前一篇CUDA学习,我们已经完成了编程环境的配置,现在我们继续深入去了解CUDA编程。本博文分为三个部分,第一部分给出一个代码示例,第二部分对代码进行讲解,第三部分根据这个例子介绍如何部署和发起一个kernel函数。
一、代码示例
#include< stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
// Simple utility function to check for CUDA runtime errors
void checkCUDAError(const char *msg);
// Part 3 of 5: implement the kernel
__global__ void myFirstKernel(int *d_a)
{
int i=blockIdx.x*blockDim.x+threadIdx.x;
d_a[i]=1000 * blockIdx.x + threadIdx.x;
}
// Program main
int main( int argc, char** argv)
{
// pointer for host memory
int *h_a;
// pointer for device memory
int *d_a;
// define grid and block size
int numBlocks = 8;
int numThreadsPerBlock = 8;
// Part 1 of 5: allocate host and device memory
size_t memSize = numBlocks * numThreadsPerBlock * sizeof(int);
h_a = (int *) malloc(memSize);
cudaMalloc((void**)&d_a,memSize);
// Part 2 of 5: configure and launch kernel
dim3 dimGrid(numBlocks,1,1);
dim3 dimBlock(numThreadsPerBlock,1,1);
myFirstKernel<<
>>(d_a);
// block until the device has completed
cudaThreadSynchronize();
// check if kernel execution generated an error
checkCUDAError("kernel execution");
// Part 4 of 5: device to host copy
cudaMemcpy(h_a,d_a,memSize,cudaMemcpyDeviceToHost);
// Check for any CUDA errors
checkCUDAError("cudaMemcpy");
// Part 5 of 5: verify the data returned to the host is correct
for (int i = 0; i
二、代码解说
void checkCUDAError(const char *msg);
申明一个函数,用于检测CUDA运行中是否出错。
__global__ void myFirstKernel(int *d_a)
{
int i=blockIdx.x*blockDim.x+threadIdx.x;
d_a[i]=1000 * blockIdx.x + threadIdx.x;
}
kernel函数,blockIdx.x表示block在x方向的索引号,blockDim.x表示block在x方向的维度,threadIdx.x表示thread在x方向的索引号。
这里也许你会问,为什么在x方向?难道还有其他方向?
对的,grid
可以是一维、二维,
block可以是一维、二维和三维的。一个grid里包含多个block,一个block里也包含多个thread,可参考下图。
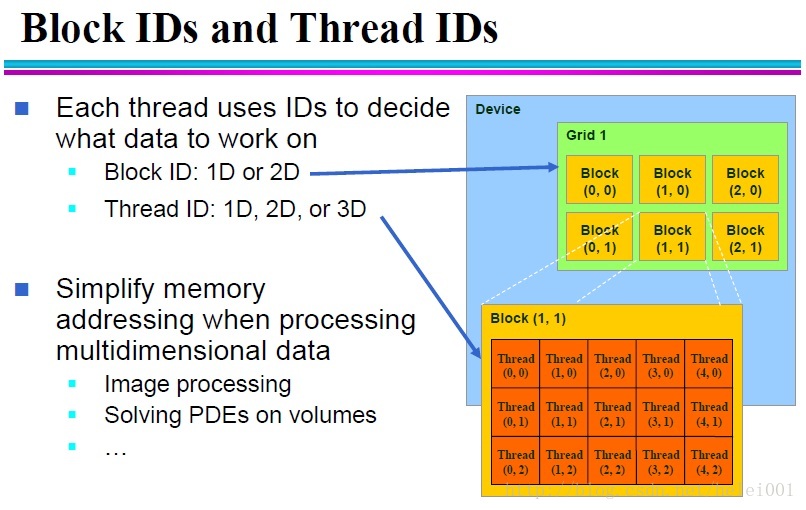
从而,i是每个thread的索引号,也许你会问为什么不直接是
threadIdx.x呢?
因为每个block里的
threadIdx.x都是从0到
blockDim.x(假设
block是一维的
),那么不同的
block里
threadIdx.x会出现相同的值,我们就不知道该调用那个thread来执行,因为用
threadIdx.x+
blockIdx.x*
blockDim.x表示每个thread的索引号,这样就是唯一的了。举个例子,假设grid和block都是一维的,
blockDim.x=8,
threadIdx.x从0到7,
blockIdx.x也是
从0到7,那么i就是0,1,2,3,4,5,6,7,8,9,10,11...63,从而保证了每个thread索引号的唯一性。
// pointer for host memory
int *h_a;
// pointer for device memory
int *d_a;
// define grid and block size
int numBlocks = 8;
int numThreadsPerBlock = 8;
申请两个指针
*
h_a和
*
d_a
,分别指向host内存和device内存,host是指主程序cpu内存,device是指gpu内存(global memory)。并定义一个grid里block数(即
numBlocks)和每个block里thread数
numThreadsPerBlock。
size_t memSize = numBlocks * numThreadsPerBlock * sizeof(int);
h_a = (int *) malloc(memSize);
cudaMalloc((void**)&d_a,memSize);
分配host和device内存,
cudaMalloc
((
void
**
)
&
d_a
,
memSize
)是给device中
d_a分配
memSize字节的内存,为什么前面有
(
void
**
)
&呢?因为这个内存分配要通过cpu传给gpu。
dim3 dimGrid(numBlocks,1,1);
dim3 dimBlock(numThreadsPerBlock,1,1);
myFirstKernel<<
>>(d_a);
部署并发起kernel函数,
k
ernel函数是跑在gpu上的那段程序,即我们之前申明的
myFirstKernel函数。部署:
dimGrid
(
numBlocks
,
1
,
1
),一维的grid,里面包含
numBlocks个block;
dimBlock
(
numThreadsPerBlock
,
1
,
1
),grid里每个block都是一维的,每个block有
numThreadsPerBlock个thread。发起kernel函数:
myFirstKernel
<<<
dimGrid
,
dimBlock
>>>
(
d_a
),第一个是函数名,括号里是kernel的部署,后面一个是函数的参数。
cudaThreadSynchronize();
checkCUDAError("kernel execution");
同步并检查kernel函数运行是否出错。为什么要同步呢?因为每个thread运行的时间是不一样的,只有等所有线程都跑完了,我们才做下一件事。这会造成运行的性能降低,但是是必要的。
cudaMemcpy(h_a,d_a,memSize,cudaMemcpyDeviceToHost);
cudaMemcpy函数完成数据在host和device之间的传输,第一个参数是传输的目标,第二个参数是传输的源数据,第三个参数传输的数据量,第四个参数是传输的方向,这里是从device传到host。
checkCUDAError("cudaMemcpy");
检查cudaMemcpy函数运行是否出错。
for (int i = 0; i
检查从device传回的数据是否正确。
cudaFree(d_a);
free(h_a);
释放host和device内存。
void checkCUDAError(const char *msg)
{
cudaError_t err = cudaGetLastError();
if( cudaSuccess != err)
{
fprintf(stderr, "Cuda error: %s: %s.\n", msg, cudaGetErrorString( err) );
exit(-1);
}
}
检查CUDA函数是否运行正确的函数。
三、
部署和发起一个kernel函数
如上述,对kernel函数先申明,在函数体中实现线程的算法,即:
__global__ void myFirstKernel(int *d_a)
{
int i=blockIdx.x*blockDim.x+threadIdx.x;
d_a[i]=1000 * blockIdx.x + threadIdx.x;
}
然后部署和发起kernel函数,即:
// define grid and block size
int numBlocks = 8;
int numThreadsPerBlock = 8;
// Part 1 of 5: allocate host and device memory
size_t memSize = numBlocks * numThreadsPerBlock * sizeof(int);
h_a = (int *) malloc(memSize);
cudaMalloc((void**)&d_a,memSize);
// Part 2 of 5: configure and launch kernel
dim3 dimGrid(numBlocks,1,1);
dim3 dimBlock(numThreadsPerBlock,1,1);
myFirstKernel<<
>>(d_a);
综上,我们完成代码的讲解,部署和发起一个kernel函数
。想必你现在应该对CUDA有了较为深入的了解了!是吧?