文章链接:
[1707.00408] Pedestrian Alignment Network for Large-scale Person Re-identification
代码链接:
layumi/Pedestrian_Alignment
发表于 IEEE Transactions on Circuits and Systems for Video Technology
1.Motivation
近年来,对行人再识别(person re-ID)问题的研究也越来越多了。类比于自然语言处理(nlp)的话,大家或者集中于语义层面的设计(比如设计loss,triplet loss,identi+verif loss),或者集中于语法层面上(利用人体的内在结构,比如水平切割,pose预测)。
这篇文章集中于语法层面上,也就是利用人体结构来增强识别能力。现阶段行人重识别的发展一部分是归因于大数据集和深度学习方法的出现。现有大数据集往往采用自动检测的方法,比如DPM 来检测行人,把行人从背景中切割出来。或者花钱,邀请很多标注者一起来抠人,标注数据。
但是 自动检测会包含错误,影响下一阶段的学习和识别; 人为抠的行人图像 虽然明显错误较少,但包含不同的bias,也同样未必适合下阶段 深度学习方法的学习。 所以一个直接的想法: 让深度学习方法自己来矫正输入,学习一个二维的变换,把行人对齐好以后,再做下一步的识别。
那么我们如何定义什么样的二维变换是好的变换呢? 需要额外的监督信息来学习么,比如行人pose的groundtruth?
不需要额外的信息标注。 本文提出一个想法,直接用我们识别人这个信息就好了。 因为 行人对齐和行人识别是可以互利互惠的两个问题。 当我们做行人识别的时候,行人人体是高亮的(可以见如下的热度图),背景中不含重要信息,自然就区分出来了。所以我们可以依此来把人体抠出来,预测输入的变换方式。 而反过来,当行人数据对齐得好的时候,行人识别也可以识别得更准。 达到互相帮助的目的。
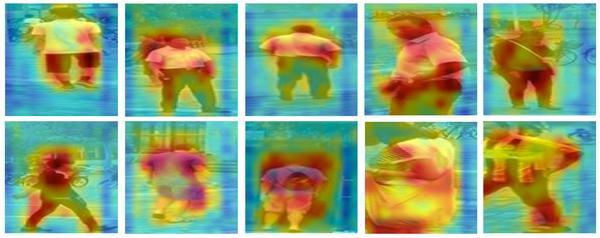
下图为对齐的效果 (上一行为原始检测,下一行为对齐后的结果)。可以看到我们的方法对于两种常见检测错误都有作用,过多背景(比如把树和操场也包含了) 和 部件缺失(比如腿没了)。 在对齐后,图像输入回到了同一个尺度(比如人脸大小差异不是那么大了),更容易做人与人之间的比较。

2.Method
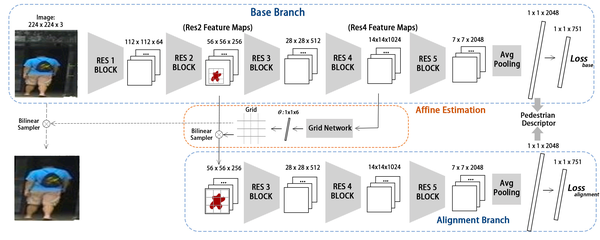
实验方法也相对直接。网络包含两个CNN分类网络 蓝色部分(Base Branch + Alignment Branch),一个映射预测网络 橙色部分(Affine Estimation)。
接下来我们按顺序来介绍。
Base Branch 其实就是一个传统的finetune的ResNet。在Market1501中包含751个不同行人的训练数据,故在示例图像中,最后fc是到751类,执行行人识别的预测。
而Affine Estimation 其实也是一个CNN,输入为base branch的Res4 Block的输出(大小为14x14x1024),其中已经蕴含了对人体的attention(可视化就是刚才的热度图), 输出为 6维的向量 θ。
如果大家熟悉二维仿射变换的化,其实这6维向量θ 也没什么神秘的。就是下面这个公式中的xy变换对应的系数而已。
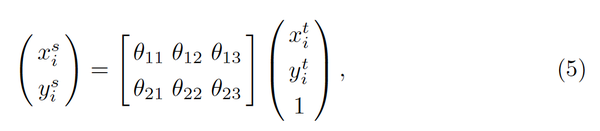
我们可以将这个变换应用于原图(224x224x3),不过,网络前几层都是用来提取边缘信息,基本可以共享,所以实际上在设计中,我们直接把这个变换应用在Res2Block的输出上(56x56x256),在仿射变换之后得到的的输出也为(56x56x256).
现在我们再把另一个分类网络(图中下半部)接上去。输入56x56x256的tensor, 也执行一个751类分类就好了。
好,为了帮助理解,我们再反过头思考一下这个网络是怎么work起来的。进行一下梳理。
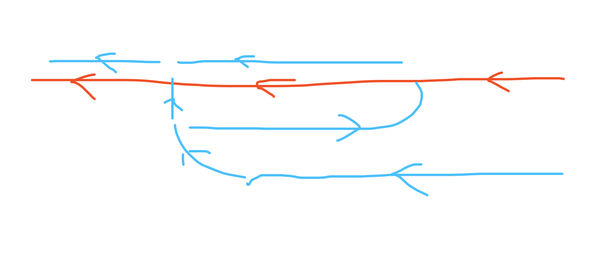
在反向传播的时候,因为只有两个loss,流向如上图。红色为第一个分类loss,第二个loss为从调整过的输入这边过来的分类loss。而关键的θ其实也是由第二网络的loss来进行调整,也就是一开始说的,利用识别行人的loss 来指导 行人对齐网络的学习,不需要额外的标注信息。
3.Experiments
光用识别人的loss真的可以有效果么?一开始我们也担心这个。如下为实验中,将θ应用于原图得到的效果。在三个数据集(两个自动检测,一个人为标注)上,我们都可以看到调整后的效果。虽然也有限,但还是有些我们希望的效果。(背景过多的,我们切掉; 背景过少,缺部件的,我们用0来填,0就是图中的黑色像素。)这样可以减轻后面分类网络的压力,make it easy。

量化的行人重识别指标也都不错。(注:其中cuhk03跑的是新的test setting,图像一半训练一半测试,所以指标相对低一些)

在Market上 对齐以后的结果,并没有超过原来的base的结果。这可能是market真的有太多剧烈的变化了,检测结果bias大。 反而是在一些人为抠行人的数据集上,我们一开始会认为没有太大提升。但对齐后往往可以有3%的rank1提升,说明网络克服相对小的bias很拿手。
另外, 当我们把base 和alignment两个网络的embedding接在一起,可以进一步提升效果,在一些数据集上达到了state-of-the-art。
4.额外实验
另外,还是比较好奇,这样训练出来网络的对齐是不是真的靠谱。所以我们用不断变小的输入,来看这个对齐是不是鲁棒。实验效果如下面这些gif。左侧是输入,右侧为对齐后的结果。


更多细节可以在论文对应github上找到。
5.相关阅读
其实本文本质上是对输入做了处理,使得后面识别更简单,希望能更容易找到有区分能力的特征。同时不需要利用额外标注信息。 与本文相关,还有一些更显式的做法,利用pose定点。大家有兴趣的话,还可以看以下这些paper。
[1]
Pose Invariant Embedding for Deep Person Re-identification
[2]
Spindle_Net_Person
感谢看完,欢迎讨论。
更多内容 关注
行人重识别
专栏