关于数据集
首先关于如何把csv文件中的数字文件还原为图片可以看我的这篇博文
https://blog.csdn.net/qq_38905818/article/details/104411572

首先我们要搞清楚,为什么数据集要分为train、val、test
train是训练集,val是训练过程中的测试集,是为了让你在边训练边看到训练的结果,及时判断学习状态。test就是训练模型结束后,用于评价模型结果的测试集。只有train就可以训练,val不是必须的,比例也可以设置很小。test对于model训练也不是必须的,但是一般都要预留一些用来检测,通常推荐比例是8:1:1
那么我们如何去处理这样的一个csv文件比较合适呢?
对于这种大数据量的图像数据,可以使用HDF5(.h5)的格式去处理,Python中可以使用h5py的包
使用h5py库读写超过内存的大数据 。在简单数据的读操作中,我们通常一次性把数据全部读入到内存中。读写超过内存的大数据时,有别于简单数据的读写操作,受限于内存大小,通常需要指定位置、指定区域读写操作,避免无关数据的读写。 h5py库刚好可以实现这一功能。
h5py的优势:速度快、压缩效率高,总之,numpy.savez和cPickle存储work或不work的都可以试一试h5py!h5py文件是存放两类对象的容器,数据集(dataset)和组(group),dataset类似数组类的数据集合,和numpy的数组差不多。group是像文件夹一样的容器,它好比python中的字典,有键(key)和值(value)。group中可以存放dataset或者其他的group。”键”就是组成员的名称,”值”就是组成员对象本身(组或者数据集),下面来看下如何创建组和数据集。
# create data and label for FER2013
# labels: 0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral
import csv
import os
import numpy as np
import h5py
file = 'data/fer2013.csv'
# Creat the list to store the data and label information
Training_x = []
Training_y = []
PublicTest_x = []
PublicTest_y = []
PrivateTest_x = []
PrivateTest_y = []
datapath = os.path.join('data','data.h5')
if not os.path.exists(os.path.dirname(datapath)):
os.makedirs(os.path.dirname(datapath))
with open(file,'r') as csvin:
data=csv.reader(csvin)
for row in data:
if row[-1] == 'Training':
temp_list = []
for pixel in row[1].split( ):
temp_list.append(int(pixel))
I = np.asarray(temp_list)
Training_y.append(int(row[0]))
Training_x.append(I.tolist())
if row[-1] == "PublicTest" :
temp_list = []
for pixel in row[1].split( ):
temp_list.append(int(pixel))
I = np.asarray(temp_list)
PublicTest_y.append(int(row[0]))
PublicTest_x.append(I.tolist())
if row[-1] == 'PrivateTest':
temp_list = []
for pixel in row[1].split( ):
temp_list.append(int(pixel))
I = np.asarray(temp_list)
PrivateTest_y.append(int(row[0]))
PrivateTest_x.append(I.tolist())
print(np.shape(Training_x))
print(np.shape(PublicTest_x))
print(np.shape(PrivateTest_x))
datafile = h5py.File(datapath, 'w')
datafile.create_dataset("Training_pixel", dtype = 'uint8', data=Training_x)
datafile.create_dataset("Training_label", dtype = 'int64', data=Training_y)
datafile.create_dataset("PublicTest_pixel", dtype = 'uint8', data=PublicTest_x)
datafile.create_dataset("PublicTest_label", dtype = 'int64', data=PublicTest_y)
datafile.create_dataset("PrivateTest_pixel", dtype = 'uint8', data=PrivateTest_x)
datafile.create_dataset("PrivateTest_label", dtype = 'int64', data=PrivateTest_y)
datafile.close()
print("Save data finish!!!")
关于训练
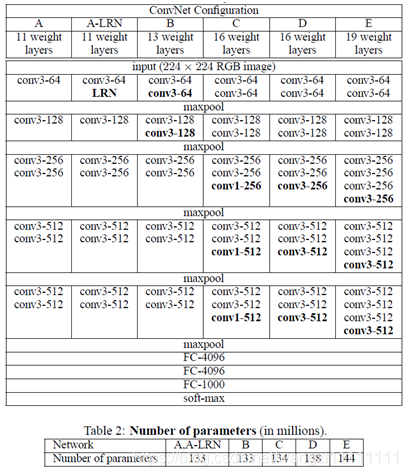
对于训练图片分类识别的问题,目前比较流行的模型是VGG和Resnet
VGG model的构建
'''VGG11/13/16/19 in Pytorch.'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 7)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = F.dropout(out, p=0.5, training=self.training)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
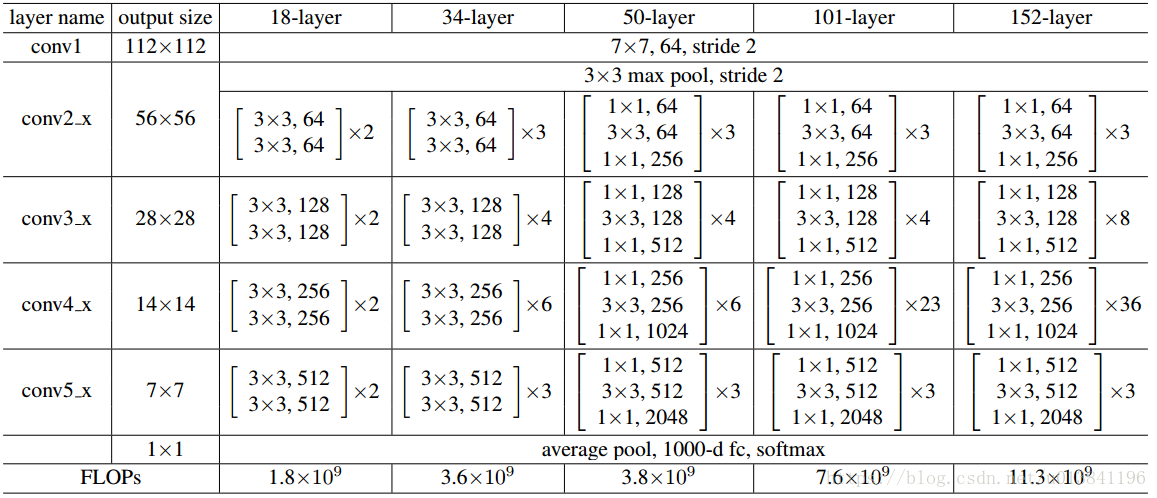
Resnet model的构建
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=7):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = F.dropout(out, p=0.5, training=self.training)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2,2,2,2])
这边推荐用GPU跑,不然速度很慢
先检测下你的机子是否支持CUDA
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)'''Train Fer2013 with PyTorch.'''
# 10 crop for data enhancement
from __future__ import print_function
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torch.backends.cudnn as cudnn
import torchvision
import transforms as transforms
import numpy as np
import os
import argparse
import utils
from fer import FER2013
from torch.autograd import Variable
from models import *
parser = argparse.ArgumentParser(description='PyTorch Fer2013 CNN Training')
parser.add_argument('--model', type=str, default='VGG19', help='CNN architecture')
parser.add_argument('--dataset', type=str, default='FER2013', help='CNN architecture')
parser.add_argument('--bs', default=32, type=int, help='learning rate')
parser.add_argument('--lr', default=0.01, type=float, help='learning rate')
parser.add_argument('--resume', '-r', action='store_true', help='resume from checkpoint')
opt = parser.parse_args()
torch.cuda.current_device()
torch.cuda._initialized = True
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)
use_cuda = torch.cuda.is_available()
best_PublicTest_acc = 0 # best PublicTest accuracy
best_PublicTest_acc_epoch = 0
best_PrivateTest_acc = 0 # best PrivateTest accuracy
best_PrivateTest_acc_epoch = 0
start_epoch = 0 # start from epoch 0 or last checkpoint epoch
learning_rate_decay_start = 80 # 50
learning_rate_decay_every = 5 # 5
learning_rate_decay_rate = 0.9 # 0.9
cut_size = 44
total_epoch = 250
path = os.path.join(opt.dataset + '_' + opt.model)
# Data
print('==> Preparing data..')
transform_train = transforms.Compose([
transforms.RandomCrop(44),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
transform_test = transforms.Compose([
transforms.TenCrop(cut_size),
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),
])
trainset = FER2013(split = 'Training', transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=opt.bs, shuffle=True, num_workers=0)
PublicTestset = FER2013(split = 'PublicTest', transform=transform_test)
PublicTestloader = torch.utils.data.DataLoader(PublicTestset, batch_size=opt.bs, shuffle=False, num_workers=0)
PrivateTestset = FER2013(split = 'PrivateTest', transform=transform_test)
PrivateTestloader = torch.utils.data.DataLoader(PrivateTestset, batch_size=opt.bs, shuffle=False, num_workers=0)
# Model
if opt.model == 'VGG19':
net = VGG('VGG19')
elif opt.model == 'Resnet18':
net = ResNet18()
if opt.resume:
# Load checkpoint.
print('==> Resuming from checkpoint..')
assert os.path.isdir(path), 'Error: no checkpoint directory found!'
checkpoint = torch.load(os.path.join(path,'PrivateTest_model.t7'))
net.load_state_dict(checkpoint['net'])
best_PublicTest_acc = checkpoint['best_PublicTest_acc']
best_PrivateTest_acc = checkpoint['best_PrivateTest_acc']
best_PrivateTest_acc_epoch = checkpoint['best_PublicTest_acc_epoch']
best_PrivateTest_acc_epoch = checkpoint['best_PrivateTest_acc_epoch']
start_epoch = checkpoint['best_PrivateTest_acc_epoch'] + 1
else:
print('==> Building model..')
if use_cuda:
net.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=opt.lr, momentum=0.9, weight_decay=5e-4)
# Training
def train(epoch):
print('\nEpoch: %d' % epoch)
global Train_acc
net.train()
train_loss = 0
correct = 0
total = 0
if epoch > learning_rate_decay_start and learning_rate_decay_start >= 0:
frac = (epoch - learning_rate_decay_start) // learning_rate_decay_every
decay_factor = learning_rate_decay_rate ** frac
current_lr = opt.lr * decay_factor
utils.set_lr(optimizer, current_lr) # set the decayed rate
else:
current_lr = opt.lr
print('learning_rate: %s' % str(current_lr))
for batch_idx, (inputs, targets) in enumerate(trainloader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
optimizer.zero_grad()
inputs, targets = Variable(inputs), Variable(targets)
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
utils.clip_gradient(optimizer, 0.1)
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
utils.progress_bar(batch_idx, len(trainloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (train_loss/(batch_idx+1), 100.*correct/total, correct, total))
Train_acc = 100.*correct/total
def PublicTest(epoch):
global PublicTest_acc
global best_PublicTest_acc
global best_PublicTest_acc_epoch
net.eval()
PublicTest_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(PublicTestloader):
bs, ncrops, c, h, w = np.shape(inputs)
inputs = inputs.view(-1, c, h, w)
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs, volatile=True), Variable(targets)
outputs = net(inputs)
outputs_avg = outputs.view(bs, ncrops, -1).mean(1) # avg over crops
loss = criterion(outputs_avg, targets)
PublicTest_loss += loss.item()
_, predicted = torch.max(outputs_avg.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
utils.progress_bar(batch_idx, len(PublicTestloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (PublicTest_loss / (batch_idx + 1), 100. * correct / total, correct, total))
# Save checkpoint.
PublicTest_acc = 100.*correct/total
if PublicTest_acc > best_PublicTest_acc:
print('Saving..')
print("best_PublicTest_acc: %0.3f" % PublicTest_acc)
state = {
'net': net.state_dict() if use_cuda else net,
'acc': PublicTest_acc,
'epoch': epoch,
}
if not os.path.isdir(path):
os.mkdir(path)
torch.save(state, os.path.join(path,'PublicTest_model.t7'))
best_PublicTest_acc = PublicTest_acc
best_PublicTest_acc_epoch = epoch
def PrivateTest(epoch):
global PrivateTest_acc
global best_PrivateTest_acc
global best_PrivateTest_acc_epoch
net.eval()
PrivateTest_loss = 0
correct = 0
total = 0
for batch_idx, (inputs, targets) in enumerate(PrivateTestloader):
bs, ncrops, c, h, w = np.shape(inputs)
inputs = inputs.view(-1, c, h, w)
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs, volatile=True), Variable(targets)
outputs = net(inputs)
outputs_avg = outputs.view(bs, ncrops, -1).mean(1) # avg over crops
loss = criterion(outputs_avg, targets)
PrivateTest_loss += loss.item()
_, predicted = torch.max(outputs_avg.data, 1)
total += targets.size(0)
correct += predicted.eq(targets.data).cpu().sum()
utils.progress_bar(batch_idx, len(PublicTestloader), 'Loss: %.3f | Acc: %.3f%% (%d/%d)'
% (PrivateTest_loss / (batch_idx + 1), 100. * correct / total, correct, total))
# Save checkpoint.
PrivateTest_acc = 100.*correct/total
if PrivateTest_acc > best_PrivateTest_acc:
print('Saving..')
print("best_PrivateTest_acc: %0.3f" % PrivateTest_acc)
state = {
'net': net.state_dict() if use_cuda else net,
'best_PublicTest_acc': best_PublicTest_acc,
'best_PrivateTest_acc': PrivateTest_acc,
'best_PublicTest_acc_epoch': best_PublicTest_acc_epoch,
'best_PrivateTest_acc_epoch': epoch,
}
if not os.path.isdir(path):
os.mkdir(path)
torch.save(state, os.path.join(path,'PrivateTest_model.t7'))
best_PrivateTest_acc = PrivateTest_acc
best_PrivateTest_acc_epoch = epoch
for epoch in range(start_epoch, total_epoch):
train(epoch)
PublicTest(epoch)
PrivateTest(epoch)
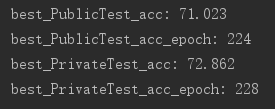
print("best_PublicTest_acc: %0.3f" % best_PublicTest_acc)
print("best_PublicTest_acc_epoch: %d" % best_PublicTest_acc_epoch)
print("best_PrivateTest_acc: %0.3f" % best_PrivateTest_acc)
print("best_PrivateTest_acc_epoch: %d" % best_PrivateTest_acc_epoch)
训练中中启用了SGD
optimizer = optim.SGD(net.parameters(), lr=opt.lr, momentum=0.9, weight_decay=5e-4)
https://blog.csdn.net/AMDS123/article/details/69621688

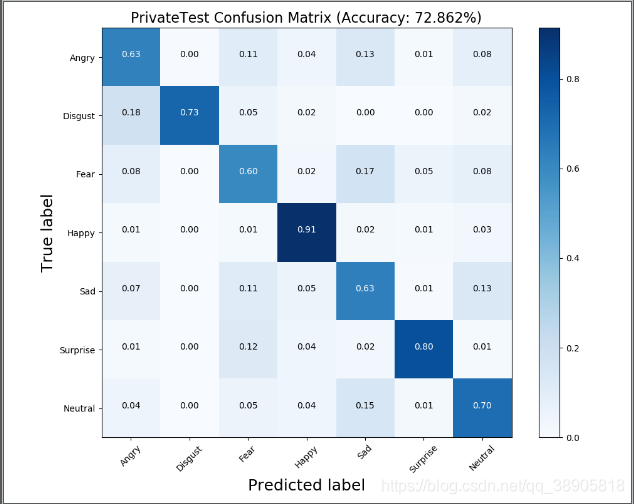
结果