目录
目标
- 了解kafka顺序读写机制;
- 了解零拷贝机制;
- 了解kafka批量发送消息和批量消费消息的实现;
- 熟悉kafka日志文件和索引文件的设计;
- 通过剖析上述概念,熟练回答标题所述的面试题。
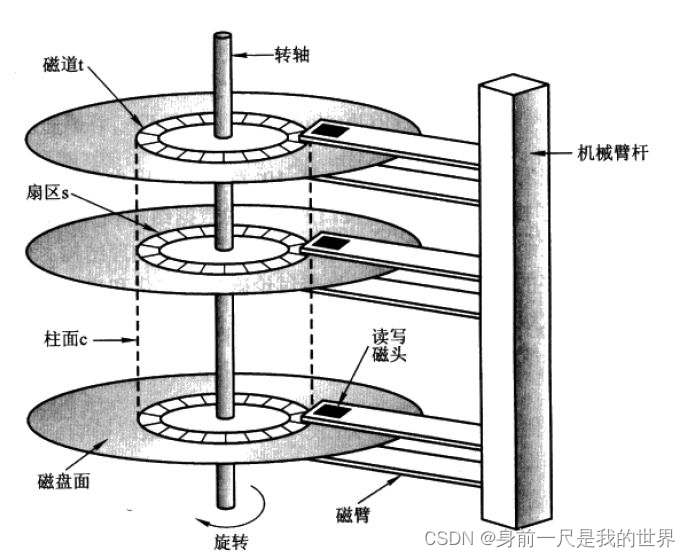
顺序读写机制
消息顺序写入磁盘,且消息写入磁盘后并没有对这些消息进行各种操作(比如不像MySQL一样操作数据),所以消息在磁道中连续存在。磁盘在预读时从起始地址后连续读取多个页面,大大减少了磁头的移动和转轴的旋转,从而降低了寻址的时间,顺序读写的时间主要消耗在数据的传输过程中。
与之相对的是随机读写,数据没有连续存储,为了读取数据,磁头必须要在各个位置来回移动,转轴旋转也会增多,寻址时间大大增加。
综上所述,顺序读写机制的寻址效率远远高于随机读写机制。

零拷贝机制
百度百科释义
零复制
(英语:
Zero-copy
;也译
零拷贝
)技术是指
计算机
执行操作时,
CPU
不需要先将数据从某处
内存
复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
传统数据复制方式
- 从磁盘中读取文件到内核读取缓冲区;
- 内核读取缓冲区的数据复制到用户缓冲区;
- 用户缓冲区的数据复制到socket缓冲区;
- socket缓冲区的数据发送到网卡;
- 消费者获取到数据。
kafka数据复制方式
- 从磁盘中读取文件到内核读取缓冲区;
- 内核读取缓冲区的数据发送到网卡;
- 消费者获取到数据。
注意
- 零拷贝是操作系统实现的功能,kafka利用了操作系统这一特性,零拷贝非kafka独有的特性;
- kafka之所以可以使用零拷贝技术是因为kafka只做数据传递,并不会改变数据。而应用程序读取到数据后可能还要放到内存中进行处理,所以不能使用零拷贝技术。

kafka批量收发消息
kafka提供了很多参数配置,其中就有生产者批量发送消息和消费者批量拉取消息的参数。
kafka官方API
![]()
https://kafka.apache.org/documentation/
kafka日志文件和索引文件的设计
相关术语
Broker
kafka节点,多个broker组成kafka集群。
Topic
即主题,kafka通过Topic对消息进行分类,发布到kafka的消息都需要指定Topic。Topic只是一个逻辑概念。
Producer
即消息生产者,向Broker发送消息的客户端。
Consumer
即消息消费者,从Broker消费消息的客户端。
ConsumerGroup
即消费者组,消费者隶属于消费者组,同一个分区的消息可以被多个消费者消费,但是同一个消费者组中只能有一个消费者可以消费。
Partition
即分区,每个Topic下都至少有一个分区,分区内部的消息是有序的。
kafka日志文件存储设计
日志存储位置
server.properties
文件中
log.dirs
属性设定了所有分区内的数据位置。主题下有分区,每个分区的数据放在单独的文件夹内,文件夹命名方式为
主题-分区
。
日志类型
-
数据日志
,命名示例:00000000000000000000.log、00000000000000204458.log -
偏移量索引日志
,命名示例:00000000000000000000.index、00000000000000204458.index -
时间索引日志
,命名示例:00000000000000000000.timeindex、00000000000000204458.timeindex
偏移量索引日志
kafka每发送4kb数据后就会记录消息的偏移量,把它保存在index文件中。根据分区内消息的有序性。如果需要根据偏移量寻找消息,会先去index文件中,找到相近的偏移量。然后去log文件中,通过对这个偏移量的加减移动操作找到我们需要的偏移量对应的数据。概念图如下:

时间索引日志
kafka每发送4kb数据后就会记录消息的时间戳和与之对应的偏移量,把它们保存在timeindex文件中。根据分区内消息的有序性。如果需要按照时间寻找消息,会先去timeindex文件中,找到与我们需要的时间相近的时间戳所对应的偏移量。然后去log文件中,通过对这个偏移量的加减移动操作来对比我们设定的消费时间,找到我们需要的偏移量对应的数据。概念图和上图类似。
什么是日志分段存储
kafka规定,
每个日志最多存放1G的内容
,达到阈值会再次新建一个文件,文件以文件内最小偏移量命名(因为分区数据有顺序,所以也是当前文件内第一个消息的偏移量。)。如:初始日志是00000000000000000000.log,第204458条数据超过了阈值,于是新建一个文件,文件名称叫00000000000000204458.log。
消费者组对应的偏移量的记录方式
kafka建立了50个主题(默认50个可修改),用来存放每个
消费者组对分区的偏移量
。主题名称
__consumer_offsets
,分区__consumer_offsets-0至__consumer_offsets-49
key=
消费者组+主题+分区号
;value=
偏移量
。
一定要明确一点:同一个组对一个分区,只能有一个消费者消费消息,所以一个分区可以被多个消费者消费,因为这些消费者不在同一个组内。
当消费者挂掉后,就会有组内其他消费者顶替。这也是为什么key是用消费者组而不是用消费者来标记的原因。
消费者组对应的偏移量到底记录在哪个内部主题?计算方式如下:
(对消费者组进行hash运算)% __consumer_offsets主题的分区数