点击上方”蓝字”
关注我们,享更多干货!
GaussDB的分布式架构充分运用了每个节点的计算资源,且随着节点规模的扩大其整体性能也呈线性增长。为了实现分布式架构下性能和资源的最大化利用,GaussDB提供了三种分布式执行计划,分别为FQS(Fast Query Shipping)计划、Stream计划以及Remote-Query计划,其中FQS和Stream是可以下推的计划。也就是说,集群中的所有DN都参与了SQL执行。
显然这两种执行计划可以实现节点资源的充分利用,二者之间的区别在于FQS计划是CN直接将原语句下发到各个或者部分DN上,各DN单独执行,相互之间没有数据交互,而Stream计划是原语句在CN上生成执行计划,然后CN将执行计划下发到各个DN上,各DN在执行过程中使用Stream算子进行数据交互。
至于Remote-Query计划,是一种折中的方案,语句在无法生成前两种执行计划的情况下,CN生成计划后,将部分原语句下发到DN,各DN单独执行,执行后将结果发送给CN,CN执行剩余计划。这种计划执行性能一般较差,使用较少。
对于分布式数据库而言,往往意味着应用场景多样化、数据规模庞大(PB级)、作业逻辑复杂及语句耗时较长等特征,尤其是针对金融行业,其大数据量及复杂作业决定了生产环境中Stream计划的广泛运用。
GaussDB在Postgres-XC的基础上新增了三个Stream算子:gather、redistribute和broadcast。正是基于Stream算子的合理运用,在分布式架构下大规模数据的处理才成为可能,但解决问题的手段往往也会产生新的问题,因此针对Stream算子的优化也成为GaussDB中SQL优化的重要部分。

实例:Stream计划的产生及效用的发挥
假设有两张表t1和t2,t1的分布列为a,t2的分布列也为a,我们用t1.a=t2.b对两张表进行关联查询:
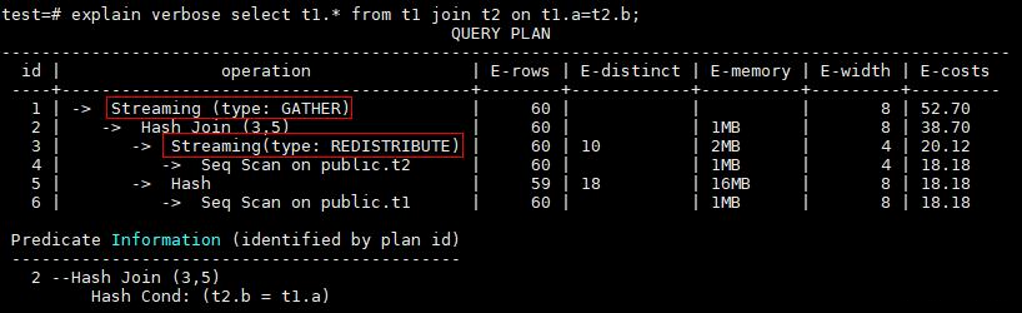
由于t1.a是分布列,t2.b不是分布列,因此为了能够与t1.a进行关联,表t2会根据字段b在所有DN上进行重分布,关联后的结果会在CN进行收集汇总(GATHER)。当然,如果关联条件是t1.a=t2.a,由于关联字段均为分布列,这种情况则不会涉及到Stream算子,在每个DN上两表直接关联即可。此时,优化器很可能会选择使用FQS计划,即CN将原语句直接下推到各个DN上执行。
针对两表关联的场景,根据关联字段是否为表的分布列,分别有以下几种可能的执行路径(t1.a和t2.a为表的分布列):

其中对于redistribute和broadcast的选择主要是根据cost代价评估来选择。大致来说,大表join小表的场景,小表倾向做broadcast,大表倾向做redistribute,这样能够最小化DN间通信交互的数据量,减少通信交互的开销。如果关联的两张表数据量较大且相差不多,此时优化器会倾向于选择redistribute,因为相比于大数据量做broadcast,redistribute带来的性能影响更低。
除了关联字段为非分布列时会出现redistribute,当查询中使用了group by或者over(partition by )窗口函数时,如果分组字段不是表的分布列,同样会产生redistribute。数据在节点间进行重分布时,必然要消耗大量的网络带宽,这是造成SQL性能低下的重要原因,但是通过大量的实践,我们发现重分布时造成的数据倾斜才是性能下降的主要因素。事实上,如果重分布的字段每个值的出现频率比较接近或者无重复值,对于这种理想情况来说,即便是上百亿数据量的redistribute,也不会对整体性能造成太大影响,而且集群规模越大,每个节点分摊的计算量就越小。相反,如果重分布的字段的值有明显的倾斜,就会导致大量数据集中在某个或者某几个节点,这样就会导致产生单点瓶颈,更严重的甚至会导致发往该节点的数据量超出内存大小而不得不下盘到临时文件,这对SQL性能来说影响较大。
Broadcast广播算子是将某个DN上的数据发送到所有DN上,或者是所有DN上的数据发送到某一个DN上。第一种情况较为常见,往往出现在两表或者多表关联的场景中。优化器通过估算cost代价,选择将数据量较小的表进行广播,与之关联的大表则避免了重分布,在一定程度上避免了数据倾斜带来的影响,当然对于表自身的数据倾斜问题,不论是否涉及到Stream算子,均无法避免。第二种情况一般是SQL语句中使用了row_number() over(order by XXX)窗口函数进行排序,而未使用分组字段,或者row_number() over(partition by 1 order by XXX)分组字段为数字,这样所有DN上参与排序的数据均会发送到一个指定的DN上,类似于gather收集汇总数据。另外,如果SQL语句中使用了limit,在数据量较大的情况下limit下推,也会产生broadcast,作为第二次limit的结果汇总。如下图所示:
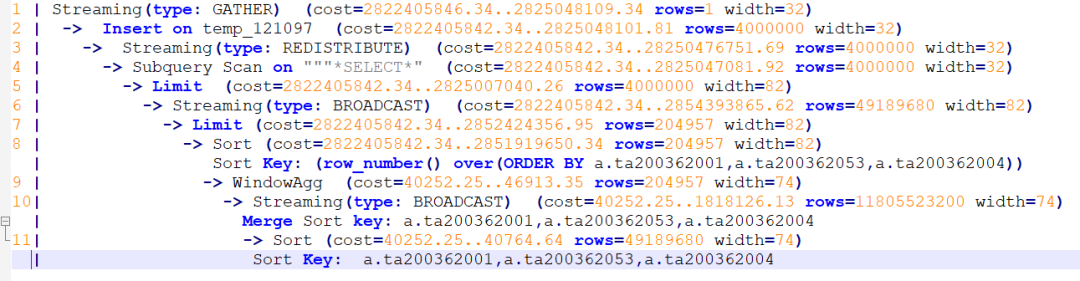
Stream算子实现了在各个节点间的数据交互,发挥了分布式架构的作用,为复杂查询提供了大规模并行处理的路径。然而在实际应用中,由于统计信息不准确、查询条件异常、隐式转换、null值、语法错误、逻辑错误等原因,会造成优化器生成错误的执行计划。比如,小表或数据量较小的子查询未广播、大表或者数据量较大的子查询广播。当执行计划中出现这种异常情况时,就需要使用各种方法进行优化,使执行计划趋于合理路径。针对Stream计划,主要就是以减少Stream传输数据量、降低通信消耗为基本原则。
Stream计划常用优化方法

(1) 对于高版本可以使用hint调整关联表的顺序、关联方式以及指定行数;
(2) 对于无法使用hint的版本,可以通过改写SQL语句的方式调整关联顺序或者关联方式。
(3) 对于小表或者数据量较小的子查询未广播的情况,可将小表或者子查询改写为临时复制表。
(4) 对于大表或者数据量较大的子查询广播的情况,可在表或者子查询中增加group by、distinct语法,或者在关联条件中增加一个关联字段,或者将其改写为临时表,强制其走重分布。
(5) 如果语句中使用了row_number() over(order by XXX),可以在窗口函数中添加一个无重复值的字段作为分组字段;如果使用了row_number() over(partition by 1 order by XXX),由于此时数字会被当做常量,而非字段,因此将数据改为具体字段即可。
(6) 对于重分布带来的数据倾斜,可以将倾斜部分与非倾斜部分分开执行,然后通过union all进行结果合并。
(7) GaussDB中自定义函数调用性能较低,如果出现过多的函数调用导致性能下降的情况,可以将函数部分单独计算,然后与主表关联。
(8) 对于执行计划不准确的子查询,可将其结果写入独立的临时表,避免其对整体执行计划的影响。
(9) 在确保没有null值时,可以通过将not in转换为not exists,通过生成hash join来提升查询效率。
(10) 如果GROUP BY语句生成了groupagg+sort的执行计划,性能会比较差,可以通过加大work_mem的方法生成hashagg的执行计划,因为不用排序而提高性能。
墨天轮原文链接:https://www.modb.pro/db
/72658(
复制链接至浏览器或点击文末阅读原文查看)
END
推荐阅读:
267页!2020年度数据库技术年刊
推荐下载:
2020数据技术嘉年华PPT下载
2020数据技术嘉年华近50个PPT下载、视频回放已上传墨天轮平台,可在“
数据和云
”公众号回复关键词“
2020DTC
”获得!
你知道吗?我们的视频号里已经发布了很多精彩的内容,快去看看吧!↓↓↓
点击下图查看更多 ↓



云和恩墨大讲堂 |
一个分享交流的地方
长按,识别二维码,加入
万人
交流社群
请备注:云和恩墨大讲堂
点个“在看”
你的喜欢会被看到❤