R语言十大算法之KNN案列
R语言的机器算法的学习不是很难,把握清楚思路就可以进行操作了!不要慌,慢慢积累,一天一小部分的知识输入输出。
首先,先了解以下什么是KNN吧(KNN近邻算法)?
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间(你可以随便圈一个区域)中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
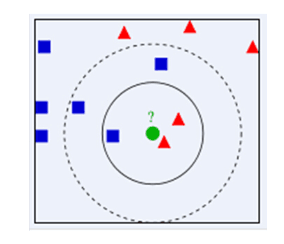
举个列子:当在中心的这个实线圆圈里面共有4个物体,其中2个红三角,一个蓝方形,绿圆未知,要我们判断它属于红方还是蓝方?思考一下,不要看答案,绿圆属于红三角,因为在这个实线圆圈的区域里面,红方多于蓝方,所以绿归为了红方,如果我画的区域是这条虚线圆圈呢?欸,这个时候情况不同了,绿园属于蓝方了哦!好了,对于KNN相信大家也相对了解了一些了,我们看看R语言如何实现吧!
KNN的应用场景,它是干嘛的?要做哪些前期准备?
1.KNN是一种分类学习算法,即当我们需要判断某人是否患病,我们可以通过分析患病人的显著特征以此来判断该人是属于病人还是正常人,同理其他的分类也可以,比如通过分析相关的数据判断城市是发达的还是
版权声明:本文为weixin_43408110原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。