输问题使用
Ø Spark1.6中Akka和Netty可以配置使用。Netty完全实现了Akka在Spark中的功能。
Ø Spark2系列中,Spark抛弃Akka,使用Netty。
Spark2.x版本使用Netty通讯框架作为内部通讯组件。Spark 基于Netty新的RPC框架借鉴了Akka的中的设计,它是基于Actor模型,如下图所示:
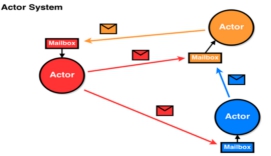
Spark通讯框架中各个组件(Client/Master/Worker)可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下:
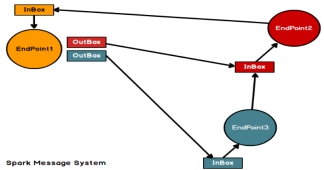
Endpoint(Client/Master/Worker)有1个InBox和N个OutBox(N>=1,N取决于当前Endpoint与多少其他的Endpoint进行通信,一个与其通讯的其他Endpoint对应一个OutBox),Endpoint接收到的消息被写入InBox,发送出去的消息写入OutBox并被发送到其他Endpoint的InBox中。
每个Endpoint对应一个Inbox,和多个Outbox,具体有几个Outbox,取决于当前Endpoint与多少其它的Endpoint进行通信,一个与其通信的Enpoint对应一个Outbox
Endpoint接收到的消息被写入InBox,发哦送出去的消息写入OutBox冰杯发送到其它Endpoint的InBox中
Spark通信终端
Driver:
class DriverEndpoint extends ThreadSafeRpcEndpoint
Executor
class CoarseGrainedExecutorBackend extends ThreadSafeRpcEndpoint
一些需要知道的事:
1. http,https,RPC是一种协议的类型
2. AKKA: IO(阻塞式IO)通信
3. Netty: NIO(非阻塞式IO)通信
4. 在大数据领域,在分布式系统之间,频繁发送请求,传输数据,NIO效率高!
2.2 Spark通讯架构解析
Spark通信架构如下图所示:
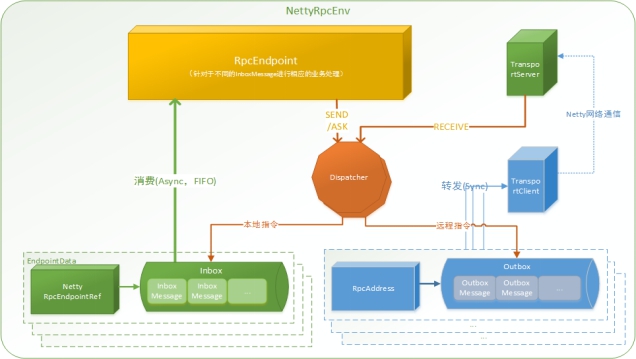
RpcEnv:
是RPC通信环境
RPC上下文环境,每个RPC终端运行时依赖的上下文环境称为RpcEnv;在把当前Spark版本中使用的NettyRpcEnv
|—->
RpcEndpoint:
①Rpc通信端点,必须加入到RpcEnv才能通信!
②本地RpcEndpoint对应一个Inbox,
③几个目标RpcEndpoint对应几个OutBox
④ 一个RpcEndpoint对应一个TransportServer
Spark把每个节点(Client,Master,Worker)都成称之为一个RPC终端,且都实现RpcEndpoint接口;
并且会根据不同端点的需求,设计不同的消息和不同的业务处理,
如果需要发送,或者询问一些消息,则需要调用Dispatcher
在Spark中所有的终端都存在生命周期
RPC通信终端。Spark针对每个节点(Client/Master/Worker)都称之为一个RPC终端,且都实现RpcEndpoint接口,内部根据不同端点的需求,设计不同的消 息和不同的业务处理,如果需要发送(询问)则调用Dispatcher。在Spark中,所有的终端都存在生命周期:以下四种周期
-
Constructor
-
onStart :每个RpcEndpoint在加入到NettyRPcEnv之后,都需要进行初始化
-
receive*
-
onStop
RpcEndpointRef:
类比为手机号或邮箱地址!
RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用, 然后通过该引用发送消息。
RpcAddress:
表示远程的RpcEndpointRef的地址,Host + Port。
Dispatcher:
消息调度(分发)器,针对于RPC终端需要发送远程消息或者从远程RPC接收到的消息,分发至对应的指令收件箱(发件箱)。如果指令接收方是自己则存入收件箱,如果指令接收方不是自己,则放入发件箱;
InBox:
指令消息收件箱。一个本地RpcEndpoint对应一个收件箱,Dispatcher在每次向Inbox存入消息时,都将对应EndpointData加入内部ReceiverQueue中,另外Dispatcher创建时会启动一个单独线程进行轮询ReceiverQueue,进行收件箱消息消费;
OutBox:
一个OutBox对应一个TransportClient
指令消息发件箱。对于当前RpcEndpoint来说,一个目标RpcEndpoint对应一个发件箱,如果向多个目标RpcEndpoint发送信息,则有多个OutBox。当消息放入Outbox后,紧接着通过TransportClient将消息发送出去。消息放入发件箱以及发送过程是在同一个线程中进行;
<—-|
TransportClient:
Netty通信客户端,一个OutBox对应一个TransportClient,TransportClient不断轮询OutBox,根据OutBox消息的receiver信息,请求对应的远程TransportServer;
TransportServer:
Netty通信服务端,一个RpcEndpoint对应一个TransportServer,接受远程消息后调用Dispatcher分发消息至对应收发件箱;
2.3 IO模型
2.3.1 概念
IO模型指用什么样的方式进行数据的发送和接收!模型决定了程序通信的性能。
2.3.2 java支持的3种IO模型
三种IO模型的区别在于通道数量的多少,单通道还是多通道,阻塞还是非阻塞
BIO:
同步并阻塞(传统阻塞型),服务器实现模式为:一个连接一个线程,即客户端有连接请求时,服务器就需要启动一个线程处理,如何这个连接不做任何事情,会造成不必要的线程开销,,jdk1.4之前的唯一选择
NIO:
同步非阻塞,服务器实现模式为:一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器(Seletor)轮循到连接有I/O请求就进行处理,JDK1.4引入。
AIO(NIO2):
异步非阻塞:AIO引入异步通道的概念,采用了Proactor模式,简化了程序编写,有效的请求才能启动线程,他的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。AIO还没有得到广泛的使用!JDK1.7支持
2.4 常见API
2.4.1 NettyRpcEnv
//分发处理消息 定义一个dispatcher用于分发处理消息
private val dispatcher:Dispatcher = new Dispatcher(this ,numUsableCores)
//网络传输通信的服务端
private var server :TransportServer
//当前环境中发向每个远程设备的发件箱
//RpcAddress(远程设备):就是远程的RpcEndpointRef地址
//RpcEndpointRef:就是远程的RpcEndpoint的引用,当我们想远程的RpcEndpoint发送消息时,先拿到远程RpcEndpoint的这个引用,通过该引用发送消息
private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]()
/*
调用dispatcher.regist()
为每个EndPoint创建一个Inbox,在Inbox中放入onStart()
*/
rpcEnv.setupEndpoint
2.4.2 Dispathcer
//分发消息:
private[netty] class Dispatcher(nettyEnv:NettyRpcEnv,numUsableCore:Int) extends Logging {
//每个设备 及其 MessageLop
private val endPoints:ConcurrentMap[String,MessageLoop] =
new ConcurrentHashMap[String,MessageLopp]
private val shutdownLatch = new CountDownLatch(1)
//处理所有的非独立设备
private lazy val shareLoop = new SharedMessageLoop(neetyEnv.conf,this, numUsableCore)
}
2.4.3 SharedMessageLoop
作用:将消息交给Dispatcher处理分发!
//记录的是每个Endpoint和对应的收件箱
private val endpoint = new ConcurrentHashMap [String, Inbox]()
//线程池创建若干线程,自动从Index到队列中,取出每一个Index,在从Index中取消息,根据消息类型进行对应处理
protected val threadpool:ThreadPoolExecutor
2.4.4 Inbox
//收件箱
一个EdPoint对应一个收件箱,只要收件箱被创建,此时就想放入一个ontart消息!
2.5 Master
onstart
//以固定的频率调度
public ScheduledFuture<?> scheduleAtFixedRate(Runable command , //线程
long initiaDelay , //初始化延迟(第一次等N秒后,再运行线程) 默认0
long period , //固定的周期,从配置中读取spark.worker.timeout,默认60
TimeUnit unit //时间单位 MILLISECONDS
)
master启动之后,如果没有提交job,就每60s将超时的worker进行处理!
三、Spark部署模式
3.1 YARN模式运行机制
3.2 YARN Cluster模式
3.2.1 YARN Cluster概述
-
执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
-
SparkSubmit类中的main方法反射调用YarnClusterApplication的main方法;
-
YarnClusterApplication创建Yarn客户端,然后向Yarn发送执行指令:bin/java ApplicationMaster;
-
Yarn框架收到指令后会在指定的NM中启动ApplicationMaster;
-
ApplicationMaster启动Driver线程,执行用户的作业;
-
AM向RM注册,申请资源;
-
获取资源后AM向NM发送指令:bin/java CoarseGrainedExecutorBackend;
-
CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
-
Driver分配任务并监控任务的执行。
注意:SparkSubmit、ApplicationMaster和CoarseGrainedExecutorBackend是独立的进程;Driver是独立的线程;Executor和YarnClusterApplication是对象。
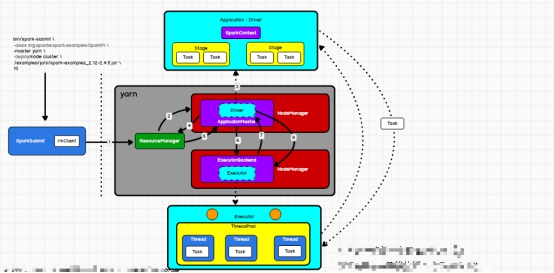
bin/spark-submit
--class prg.apache.spark.examples.SparkPi
--master yarn
--deploy-mode cluster
/example/jars/spark-examples.jar
10
以上脚本会启动一个类,sparksubmit类,启动一个进程,这个进程就用来跑我们的任务,跑一个rm客户端;
submit启动之后会去连接rm,向rm提交一个指令,告诉rm去启动一个am,rm收到指令之后,会找一台nm启动一个进程叫am,am有时候也叫driver进程,但源码真正的driver是一个线程;【只有进程才有进程,核心】
am启动成功之后,会启动一个子线程,叫driver线程,driver线程启动之后,会执行用户类的main函数,创建SparkContext,开始作DAG,碰见行动算子后,会划分stage,提交任务,提交任务之前要保证Executor进程启动好
Driver启动之后,并不会等你所有的代码执行完之后才启动Executor,Driver是一个子线程
Am启动之后,有两个事情,一个事情是在子线程启动Driver,另一个事情是在主线程启动Executor,根据rm返回的信息,启动Executor
怎么启动Executor?
am找rm申请资源,rm收到申请之后,会给am分配容器,容器里面主要封装了一些资源,cpu内核和内存,am收到容器之后,会在每一个容器启动一个executor进程,这个进程的名字叫做ExecutorBackend,进程启动成功之后,会找driver注册自己(反注册),注册成功之后,会出创建一个对象,叫Executor对象,这个对象里面有一个run方法,方法会执行我们具体的任务,每个任务对应一个线程
# Am一般是Driver进程,Driver其实是Am的一个子线程,Am的主线程是去启动Executor
# 先去Rm申请资源,Am个它分配一些容器。Am收到容器后,会在每个容器启动一个进程,进程启动成功之后,会去找Driver注册,注册自己,收到Driver发送的注册成功消息之后,会启动一个Executor,Executor是一个对象,有run方法等,对象里面可以执行任务,每个任务对应一个线程
3.2.2 YARN Cluster源码
bin/spark-submit --master yarn
--deploy-mode cluster
--class com.atguigu.spark.day01.WordCount1
/opt/module/spark-standalone/bin/spark-1.0-SNAPSHOT.jar hdfs://hadoop102:9820/input
bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
在项目中添加依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
跑submit之前javahome是必配的
①SparkSubmit
精细版:
bin/spark-submit #这里不能用spark-shell,spark-shell
--class prg.apache.spark.examples.SparkPi
--master yarn
--deploy-mode cluster
/example/jars/spark-examples.jar
10
- 先看sparksubmit的脚本
if [ -z "${SPARK_HOME}" ]; then #判断当前环境是否是否配了SPARK_HOME环境
source "$(dirname "$0")"/find-spark-home
fi
# disable randomized hash for string in Python 3.3+
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@" #将以上shell指令传递的参数都传给spark-class脚本
- 看spark-class脚本
CMD=("${CMD[@]:0:$LAST}") #这句好好看
exec "${CMD[@]}"
#这个参数的内容是: ${CMD[@]}
/opt/module/jdk1.8.0_144/bin/java
#将spark-yarn的环境,jar包,hadoop环境都加载进来了
-cp /opt/module/spark-yarn/conf/: /opt/module/spark-yarn/jars/*: /opt/module/hadoop-3.1.3/etc/hadoop/
#启动这个程序就相当于启动这个类
org.apache.spark.deploy.SparkSubmit
#以下是传给这个类的参数,args
--master yarn
--deploy-mode cluster
--class org.apache.spark.examples.SparkPi ./examples/jars/spark-examples_2.12-3.0.0.jar
10
- 看主类org.apache.spark.deploy.SparkSubmit
org.apache.spark.deploy.SparkSubmit
--main
--val submit = new SparkSubmit(){...} //这里new了一个sparksubmit匿名子类的对象(匿名内部类)
--submit.doSubmit(args) //执行dosubmit方法
--super.doSubmit(args) //dosubmit方法就是执行它父类的doSubmit()方法
--val appArgs = parseArguments(args) //解析spark-submit后面传递的各种参数,把传递的参数做封装
--appArgs.action match
case SparkSubmitAction.SUBMIT
=> submit(appArgs, uninitLog)
// 除非特别指定, action 就应该是 SUBMIT
action = Option(action).getOrElse(SUBMIT)
-- doRunMain()
--runMain(args, uninitLog) // 使用提交的参数,运行child class中的main 方法
--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
--var childMainClass = "" // 需要重点关注
--childMainClass = YARN_CLUSTER_SUBMIT_CLASS
// 如果是client模式,此时 childMainClass=args.mainClass
// 如果是cluster模式,此时 childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication(对用户定义的类的包装)
--var mainClass: Class[_] = null
//加载childMainClass
--mainClass = Utils.classForName(childMainClass)
// 判断SparkApplication是否为mainClass或者是 mainClass 的父类
// 在 yarn-cluster 模式下:
// mainClass = org.apache.spark.deploy.yarn.YarnClusterApplication
--val app: SparkApplication=
//通过反射的放射得到他的无参构造器,new一个实例,看这个实例对象mainClass是不是SparkApplication,显然是;
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
// 启动 SparkApplication
--app.start(childArgs.toArray, sparkConf)
//在Yarn\CLient.scala文件下这个类YarnClusterApplication继承SparkApplication
-- new Client(new ClientArguments(args), conf, null).run() //YarnClusterApplication.start run(): 向RM提交一个appliction,提交应用
// 向RM申请资源,运行AM进程
--this.appId = submitApplication()
//以下是submitApplication()方法的方法体
--> 【
--launcherBackend.connect()
// 运行了YarnClient的init()和start()
--yarnClient.init(hadoopConf) // 初始化 Yarn 客户端
// 关键代码: 创建YarnClient 对象, 用于连接 ResourceManager
private val yarnClient = YarnClient.createYarnClient
--yarnClient.start()
// 向RM申请应用
--val newApp = yarnClient.createApplication()
//获取RM的响应
--val newAppResponse = newApp.getNewApplicationResponse()
//从响应中获取RM生成的应用ID
--appId = newAppResponse.getApplicationId()
// 生成Job的临时作业目录
--val appStagingBaseDir
// 确保YARN有足够的资源运行AM
-- verifyClusterResources(newAppResponse)
// 开始安装 AM 运行的上下文
// Container中要运行的AM的进程的上下文 ,确定Container中进程的启动命令是什么
//核心代码:
--val containerContext = createContainerLaunchContext(newAppResponse)
// java 虚拟机一些启动参数 amMemory 默认1g
javaOpts += "-Xmx" + amMemory + "m"
// 确定 AM 类
// Cluster 模式:amClass=org.apache.spark.deploy.yarn.ApplicationMaster
// Client 模式: amClass=org.apache.spark.deploy.yarn.ExecutorLaunche
--val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
//得到这个类之后怎么执行的呢?
// 指令参数:
--val amArgs
// 封装指令
val commands
//createContainerLaunchContext()方法返回一个容器,里面封装了指令
amContainer
【注意:】"提交指令之后,rm会执行org.apache.spark.deploy.yarn.ApplicationMaster这个类"
// AM进程运行后读取Spark应用的上下文
--val appContext = createApplicationSubmissionContext(newApp, containerContext)
// 核心代码: 提交应用 ->
// 向RM申请运行AM,真正的提交
-- yarnClient.submitApplication(appContext)
//最后返回appId
<--】
精简版:
org.apache.spark.deploy.SparkSubmit
-- doSubmit
submit(appArgs, uninitLog)
-- submit
doRunMain()
-- doRunMain
runMain(args, uninitLog)
-- runMain
val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
-- prepareSubmitEnvironment
childMainClass = YARN_CLUSTER_SUBMIT_CLASS
childMainClass = org.apache.spark.deploy.yarn.YarnClusterApplication
val app: SparkApplication =
// cluster 模式下
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
app.start(childArgs.toArray, sparkConf)
org.apache.spark.deploy.yarn.YarnClusterApplication
-- submitApplication
val containerContext = createContainerLaunchContext(newAppResponse)
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
yarnClient.submitApplication(appContext)
SparkSubmit总结:
1.通过脚本启动SparkSubmit进程
2.反射出来YarnClusterApplication
3.给RM提交应用 Application
②ApplicationMaster
精细版:
org.apache.spark.deploy.yarn.ApplicationMaster
--main
// 获取AM需要的参数,对参数进行封装
--val amArgs = new ApplicationMasterArguments(args)
--val sparkConf = new SparkConf()
// 创建 ApplicationMaster 对象
--master = new ApplicationMaster(amArgs, sparkConf, yarnConf)
--ugi.doAs
// 执行AM 对象的 run 方法 ->
override def run(): Unit = System.exit(master.run())
final def run(): Int = ...
//如果是cluster模式: runDriver()
//如果是client模式: runExecutorLauncher()
-- runDriver() //运行Driver
//两件事情
"--->1.执行用户类(子线程中)"
// 启动应用程序 -> 启动一个线程,返回一个线程id
--userClassThread = startUserApplication()
// 加载用户定义的类, 并获取用户类的 main 方法
--val mainMethod = userClassLoader.loadClass(args.userClass).getMethod("main",classOf[Array[String]])
// 在一个子线程中执行用户类的 main 方法
--val userThread = new Thread(){
run(
// 运行用户定义的Driver类的main方法
//userArgs就是最后传的那个10
mainMethod.invoke(null, userArgs.toArray)
)
}
//给线程取一个名字叫Driver
-- userThread.setName("Driver")
//启动Driver线程,启动后,创建SparkContext,提交Job
--userThread.start()
//然后把userThread返回
"--->2.向rm注册Am,申请资源(容器)"
//等待sc的初始化
//在AM的主线程中,等待Driver线程创建 SparkContext,获取SparkContext
--val sc = ThreadUtils.awaitResult
// 从SparkContext的SparkEnv属性中,获取RpcEnv
-- val rpcEnv = sc.env.rpcEnv
//向RM注册 AM
-- registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
// 创建 YarnRMClient 对象, 用于同 RM 通讯
--val client = new YarnRMClient()
//注册成功之后,rm分配些资源
-- client.register(host, port, yarnConf, _sparkConf, uiAddress, historyAddress)
//获取Driver的 EndpointRef
//这个地址将来要让executor知道
--val driverRef = rpcEnv.setupEndpointRef
// allocator:YarnAllocator 负责申请资源,在申请到Containers 后决定拿Container干什么
--createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
--allocator = client.createAllocator
// 创建并注册 AMEndpoint
--rpcEnv.setupEndpoint("YarnAM", new AMEndpoint(rpcEnv, driverRef))
// 向RM发请求,申请Containers
//分配资源
--allocator.allocateResources()
//尝试申请可分配的资源,得到所有资源列表
--val allocatedContainers = allocateResponse.getAllocatedContainers()
--if (allocatedContainers.size > 0){
// 决定用Container干什么事情
//处理分配到的资源
--handleAllocatedContainers(allocatedContainers.asScala)
// 运行匹配后的资源
--runAllocatedContainers(containersToUse)
//对于每个Container,每个容器启动一个Executor
--for (container <- containersToUse){
if (launchContainers) {
launcherPool.execute(() => {
try {
new ExecutorRunnable().run()
//run函数里
//创建和NM通信的客户端
--nmClient = NMClient.createNMClient()
//初始化NodeManager客户端
--nmClient.init(conf)
//启动NodeManager 客户端
--nmClient.start()
// 正式启动NM上的Container
--startContainer()
【注意:】"org.apache.spark.executor.YarnCoarseGrainedExecutorBackend Container中启动的进程"
//准备在Container上运行的Java命令
--val commands = prepareCommand()
}
}
精简版:
org.apache.spark.deploy.yarn.ApplicationMaster
-- run
if (isClusterMode) { //集群模式
// ->
runDriver()
} else { // client 模式
runExecutorLauncher()
}
-- runDriver
两件事情:
1. 执行用户类(子线程中)
startUserApplication
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]])
mainMethod.invoke(null, userArgs.toArray)
2. 向rm注册Am, 申请资源(容器)
registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId)
createAllocator
-- allocator.allocateResources()
-- handleAllocatedContainers(allocatedContainers.asScala)
runAllocatedContainers(containersToUse)
-- ExecutorRunnable.run
startContainer()
-- prepareCommand()
org.apache.spark.executor.YarnCoarseGrainedExecutorBackend
ApplicationMaster总结:
1. 启动driver线程(运行用户类的main函数)
初始化sc
2. sc初始化成功之后,
am向rm注册am, 申请资源, 获取容器, 在能用的容器中启动 Executor进程
向NM提交指令
bin/java org.apache.spark.executor.YarnCoarseGrainedExecutorBackend ...
③YarnCoarseGrainedExecutorBackend
精细版:
org.apache.spark.executor.YarnCoarseGrainedExecutorBackend
--main
|--CoarseGrainedExecutorBackend=new YarnCoarseGrainedExecutorBackend
--YarnCoarseGrainedExecutorBackend extends CoarseGrainedExecutorBackend()
--CoarseGrainedExecutorBackend extends IsolatedRpcEndpoint
--override def onStart()
|--rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap{
ref =>
driver = Some(ref) // 拿到 driver 的引用
// 向 driver 注册当前的 Executor 向driver发送信息
//ask(必须回复) send(只发送, 不要求对方回复)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls,extractAttributes, _resources, resourceProfile.id))
-
Driver端 :
-
"Driver端,driver是怎么接收信息的?-----------------------------------------------------------------------" //new sparkContext SparkContext类: // Create and start the scheduler --val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode) _schedulerBackend = sched _taskScheduler = ts _dagScheduler = new DAGScheduler(this) _heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet) --_taskScheduler.start() // TaskSchedulerImpl类的start方法 backend.start() //YarnClusterSchedulerBackend类的start方法 bindToYarn(attemptId.getApplicationId(), Some(attemptId)) super.start() //在父类的中有一个构造器,在new构造器的时候已经将driverEndpiont创建出来了 val driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint()) //创建sparkcontext的时候会创建DriverEndpoint --def createDriverEndpoint(): DriverEndpoint = new DriverEndpoint() --class DriverEndpoint extends IsolatedRpcEndpoint //send的时候这个方法里的东西会执行 --override def receive //ask的时候这个方法里的东西会执行到 --override def receiveAndReply //receiveAndReply其实是一个函数,偏函数,用{}括起来的一堆case语句 --case RegisterExecutor(executorId, executorRef, hostname, cores, logUrls,attributes, resources, resourceProfileId) => if (executorDataMap.contains(executorId)) { context.sendFailure(new IllegalStateException(s"Duplicate executor ID: $executorId")) } //黑名单 else if (scheduler.nodeBlacklist.contains(hostname)||isBlacklisted(executorId, hostname)){ logInfo(s"Rejecting $executorId as it has been blacklisted.") context.sendFailure(new IllegalStateException(s"Executor is blacklisted: $executorId")) } else{ val executorAddress = if (executorRef.address != null) { executorRef.address } else { context.senderAddress } } // 给 Executor 返回true, 便是成功 context.reply(true)
①|--case Success(_) =>
// Executor 注册成功之后, 给自己发送一个 RegisteredExecutor
self.send(RegisteredExecutor)
}
-
Executor端:
-
//Executor注册成功之后 case RegisteredExecutor => logInfo("Successfully registered with driver") try { // 创建 Executor 对象(计算对象) executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false,resources = _resources) // 告诉 driver 这个 Executor 已经启动成功 driver.get.send(LaunchedExecutor(executorId)) } catch { case NonFatal(e) => exitExecutor(1, "Unable to create executor due to " + e.getMessage, e) }-
Driver端
-
"driver接收到executor对象创建成的消息后:--------------------------------------------------------------------------" // 收到 Executor 对象创建成功的信息 case LaunchedExecutor(executorId) => executorDataMap.get(executorId).foreach { data => data.freeCores = data.totalCores } // 给该 Executor 发 offer makeOffers(executorId)
-
②|--case Failure(e) =>exitExecutor(1, s"Cannot register with driver: $driverUrl",e,notifyDriver = false)
|--CoarseGrainedExecutorBackend.run(backendArgs, createFn)
--backendCreateFn => CoarseGrainedExecutorBackend
--SparkHadoopUtil.get.runAsSparkUser () =>
|--val executorConf = new SparkConf
|--val fetcher = RpcEnv.create //创建通信环境
|--var driver: RpcEndpointRef = null
// 获取Driver的EndpointRef
// DriverEndpointRef 通过此 ref 可以向 driver 发送信息
--driver = fetcher.setupEndpointRefByURI(arguments.driverUrl)
//向Driver发请求,请求SparkApp的配置
|--val cfg = driver.askSync[SparkAppConfig] (RetrieveSparkAppConfig(arguments.resourceProfileId))
|--fetcher.shutdown()
// 基于从Driver获取的SparkApp的配置,重新创建一个通信环境
①--val env = SparkEnv.createExecutorEnv(driverConf, arguments.executorId, arguments.bindAddress,arguments.hostname, arguments.cores, cfg.ioEncryptionKey, isLocal = false)
// 向新创建的环境中,
//注册一个通信端点 Executor => CoarseGrainedExecutorBackend(RpcEndPoint)
//之后,CoarseGrainedExecutorBackend需要运行onStart()
②--env.rpcEnv.setupEndpoint("Executor",
backendCreateFn(env.rpcEnv, arguments, env, cfg.resourceProfile))
//【env环境创建好了,再在backendCreateFn这创建一个endpoint,把endpoint放到环境里面去】
// 阻塞当前YarnCoarseGrainedExecutorBackend的线程,知道应用结束
③--env.rpcEnv.awaitTermination()
-
Driver端
-
--try { val scheduler = cm.createTaskScheduler(sc, masterUrl) override def createTaskScheduler(sc: SparkContext, masterURL: String): TaskScheduler= { sc.deployMode match { case "cluster" => new YarnClusterScheduler(sc) case "client" => new YarnScheduler(sc) case _ => throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn") } } override def createSchedulerBackend(sc: SparkContext,masterURL: String,scheduler:TaskScheduler): SchedulerBackend = { sc.deployMode match { case "cluster" => new YarnClusterSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc) case "client" => new YarnClientSchedulerBackend(scheduler.asInstanceOf[TaskSchedulerImpl], sc) case _ => throw new SparkException(s"Unknown deploy mode '${sc.deployMode}' for Yarn") } } val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler) cm.initialize(scheduler, backend) (backend, scheduler)
精简版:
//创建了一个对象: endPoint
new YarnCoarseGrainedExecutorBackend(rpcEnv, arguments.driverUrl, arguments.executorId,
arguments.bindAddress, arguments.hostname, arguments.cores, arguments.userClassPath, env,
arguments.resourcesFileOpt, resourceProfile)
构造器, onStart, receive*, onStop
//向driver发送信息: ask(必须回复) send(只发送, 不要求对方回复)
ref.ask[Boolean](RegisterExecutor(executorId, self, hostname, cores, extractLogUrls,
extractAttributes, _resources, resourceProfile.id))
//接到成功的信息之后:
self.send(RegisteredExecutor)
//Driver端的endPoint
new SparkContext
YarnClusterScheduler
YarnClusterSchedulerBackend
val driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint())
注册成功, 会给execute端发送成功信息
_taskScheduler.start()
backend.start()
bindToYarn(attemptId.getApplicationId(), Some(attemptId))
向 driver 注册当前的 Executor, 向driver发送信息,Driver是如何接收消息的,以及Executor端创建Executor成功之后又是如何给Driver发送消息,简化版解析)
1.CoarseGrainedExecutorBackend.onStart()
--onStart()
--driver = Some(ref) // 获取Driver的EndpointRef
--ref.ask[Boolean](RegisterExecutor) // 向Driver 发RegisterExecutor消息,要求Driver回复Boolean型的消息
--case Success(_) => self.send(RegisteredExecutor) //收到true,自己给自己发送一个RegisteredExecutor消息
--case Failure(e) => exitExecutor // 退出Executor
--receive
-- case RegisteredExecutor =>
--logInfo("Successfully registered with driver")
// Executor: 计算者,负责运行Task
-- executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false, resources = _resources)
//executor这个计算对象启动之后会i、向driver发send消息
--driver.get.send(LaunchedExecutor(executorId)) //给Driver发信息LaunchedExecutor(executorId)
2.SparkContext (Driver构造)
核心属性: var _env: SparkEnv : 封装了Spark所有的环境信息
_env = createSparkEnv(_conf, isLocal, listenerBus)
var _taskScheduler: TaskScheduler //任务调度器
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode) //528行
--case masterUrl =>
--val scheduler = cm.createTaskScheduler(sc, masterUrl) // YARN Cluster模式
-- val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler) //YarnClusterSchedulerBackend
--YarnClusterSchedulerBackend 父类 YarnSchedulerBackend 的构造器中
-- 爷爷类 CoarseGrainedSchedulerBackend 的构造器
// 名称: CoarseGrainedScheduler 端点类型: DriverEndpoint
--属性 val driverEndpoint = rpcEnv.setupEndpoint(ENDPOINT_NAME, createDriverEndpoint())
--cm.initialize(scheduler, backend)
-- (backend, scheduler)
private var _dagScheduler: DAGScheduler //将RDD根据依赖划分阶段
3.Driver如何处理RegisterExecutor消息 , Driver使用 DriverEndpoint作为通信端点
//Driver的EndPoint设备:
sc.env.rpcEnv: SparkContext
DriverEndpoint
--onStart
--receive
-- case LaunchedExecutor(executorId) =>
--executorDataMap.get(executorId).foreach { data =>
data.freeCores = data.totalCores
}
--makeOffers(executorId) //发offer, 成为工作团队的一员,准备接活
--receiveAndReply
--case RegisterExecutor
//如果当前executorId 已经存在在 记录的注册的executor的Map中,
--if (executorDataMap.contains(executorId)) context.sendFailure // 回复false
// 如果executorId在黑名单中,回复false
--else if (scheduler.nodeBlacklist.contains(hostname) || isBlacklisted(executorId, hostname)) context.sendFailure
//否则
--val data = new ExecutorData //记录Executor信息
-- executorDataMap.put(executorId, data)
-- context.reply(true) //回复true
3.2.3 YARN Cluter模式总结:
1.首先:通过sparksubmit脚本提交,启动一个sparksubmit进程,启动成功之后会封装一个指令,这个指令会启动一个AM;
--问:那么AM是怎么启动的?这个指令又是怎么封装的呢?
--答:在SparkSubmit里会反射一个类,反射的类叫YARNClusterApplication,这个类里面会把怎么启动的指令交给RM(ResourceManager)RM收到指令之后会找一台NodeManager启动一个AM(ApplicationMaster)
2.AM启动之后会做两件事情:
(1)运行一个Driver;
(2)向ResourceManager注册自己,注册成功之后,RM会给AM返回一些容器(资源);
3.AM有了这些容器(资源)之后会启动它们,启动这些容器就是在这些容器里面启动Exector进程,启动Executor进程是交给NM(NodeMAnager)的
4.Executor启动成功之后,会向Driver注册自己,注册成功之后,Driver会向Executor发送注册成功的信息,Executor进程收到成功的信息之后,会创建一个Executor对 象,new 了一个Executor对象,对象里面会有一些CPU啊,线程池啊之类的,后面会涉及到任务的调度;
3.3 YARN Client模式
3.3.1 YARN Client模式概述
-
执行脚本提交任务,实际是启动一个SparkSubmit的JVM进程;
-
SparkSubmit类中的main方法反射调用用户代码的main方法;
-
启动Driver线程,执行用户的作业,并创建ScheduleBackend;
-
YarnClientSchedulerBackend向RM发送指令:bin/java ExecutorLauncher;
-
Yarn框架收到指令后会在指定的NM中启动ExecutorLauncher(实际上还是调用ApplicationMaster的main方法);
object ExecutorLauncher {
def main(args: Array[String]): Unit = {
ApplicationMaster.main(args)
}
}
-
AM向RM注册,申请资源;
-
获取资源后AM向NM发送指令:
bin/java CoarseGrainedExecutorBackend;
-
CoarseGrainedExecutorBackend进程会接收消息,跟Driver通信,注册已经启动的Executor;然后启动计算对象Executor等待接收任务
-
Driver分配任务并监控任务的执行。
注意:SparkSubmit、ExecutorLauncher【ApplicationMaster】和CoarseGrainedExecutorBackend是独立的进程;Executor和Driver是对象。
3.3.2 YARN Client模式源码
bin/spark-submit --master yarn
--deploy-mode client
--class com.atguigu.spark.day01.WordCount1
/opt/module/spark-standalone/bin/spark-1.0-SNAPSHOT.jar hdfs://hadoop102:9820/input
bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
在项目中添加依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.12</artifactId>
<version>3.0.0</version>
</dependency>
① 运行Driver
org.apache.spark.deploy.SparkSubmit
--main
--val submit = new SparkSubmit()
--submit.doSubmit(args)
--super.doSubmit(args)
--val appArgs = parseArguments(args) //解析spark-submit后面传递的各种参数
--appArgs.action match SparkSubmitAction.SUBMIT
=> submit(appArgs, uninitLog)
-- doRunMain()
--runMain(args, uninitLog) // 使用提交的参数,运行child class中的main 方法
// 如果是client模式,此时 childMainClass=args.mainClass WordCount1
// 如果是cluster模式,此时 childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication(对用户定义的类的包装)
--val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)
--var mainClass: Class[_] = null
--mainClass = Utils.classForName(childMainClass) // mainClass=org.apache.spark.deploy.yarn.YarnClusterApplication
--val app=new JavaMainApplication(mainClass)
--app.start(childArgs.toArray, sparkConf)
---- val mainMethod = klass.getMethod("main", new Array[String](0).getClass)
--mainMethod.invoke(null, args) //WordCount1.main 在Driver的main中就初始化了SparkContext
② 在Driver上初始化SparkContext
_taskScheduler.start()
-- backend.start() // YarnClientSchedulerBackend.start() 启动任务调度的后台
--super.start() // super: CoarseGrainedSchedulerBackend
--client = new Client(args, conf, sc.env.rpcEnv)
--bindToYarn(client.submitApplication(), None) // 向YARN上提交应用
--launcherBackend.connect()
--yarnClient.init(hadoopConf)
--yarnClient.start() // YarnClient是和YARN(RM)通信的客户端
--val newApp = yarnClient.createApplication()
--appId = newAppResponse.getApplicationId() //获取应用ID
--stagingDirPath = new Path(appStagingBaseDir, getAppStagingDir(appId)) //获取作业的临时存储目录
--verifyClusterResources(newAppResponse) //确保集群有足够的资源运行AM,如果没有就抛异常
//cluster模式下,Container中运行的进程=org.apache.spark.deploy.yarn.ApplicationMaster
// client模式下,Container中运行的进程=org.apache.spark.deploy.yarn.ExecutorLauncher
--val containerContext = createContainerLaunchContext(newAppResponse) //准备Container中进程的启动命令
--val appContext = createApplicationSubmissionContext(newApp, containerContext) //设置Spark的相关参数,安装AM在Container中运行的上下文
-- yarnClient.submitApplication(appContext) //提交应用到RM直到提交成功,RM接收
③ 在Container中运行 AMClass: org.apache.spark.deploy.yarn.ExecutorLauncher
// 本质就是ApplicationMaster,为了在使用ps或jps命令时,一目了然当前是client模式还是cluster模式
org.apache.spark.deploy.yarn.ExecutorLauncher
--main
--ApplicationMaster.main(args)
----val amArgs = new ApplicationMasterArguments(args) // 获取AM需要的参数
--val sparkConf = new SparkConf()
--master = new ApplicationMaster(amArgs, sparkConf, yarnConf) //创建ApplicationMaster对象
--System.exit(master.run())
-- 如果是cluster模式: runDriver()
--如果是client模式: runExecutorLauncher()
-- runExecutorLauncher() //运行Driver
--val rpcEnv = RpcEnv.create("sparkYarnAM", hostname, hostname, -1, sparkConf, securityMgr,
amCores, true)
-- registerAM(host, port, userConf, sc.ui.map(_.webUrl), appAttemptId) //向RM注册 AM
--val client = new YarnRMClient()
-- client.register(host, port, yarnConf, _sparkConf, uiAddress, historyAddress)
--val driverRef = rpcEnv.setupEndpointRef //获取Driver的 EndpointRef
--createAllocator(driverRef, userConf, rpcEnv, appAttemptId, distCacheConf)
// allocator:YarnAllocator 负责申请资源,在申请到Containers 后决定拿Container干什么
--allocator = client.createAllocator
--allocator.allocateResources() // 向RM发请求,申请Containers
--val allocatedContainers = allocateResponse.getAllocatedContainers() //尝试申请可分配的资源
--if (allocatedContainers.size > 0){
--handleAllocatedContainers(allocatedContainers.asScala) // 决定用Container干什么事情
--runAllocatedContainers(containersToUse)
--for (container <- containersToUse){ //对于每个Container
if (launchContainers) {
launcherPool.execute(() => {
try {
new ExecutorRunnable().run()
--nmClient = NMClient.createNMClient() //创建和NM通信的客户端
--nmClient.init(conf)
--nmClient.start()
--startContainer() // 正式启动NM上的Container
//org.apache.spark.executor.YarnCoarseGrainedExecutorBackend Container中启动的进程
--val commands = prepareCommand() //准备在Container上运行的Java命令
}
}
。。。。。。
********************
任务调度机制,job任务提交,Spark Shuffle解析,内存管理 见下篇