本文为大家详细分析机器学习比赛里交叉验证的几个高阶用法,如果能熟练使用kfold的几个变种用来切分训练集和测试集,在很多比赛中会有惊人的上分效果。
基于kfold主要有三个交叉验证的方法:
1. KFold
2. StratifiedKFold
3. GroupKFold
下面我们用实际的例子和代码来详细解释每个方法的具体用法,并最后提炼出三个方法之间的本质区别和联系:
首先是从sklearn把三种方法引入:
from 我们用最常用的5折KFold为例:
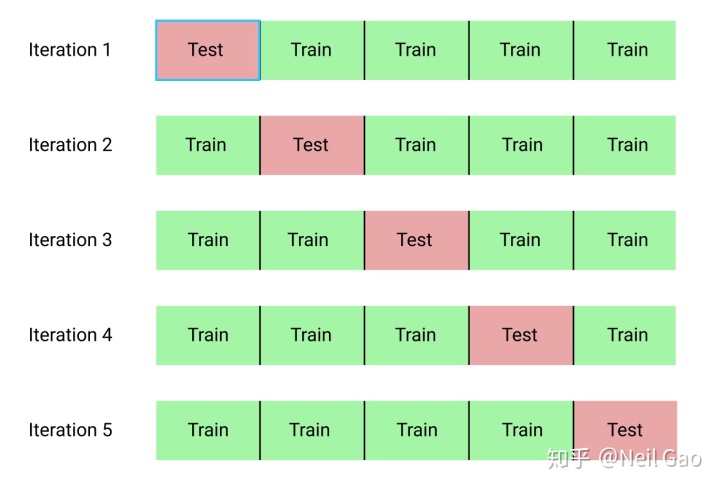
KFold的目的就是通过多次切分,同一个模型可以训练多次,可以有效地防止单次的切分可能导致的训练集和测试集分布差异过大,
5折KFold本质上就是把数据集平均切成5份,然后每次选取其中1份作为测试集,剩下的4份作为训练集来构造模型,重复切5次,每次选取的1/5测试集都不一样,如上图所示,最后同一个模型在5次切分上各训练一次,预测结果也会取5次的平均值,可以有效地提高模型的鲁棒性,防止模型在过拟合到某一次的切分的训练集的数据上。
以下是KFold代码:
X = np.array([[1,], [2,], [3,], [4,], [5, ], [6, ], [7, ]])
y = np.array([1, 1, 1, 2, 1, 2, 1])
kf = KFold(n_splits=5, random_state=2020, shuffle=False)
for i, (train_index, test_index) in enumerate(kf.split(X)):
print(f'KFold {i+1}:')
print("Train index:", train_index, "Test index:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print("Train y:", y_train, "Test y:", y_test)
# 输出结果
KFold 1:
Train index: [2 3 4 5 6] Test index: [0 1]
Train y: [1 2 1 2 1] Test y: [1 1]
KFold 2:
Train index: [0 1 4 5 6] Test index: [2 3]
Train y: [1 1 1 2 1] Test y: [1 2]
KFold 3:
Train index: [0 1 2 3 5 6] Test index: [4]
Train y: [1 1 1 2 2 1] Test y: [1]
KFold 4:
Train index: [0 1 2 3 4 6] Test index: [5]
Train y: [1 1 1 2 1 1] Test y: [2]
KFold 5:
Train index: [0 1 2 3 4 5] Test index: [6]
Train y: [1 1 1 2 1 2] Test y: [1]一般我们会设置KFold的参数random_state为某一个整数,这样可以保证代码可以复现,否则每次运行上面的代码,切分出来的结果都是不一样的。
注意到KFold是均匀切分数据集的,
而通常的数据集里,预测目标的分布可能是不平均的,甚至是非常倾斜的,比如在反欺诈的数据中,正样本的数量会比负样本多一个量级,当然我们可以对正样本做部分采样,也可以对负样本做数据增强,但是这样会损失掉一些样本,
而StratifiedKFold就是为了解决正负样本分布不均的切分问题的(多标签样本同样适用),
StraitifiedKFold(分层)会根据预测目标里各个样本的分布比例来切分样本,
使得切分后的训练集和测试集里的各个样本的比例都尽可能和全样本相同。
X = np.array([[1,], [2,], [3,], [4,], [5, ], [6, ], [7, ]])
y = np.array([1, 1, 1, 2, 1, 2, 1])
kf = StratifiedKFold(n_splits=5, random_state=2020, shuffle=False)
for i, (train_index, test_index) in enumerate(kf.split(X, y)):
print(f'StratifiedKFold {i+1}:')
print("Train index:", train_index, "Test index:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print("Train y:", y_train, "Test y:", y_test)
#输出结果
StratifiedKFold 1:
Train index: [1 2 4 5 6] Test index: [0 3]
Train y: [1 1 1 2 1] Test y: [1 2]
StratifiedKFold 2:
Train index: [0 2 3 4 6] Test index: [1 5]
Train y: [1 1 2 1 1] Test y: [1 2]
StratifiedKFold 3:
Train index: [0 1 3 4 5 6] Test index: [2]
Train y: [1 1 2 1 2 1] Test y: [1]
StratifiedKFold 4:
Train index: [0 1 2 3 5 6] Test index: [4]
Train y: [1 1 1 2 2 1] Test y: [1]
StratifiedKFold 5:
Train index: [0 1 2 3 4 5] Test index: [6]
Train y: [1 1 1 2 1 2] Test y: [1]注意由于y中1和2这两个标签的比例是5:2,因此测试集中不会出现只有标签2的情况。
事实上,我们有时候可能不希望某一组或某一类型的样本被切分到训练集和测试集中,而是希望这组数据全部都在训练集中或者全部在测试集中,比如医疗影像数据,我们希望某个病人的完整数据要么全在训练集中,要么全部在测试集中,而GroupKFold就可以实现我们的目标:
X = np.array([[1,], [2,], [3,], [4,], [5, ], [6, ], [7, ]])
y = np.array([1, 1, 1, 2, 1, 2, 1])
groups = np.array([1, 1, 1, 1, 1, 2, 2])
kf = GroupKFold(n_splits=2)
for i, (train_index, test_index) in enumerate(kf.split(X, y, groups)):
print(f'GroupKFold {i+1}:')
print("Train index:", train_index, "Test index:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print("Train y:", y_train, "Test y:", y_test)
#输出结果
GroupKFold 1:
Train index: [5 6] Test index: [0 1 2 3 4]
Train y: [2 1] Test y: [1 1 1 2 1]
GroupKFold 2:
Train index: [0 1 2 3 4] Test index: [5 6]
Train y: [1 1 1 2 1] Test y: [2 1]注意到第0,1,2,3,4个样本为第一组,第5,6个样本为第二组,这两组数据在切分的时候不会被破坏。
以上就是交叉验证的三个变种的深度解析,如果有任何问题,欢迎留言讨论。