文章目录
快速且通用的集群计算系统——Spark
Spark是一个统一的、用于大数据分析处理的、快速且通用的集群计算系统。它开创了不以MapReduce为执行引擎的数据处理框架,提供了Scala、Java、Python和R这4种语言的高级API,以及支持常规执行图的优化引擎。
Spark基础知识
Spark还支持包括用于离线计算的Spark Core、用于结构化数据处理的Spark SQL、用于机器学习的MLlib、用于图形处理的GraphX和进行实时流处理的Spark Streaming等高级组件,它在项目中通常用于迭代算法和交互式分析。
Spark的特点
Spark在性能和通用性上都有显著优势,它是基于内存计算的并行计算框架,这使它的数据处理速度更快,具有高容错性和高可伸缩性。同时Spark可以运行在YARN 上,无缝集成Hadoop组件,在已有Hadoop集群上使用Spark。
-
数据处理快。
- Spark是基于内存的计算框架,数据处理时将中间数据集放到内存中,减少了磁盘I/O,提升了性能。
-
通用性强
- 提供了MLlib、GraphX、Spark Streaming和Spark SQL等多个出色的分析组件,涵盖了机器学习、图形算法、流式计算、SQL查询和迭代计算等多种功能,组件间无缝、紧密地集成,一站式解决工作流中的问题。
-
适应性好
- Spark具有很强的适应性,能够与Hadoop紧密继承,支持Hadoop的文件格式,如以HDFS为持久层进行数据读写,能以YARN作为资源调度器在其上运行,成功实现Spark应用程序的计算。
-
易于使用,用户体验高
- Spark提供了Scala、Java、Python和R这4种语言的高级API和丰富的内置库,使更多的开发人员能在熟悉的编程语言环境中工作,用简介的代码进行复杂的数据处理。而且Scala和Python语言的REPL(read—eval—print—loop)交互模式使其应用更加灵活。
Spark和Hadoop的比较
Spark和大多数的数据处理框架不同,它并没有利用MapReduce作为计算框架,而是使用自己的分布式集群环境进行并行化计算。它最突出的特点是执行多个计算时,能将作业之间的数据集缓存在跨集群的内存中,因此利用Spark对数据集做的任何计算都会非常快,在实际项目中的大规模作业能大大节约时间。
Spark在内存中存储工作数据集的特点使它的性能超过了MapReduce工作流,完美切合了迭代算法的应用要求,这与MapReduce每次迭代都生成一个 MapReduce运行作业,迭代结果在磁盘中写入、读取不同;Spark程序的迭代过程中,上一次迭代的结果被缓存在内存中,作为下一次迭代的输入内容,极大地提高了运行效率。
Spark和 MapReduce的相同点和不同点如下:
- Spark是基于MapReduce的思想而诞生,二者同为分布式并行计算框架。
- MapReduce进行的是离线数据分析处理,Spark主要进行实时流式数据的分析处理。
- 在数据处理中,MapReduce将 Map结果写入磁盘中,影响整体数据处理速度;Spark的DAG执行引擎,充分利用内存,减少磁盘1O,迭代运算效率高。
- MapReduce只提供了Map和Reduce两种操作;Spark有丰富的API,提供了多种数据集操作类型(如Transformation操作中的map、filter、 groupBy、join,以及 Action操作中的count和 collect等)。
Spark和 MapReduce相比其内存消耗较大,因此在大规模数据集离线计算、时效要求不高的项目中,应优先考虑MapReduce,而在进行数据的在线处理、实时数据计算时,更倾向于选择Spark。
弹性分布式数据集RDD
在实际数据挖掘项目中,通常会在不同计算阶段之间重复用中间数据结果,即上一阶段的输出结果会作为下一阶段的输入,如多种迭代算法和交互式数据挖掘工具的应用等。MapReduce框架将Map后的中间结果写入磁盘,大量磁盘I/O拖慢了整体的数据处理速度。RDD (Resilient Distributed Dataset)的出现弥补了MapReduce的缺点,很好地满足了基于统一的抽象将结果保存在内存中的需求。Spark建立在统一的抽象RDD上,这使Spark的各个组件得以紧密集成,完成数据计算任务。
RDD的概念
分布式数据集RDD是Spark最核心的概念,它是在分布式集群节点中跨多个分区存储的一个只读的元素集合,是Spark中最基本的数据抽象。每个RDD可以分为多个分区,每个分区都是一个数据集片段,同一个RDD不同分区可以保存在集群中不同的节点上,即RDD是不可变的、可分区的、里面数据可并行计算的、包含多个算子的集合。
RDD提供了一种抽象的数据架构,根据业务逻辑将现有RDD通过转换操作生成新的RDD,这一系列不同的RDD互相依赖实现了管道化,采用惰性调用的方式避免了多次转换过程中的数据同步等待,且中间数据无须保存,直接通过管道从上易操作流入下一操作,减少了数据复制和磁盘I/O。
RDD的创建方式
RDD共有以下3种创建方式:
- 使用外部存储系统的数据集(如HDFS等文件系统支持的数据集)。
- 通过Scala集合或数组以并行化的方式创建RDD。
- 对现有RDD进行转换来创建RDD。
RDD的操作
RDD有转换(Transformation)和动作(Action)两大类操作,转换是加载一个或多个RDD,从当前的RDD转换生成新的目标RDD,转换是惰性的,它不会立即触发任何数据处理的操作,有延迟加载的特点,主要标记读取位置、要做的操作,但不会真正采取实际行动,而是指定RDD之间的相互依赖关系;动作则是指对目标RDD执行某个动作,触发RDD的计算并对计算结果进行操作(返回给用户或保存在外部存储器中)。
通常我们操作的返回类型判断是转换还是动作:转换操作包括map,filter、groupBy,join等,接收RDD后返回RDD类型;行动操作包括count、collect等,接收RDD后返回非 RDD,即输出一个值或结果。
RDD的执行过程
RDD的执行过程主要包括RDD的创建、转换和计算三部分。
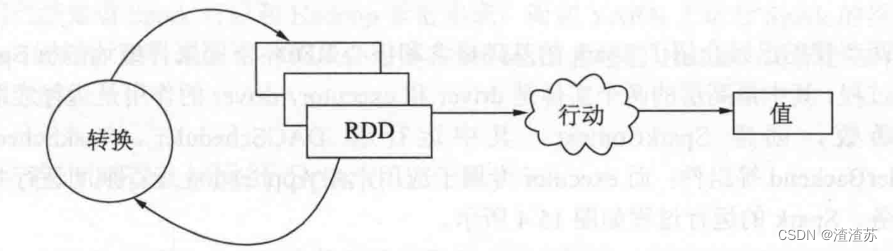
RDD的详细执行流程如下:
(1)使用外部存储系统的数据集创建RDD。
(2)根据业务逻辑,将现有RDD通过一系列转换操作生成新的RDD,每一次产生不同的RDD传给下一个转换操作,在行动操作真正计算前,记录下RDD的生成轨迹和相互之间的依赖关系。
(3)最后一个RDD由行动操作触发真正的计算,并将计算结果输出到外部数据源(返回给用户或保存在外部存储器中)。
通过一个示例详细讲解RDD的工作流程
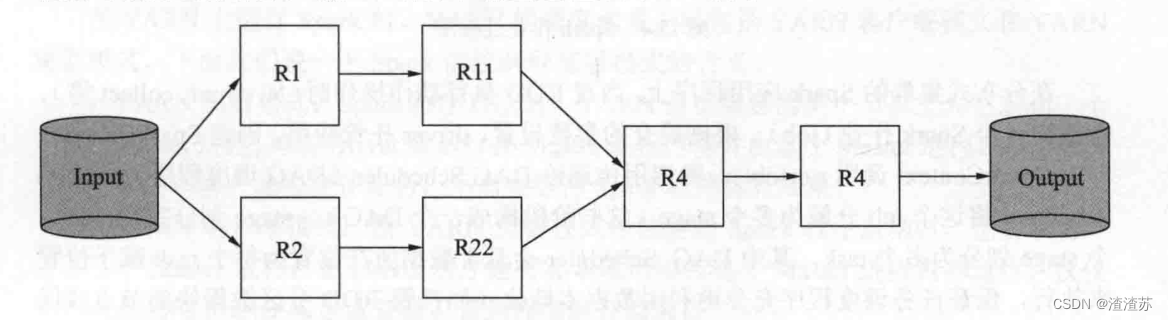
从外部存储系统的数据集输入数据Data,创建R1和R2两个RDD,经过多次的转换操作后生成了一个新的RDD,即 R4,此过程中计算一直没有发生,但RDD标记了读取位置、要做的操作,Spark只是记录了RDD间的生成轨迹和相互依赖关系,最后一个RDD即R4的动作操作触发计算时,Spark才会根据RDD之间的依赖关系生成有向无环图DAG,DAG 描述了RDD 的依赖关系,也称为“血缘关系(Lineage)”。在一系列的转换和计算结束后,计算结果会输出到外部数据源上。
Spark作业运行机制
Spark作业运行的过程,其中最高层的两个实体是driver 和 executor,driver的作用是运行应用程序的main()函数,创建SparkContext,其中运行着 DAGScheduler 、TaskSchedule和SchedulerBackend等组件;而executor专属于应用,在Application运行期间运行并执行应用的任务。
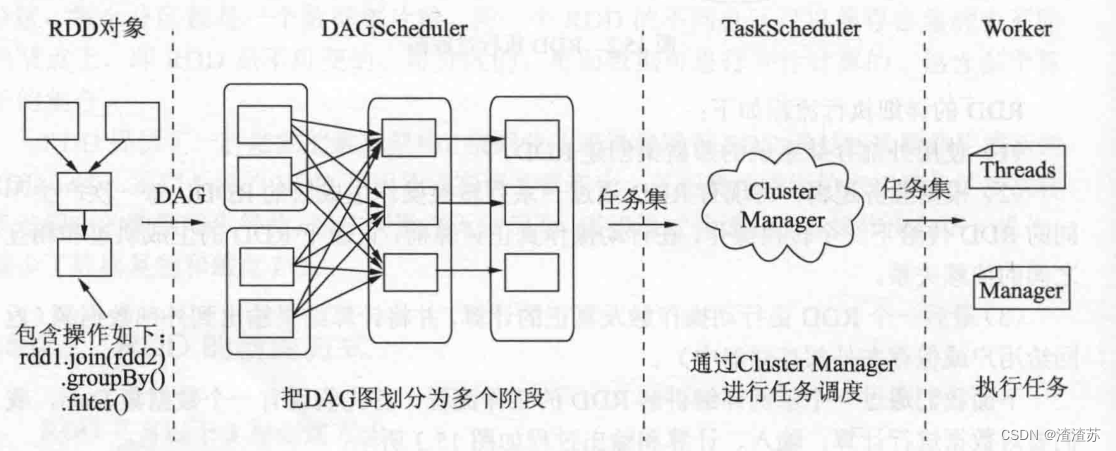
在分布式集群的Spark应用程序上,当对RDD执行动作操作时(如 count、collect等),会提交一个Spark作业(job),根据提交的参数设置,driver 托官应用,创建SparkContext,即对SparkContext调用runJob(),将调用传递给DAG Scheduler (DAU 调度在)。LAdScheduler将这个job分解为多个stage(这些阶段构成一个DAG), stage划分完后,将每个stage划分为多个task,其中 DAG Scheduler会基于数据所在位置为每个task赋予位置来执行,保证任务调度程序充分地利用数据本地化(如托管RDD分区数据块的节点或保存RDD分区的executor)。DAG Scheduler将这个任务集合传给Task Scheduler,在任务集合发送到Task Scheduler之后,Task Scheduler 基于task位置考虑的同时构建由Task到Executor的映射,将Task按指定的调度策略分发到 Executor中执行。在这个调度的过程中,SchedulerBackend负责提供可用资源,分别对接不同的资源管理系统;无论任务完成或失败,Executor都向 Driver 发送消息,如果任务失败则Task Scheduler将任务重新分配在另一个Executor上,在 Executor完成运行任务后会继续分配其他任务,直到任务集合全部完成。
运行在YARN上的Spark
Spark可以和 Hadoop 紧密集成,而在 YARN上运行Spark的模式恰好提供了与Hadoop组件最紧密的集成,它是在我们已部署好的 Hadoop集群上应用Spark.最简便的方法。
在YARN上运行Spark
在Spark的独立模式中,因为是单独部署到一个集群中,不依赖其他资源管理系统,集群资源调度是 Master 节点负责,只能支持简单的固定资源分配策略,即每个任务固定核数量,每个作业按顺序依次分配资源,资源不够时排队等待,因此通常会遇到一些用户分配不到资源的问题。此时 Spark就可以将资源调度交给YARN负责,YARN支持动态资源调度,因此能很好地解决这个问题。
我们知道YARN是一个资源调度管理系统,它不仅能为Spark 提供调度服务,还能为其他子系统(如 Hadoop、MapReduce和 Hive等)服务,由YARN来统一为分布式集群上的计算任务分配资源,提供资源调度,从而有效地避免了资源分配的混乱无序。
Spark在YARN上的两种部署模式
在 YARN上运行Spark 时,YARN 的调度模式主要包括YARN客户端模式和YARN集群模式,下面我们说一下 Spark的这两种部署模式的含义。
- YARN集群模式:Spark程序启动时,YARN 会在集群的某个节点上为它启动一个Master进程,然后 Driver 会运行在Master进程内部并由这个 Master进程启动Driver程序,客户端提交作业后,不需要等待 Spark程序运行结束。
- YARN客户端模式:跟YARN集群模式相似的是Spark程序启动时,也会启动一个Master 进程,但 Driver程序运行在本地而不在这个 Master进程内部运行,仅仅是利用Master来申请资源,直到程序运行结束。
上面我们介绍了Spark的两种部署模式的含义,下面说一下二者的区别。
Spark程序在运行时,在YARN集群模式下,Driver进程在集群中的某个节点上运行,基本不占用本地资源。这种模式适合生产环境的运行方式。
而在YARN客户端模式下,Driver运行在本地,对本地资源会造成一些压力,但它的优点是Spark程序在运行过程中可以进行交互,这种模式适合需要交互的计算。
因此,建议具有任何交互式组件的程序都使用 YARN客户端模式,同时,客户端模式因为任何调试输出都是立即可见的,因此构建Spark程序时非常有价值;当用于生成作业时,建议使用YARN集群模式,此时整个应用都在集群上运行,更易于保留日志文件以备检查。
Spark集群安装
Spark安装包的下载
https://spark.apache.org/downloads.html
https://www.apache.org/dyn/closer.lua/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz
Spark安装环境
因为我们搭建的是Spark完全分布式集群,在上传并安装Spark安装包前,首先要确认以下4点:
(1)一台Master和两台Slave,并已实现SSH免密码登录,使我们启动Spark时 Master能通过SSH启动远端 Worker 。
(2)安装配置好JDK(这里我使用的是 jdk1.8.0_60)。
(3) Hadoop 分布式集群已搭建完成(启动Spark前要先启动HDFS和YARN)
(4) Scala已安装并配置好。
因为Spark的运行需要 Java和Scala的支持,因此首先需要配置Java.Scala运行环境,同时为了实现 Spark和 Hadoop的集成,需要基于Hadoop分布式集群进行 Spark 的集群部署。最后,因为Spark 的 Master和 Worker 需要通过SSH进行通信,并利用SSH启动远端Worker,因此必须实现 Master和 Slave的SSH免密码登录。
Scala安装和配置
Spark的运行需要Scala的支持,Scala语法简洁,同时支持Spark-Shell,更易于原型设计和交互。
https://github.com/lampepfl/dotty/releases/download/3.1.3/scala3-3.1.3.tar.gz
# 1. 解压
tar -zxvf scala3-3.1.3.tar.gz -C /usr/local
# 2. 重命名
mv scala3-3.1.3/ scala
# 3. 配置环境变量
vim /etc/profile
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH
# 4. 验证
scala -version
Spark分布式集群配置
# 1.解压
tar -zxvf spark-3.3.0-bin-hadoop3.tgz -C /usr/local
# 2.
mv spark-3.3.0-bin-hadoop3/ spark
# 3. 配置环境变量
vim /etc/profile
export SPARK_HOME=/usr/local/spark
export PATH=$SPARK_HOME/bin:$PATH
# 4. 进入conf目录
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=2
# 5. slaves修改,在新版本中叫workers
cp workers.template workers
vim workers
# localhost 注释掉
master
node1
node2
# 6. 启动
进入spark目录下
cd /usr/local/spark
sbin/shart-all.sh
# 检查
jps
## Master节点
2069 NameNode
2215 DataNode
2777 NodeManager
2634 ResourceManager
3917 Jps
## node节点
2165 DataNode
2329 NodeManager
2493 Jps
2238 SecondaryNameNode