搭建自己的网站,是作为一个码农
成功标志
之一,
那其他成功标志有啥呢,
嘿…
左手搂着白富美,右手撸着小烧烤,脚底踩着桑塔纳…
嗯~
这么潇洒的人生,就从
数据库表设计及数据存储
开始吧!
1. 爬取数据
有的小朋友会说,鱼叔,你这不是数据库表设计吗,怎么还送套餐是咋的?
哈哈~
买二送一…
我们爬取数据,是为了把数据直接存储到数据库中,这样就省下来造数据的过程~
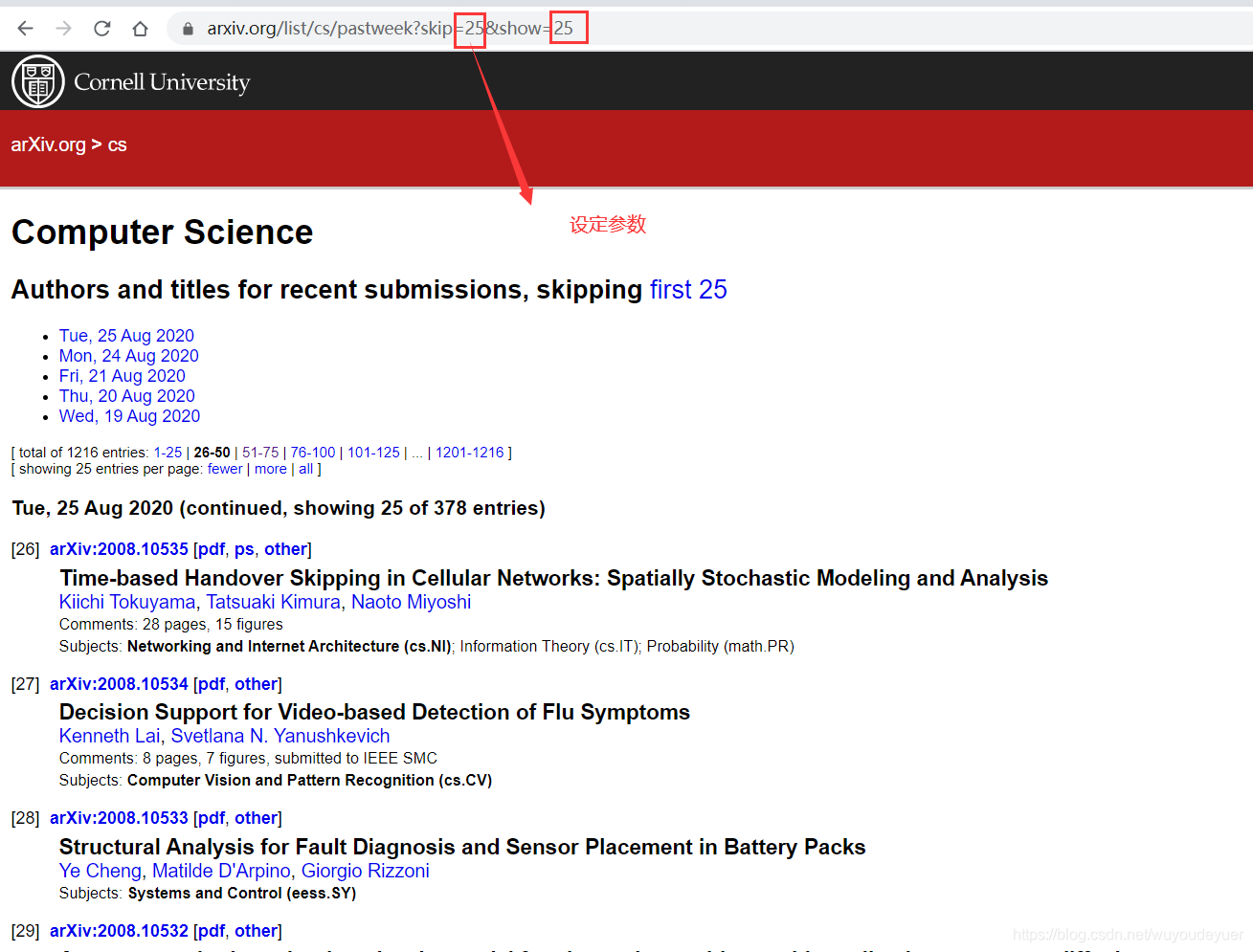
我们今天爬取的内容,是这个网站
url = https://arxiv.org/list/cs/recent
这里汇集了外国各路大佬的大神级作品,而且还是
免费
的!
如果看不懂的话,可以谷歌翻译~!
我们看看这个网站长啥样子
老规矩,上代码
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2020-8-26
"""
import requests
import csv
import traceback
from bs4 import BeautifulSoup
from PaperWeb.Servers.utils.requests import get_http_session
def gen_paper(skip):
try:
#url的skip设定参数,每次展示100条数据
url = 'https://arxiv.org/list/cs/pastweek?skip={skip}&show=100'
#设定headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
#设定代理,如果未购买,则不需要填写,
proxies = {
'http':"http://127.0.0.1:1092"
'https':"http://127.0.0.1:1092"
}
#引用http代理池,避免资源被耗尽
r = get_http_session().get(url,headers=headers,proxies=proxies)
#不运用代理,则注释掉proxies=proxies
#r = get_http_session().get(url,headers=headers)
#判断返回状态
if r.status_code !=200:
return False,'请求网页失败'
#使用lxml,是因为解析速度快
soup = BeautifulSoup(r.text,'lxml')
#获取论文url的信息
all_dt = soup.find_all('dt')
#获取论文的标题与作者
all_dd = soup.find_all('dd')
#使用zip方法,循环获取dd 和dt的内容,
for dt,dd in zip(all_dt,all_dd):
#因为class是关键字,所以用_作区分,
#获取url,通过class下的a标签的href链接来获取
api_url = dt.find(class_ = 'list-identifier').find('a').get('href')
root_url = 'https://arxiv.org'
full_url = root_url + api_url
"""
最开始使用contents,是直接获取到title的内容,text获取的内容很多,多而乱
"""
#获取title,通过class标签下的contents获取,返回list
title = dd.find(class_ = 'list-title mathjax').contents
#对内容进行判断,如果titles的长度>=3,就截取第2部分
if len(title) >=3:
title = title[2]
else:
#text,返回的是str,
title = dd.find(class_ = 'list-title mathjax').text
#论文作者
authors = dd.find(class_='descriptor').text
#由于一行很多作者,所以要进行切分
authors = authors.split(':')[1].replace('\n','')
#生成器
yield title,full_url,authors
except Exception as e:
#输出错误日志信息
log(traceback.format_exc(),'error','gen_paper.log')
error_str = f'authors:[full_url:[{full_url},{authors}],title:[{title}'
log(error_str,'error','gen_paper.log')
# #打印错误
# print(e)
# traceback.print_exc()
def log(content,level,filepath):
"""
:param content:输入错误信息内容
:param level:错误等级
:param filepath:路径
:return:
"""
if level =='error':
with open(filepath,'a') as f:
f.write(content)
elif level =='fail':
with open(filepath,'a') as f :
f.write(content)
def run_main():
'''
保存到csv文件中
:return:
'''
#定义一个空列表
resl = []
#循环所有的数据信息,一共有1273条论文,间隔100
for i in range(0,1273,100):
#这里的i 就是 skip,
for full_url,title,authors in gen_paper(i):
#添加到list中
resl.append([title,full_url,authors])
print(title,'done')
#打开文件,进行保存
with open('paper.csv','w') as f :
#打开上面获取到的文件内容
cw = csv.writer(f)
#写数据到csv中
for i in resl:
#写一行
cw.writerow(i)
if __name__ == '__main__':
run_main()
这里不过多的对内容进行解析,不太明白的,可以看注释,
个人觉得,嗯~,
虽然不是句句有注释,但是也没达到句句没有注释!
在不明白的,看小鱼这篇文章
《Python3,多线程爬完B站UP主的视频弹幕及评论》
这里面,能解释的,可都解释了!
瞅瞅,这就是运用到的
代理
#设定代理,如果未购买,则不需要填写
proxies = {
'http':"http://127.0.0.1:1092"
'https':"http://127.0.0.1:1092"
}
#引用http代理池,避免资源被耗尽,传入三个参数
r = get_http_session().get(url,headers=headers,proxies=proxies)
代理是要
花银子
的,如果不是靠吃爬虫这碗饭的,或者不是发烧友,弄个免费的代理就行,虽然不稳定,但是,也行~
运行结果
:
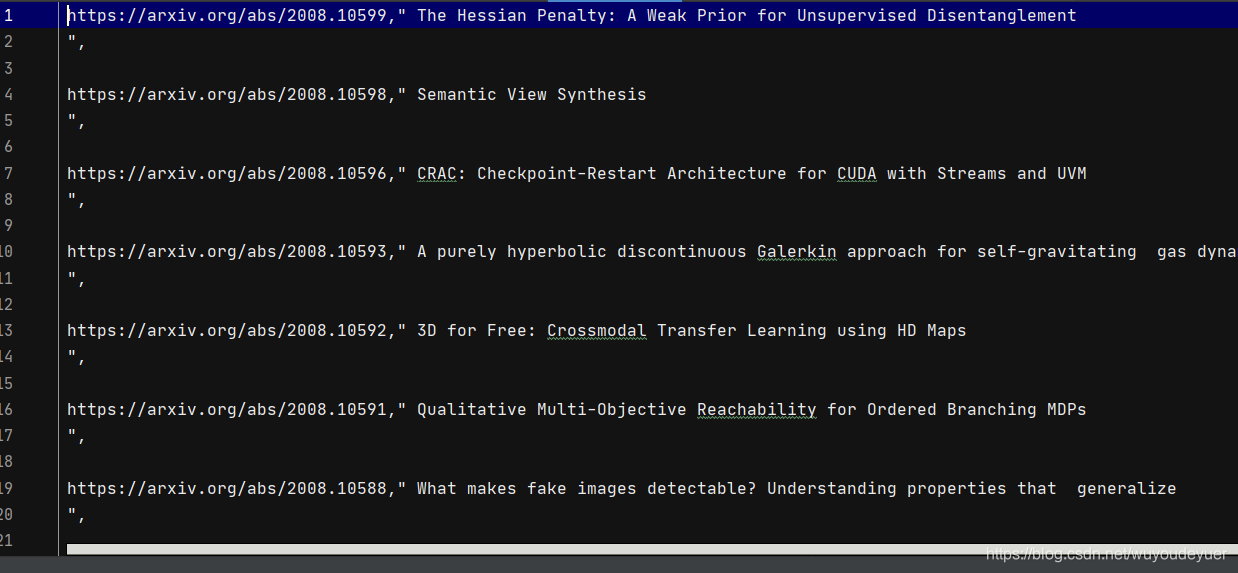
我为啥要把展示结果,
是因为要品一品,这爬取的结果,
香不香
。
2. 创建数据库
2.1 创建数据库表
一个是把创建的数据表,在pycharm的工程中写入
如下:
create.sql
--数据表
CREATE TABLE 'papers'(
'id' int(11) NOT NULL AUTO_INCREMENT,
'title' varchar(500) NOT NULL DEFAULT ''COMMIT '论文标题',
'url' varchar(200) NOT NULL DEFAULT ''COMMIT '论文url',
'authors' varchar(200) NOT NULL DEFAULT ''COMMIT '论文作者',
'create_time' int(20) NOT NULL DEFAULT 0 COMMIT '创建时间',
'update_time' int(20) NOT NULL DEFAULT 0 COMMIT '更新时间',
'is_delete' tinyint(4) NOT NULL DEFAULT 0 COMMIT '是否删除',
PRIMARY KEY ('id'),
KEY 'title_IDX' ('title') USING BTREE,
KEY 'authors_IDX' ('authors') USING BTREE
)ENGINE=InnoDB AUTO_INCREMENT =1 DEFAULT CHARSET=utf8 COMMIT='论文表'
这里展示的是MySQL的基本创建表的内容,不会的,可以看小鱼这篇
《SQL基本用法一》
再看不懂的,就看看自己的银行卡余额,自己的左手及右手~
估计就会了!
写完之后,别忘了在数据库执行一下,不然怎么能生成表呢~
2.2 连接数据库
我们创建了数据库,就要通过pymysql把数据库连接起来,这样才能用起来~
继续上代码
mysql.py
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2020-8-26
"""
import pymysql
import logging
'''
创建mysql数据库链接
'''
class MySQL(object):
#创建数据库的基本链接信息
def __init__(self,host='localhost',port = 3306,user='root',password = '123456',db='test'):
#cursorclass = pymysql.cursors.DictCursor 数据库查询返回dict --> 默认返回值是 tuple
self.conn = pymysql.connect(
host = host,
port = port,
user=user,
password=password,
db=db,
charset = 'utf8',
cursorclass = pymysql.cursors.DictCursor
)
#定义logger
self.log = logging.getLogger(__name__)
def execute(self,sql,kwargs = None):
# 创建mysql数据库链接
try:
#获取游标
cursor = self.conn.cursor()
#通过游标获取执行方法
cursor.execute(sql,kwargs)
#提交插入,删除等操作
self.conn.commit()
return cursor
except Exception as e:
#记录错误信息
self.log.error(f'mysql execute eror:{e}',exc_info=True)
raise e
def query(self,sql,kwargs = None):
#创建查询方法
try:
cursor = self.execute(sql,kwargs)
if cursor:
# 返回查询到的所有内容
return cursor.fetchall()
else:
raise Exception(f'sql error:{sql}')
except Exception as e:
self.log.error(e)
raise e
finally:
#关闭游标
cursor.close()
def insert(self,sql,kwargs = None):
#数据插入
try:
cursor = self.execute(sql,kwargs)
if cursor:
#获取最后行的id
row_id = cursor.lastrowid
return row_id
else:
raise Exception(f'sql error:{e}')
except Exception as e:
self.log.error(e)
raise e
finally:
cursor.close()
def escape_string(self,_):
#对数据文件的内容进行转码,防止有一些特殊字符等
return pymysql.escape_string(_)
db = MySQL(user='root',password='123456',db='papers')
这里用到的是
pymysql
这个库,不会使用的,看小鱼这篇文章
《Python3链接Mysql数据库》
3. 数据存储
我们把爬取的数据,存储到数据库中。
同样,直接上代码
csv_to_mysql.py
# -*- coding: utf-8 -*-
"""
@ auth : carl_DJ
@ time : 2020-8-26
"""
import csv
import time
from PaperWeb.libs.mysql import db
def get_csv_info(path = 'paper.csv')
#打开csv文件
csvfile = open(path,'r')
reader = csv.reader(csvfile)
for item in reader:
yield item
def get_insert_sql():
#把数据插入到数据库
items = []
#获取时间
_time = int(time.time())
for item in get_csv_info():
#对csv文件中的字符进行转码
item = [db.escape_string(_) for _ in item]
#添加到对应的list中,创建数据库时列表字段
items.append(f"('{item[0]}',{item[1]},{item[2]},{_time},{_time})")
#获取values值
values = ','.join(items)
#执行sql 语句的插入
sql = f'''
INSERT INTO
Paper ('title','url','authors','create_time','updata_time')
Values
{values}
'''
row_id = db.insert(sql)
print(f'{row_id}条数据插入完成')
执行完之后,则就可以去数据库,看结果!
要是不完美,小鱼觉得那是不可能的~
要是完美,也不枉费小鱼肝到十二点的成果!
录完课 ,做总结,
喝点咖啡,溜溜娃,
娃睡了,我也开始肝代码。
4. 彩蛋
这个网站搭建完成,小鱼接下来的目标有两个:
1.会写一些
python数据分析的博文;
2.小鱼分享 自己
四面阿里,终拿offer的经历及面试题
。
哈哈,这提前剧透了~
为啥又要写 阿里面试的经历
因为,最近有小伙伴要准备阿里的面试,问了我一些关于阿里面试的问题,与其逐一的说,不如整理出来,share更多人!
这样小鱼我也省下更多的时间,做更多事情!!
好了,最后借用王二的一句话,结束今天的技术分享:
如果不是生活所迫,谁愿意才华一身!