0. 数据:
来自知乎的爬取以及第六次人口普查的数据
1. 前期准备
导入相关库和设置程序运行路径
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
os.chdir(r'C:\Users\86177\Desktop')
print('finished!')
–> 输出的结果为:
finished!
2. 加载数据及查看
add_data1 = pd.read_csv("爬取知乎数据.csv", engine = 'python')
add_data2 = pd.read_csv("六普常住人口数.csv", engine = 'python')
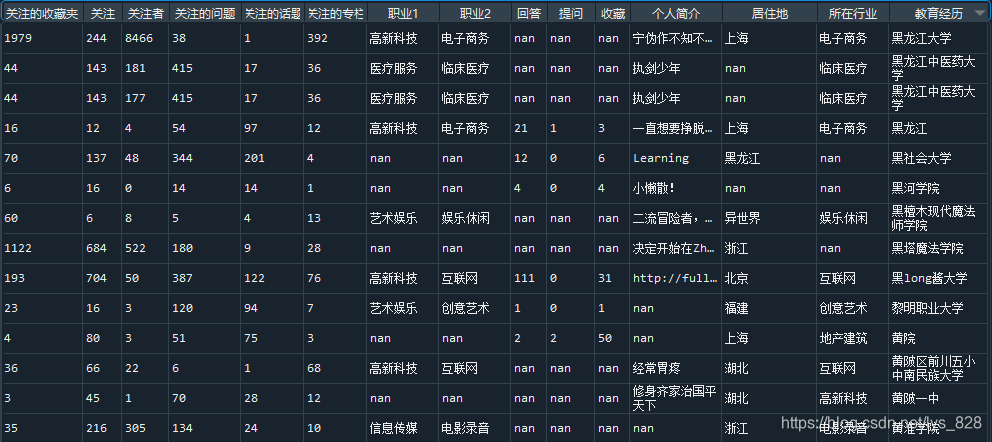
print(add_data1)
–> 输出的结果为:(直截取部分数据,add_data2数据是用来获取省份的)
3. 缺失值处理
从上面的输出中可以看到,缺失值有很多,但是这里分为数字字段的缺失值,和字符串数据的缺失值,比如前面的几个字段都是属于数字字段,后面的存在汉字的字段属于字符串类型的,那么就需要分来处理,直接封装一个函数如下
def Fill_Nan(df):
cols = df.columns
for col in cols:
if df[col].dtype == 'object':
df[col] = df[col].fillna('缺失数据')
else:
df[col] = df[col].fillna(0)
return (df)
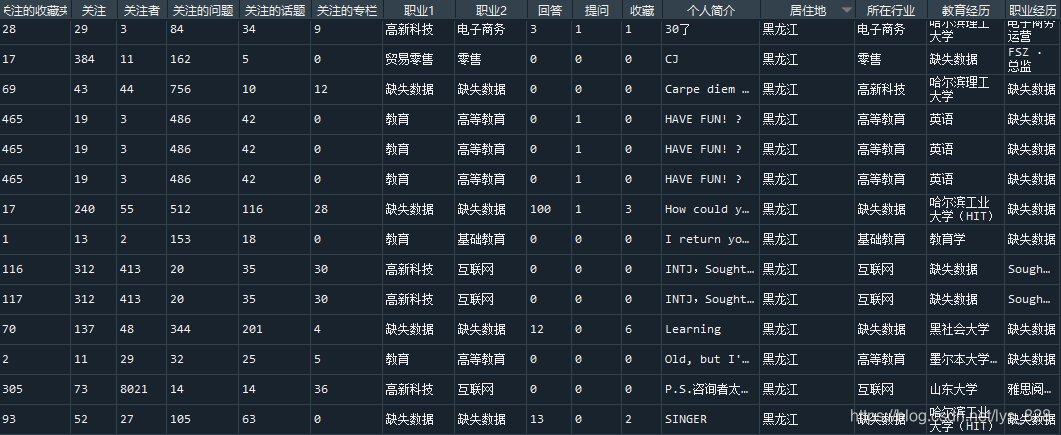
after_data = Fill_Nan(add_data1)
print(after_data)
–> 输出的结果为:(也是截图部分数据)
4. 知友数量和密度
1) 统计一下知友的分布
这里就需要使用add_data2里面的数据了,用来获取省份数据和人口数量,然后和after_data分组后的数据合并后就可以得到知友在全国的分布了
df_city = after_data.groupby('居住地').count()
add_data2['city'] = add_data2['地区'].str[:-1]
data_merge = pd.merge(df_city,add_data2, left_index= True, right_on= 'city')[['_id','city','常住人口']]
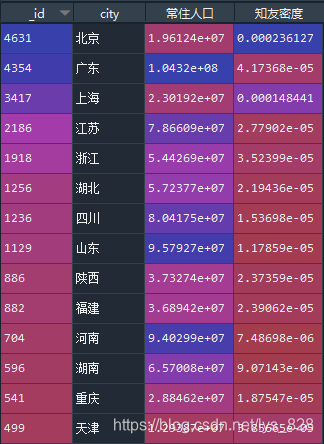
data_merge['知友密度'] = data_merge['_id']/data_merge['常住人口']
–> 输出的结果为:(因为一个id就对应一个账号,所以可以用id字段的数值代替这个省市的知友数量,除以常住人口就是知友密度,下面只截图部分数据)
2) 查找top20的知友数量和知友密度的省份
从上面输出可以发现,知友密度的数量级是不一致的,为了方便对比以及制图,需要采用标准化的方式进行处理数据
def nor_data(df,*cols):
colnames = []
for col in cols:
colname = col + 'nor'
df[colname] = (df[col] - df[col].min())/(df[col].max()- df[col].min())*100
colnames.append(colname)
return(df, colnames)
finial_data, columns = nor_data(data_merge,"_id","知友密度")
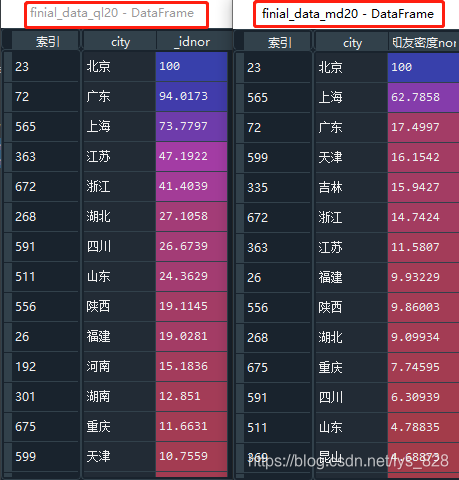
finial_data_ql20 = finial_data.sort_values(columns[0],ascending = False)[['city',columns[0]]][:20]
finial_data_md20 = finial_data.sort_values(columns[1],ascending = False)[['city',columns[1]]][:20]
–> 输出的结果为:(左侧为各省市知友数量,右侧是知友密度,为了可视化数据,下面进行绘制图形展示)
① 知友数量
fig1 = plt.figure(num = 1, figsize=(8,3))
y1 =finial_data_ql20[columns[0]].values
ts = pd.Series(y1,index = finial_data_ql20['city'])
ts.plot(kind = 'bar',
title='知友数量',
ylim = (0,110),
rot = 45,
fontsize = 7,
color = 'r',
style = '--',
)
plt.margins(0.015)
for i, j in zip(range(20), y1):
plt.text(i-0.35,j+1.5, "%.1f" %j, fontsize=8)
plt.savefig("C:/Users/86177/Desktop/1.png",dpi=500,pad_inches=5)
–> 输出的结果为:

② 知友密度
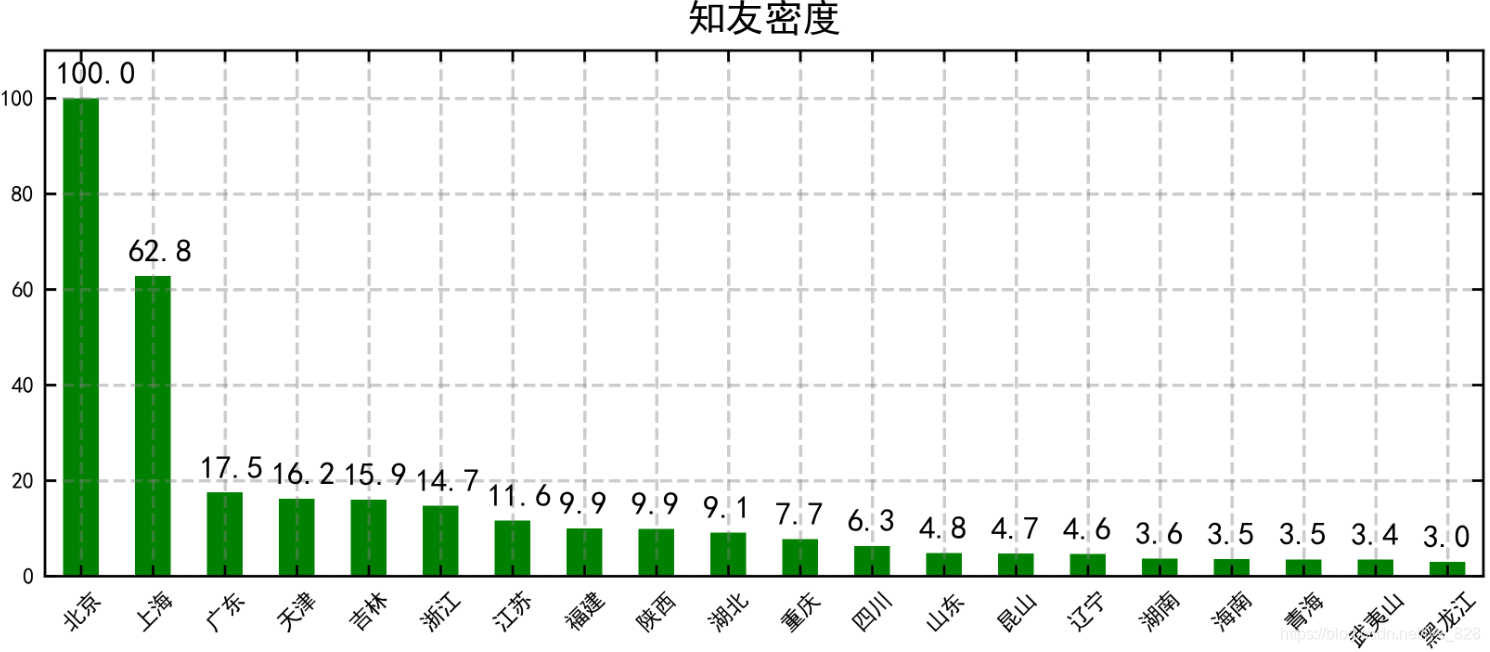
fig2 = plt.figure(num = 2, figsize=(8,3))
y1 = finial_data_md20[columns[1]].values
ts = pd.Series(y1, index = finial_data_md20['city'])
ts.plot(kind = 'bar',
rot = 45,
color = 'g',
fontsize = 7,
ylim = [0,110],
title = '知友密度',)
for i, j in zip(range(20), y1):
plt.text(i-0.35,j+3, "%.1f" %j, fontsize=10)
plt.savefig("C:/Users/86177/Desktop/2.png",dpi=500)
–> 输出的结果为:(可以看出北上广知友人数和密度都是杠杠的)
5. 知友的学历情况
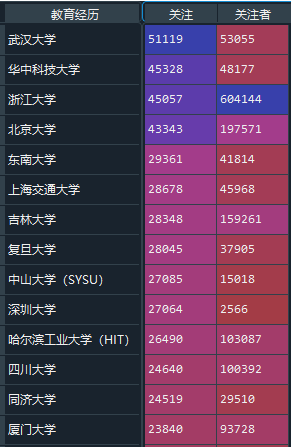
下面代码完成的工作就是,按照’教育经历’字段进行汇总分组,然后在选择添加’关注’,‘关注者’两个字段的数据,接着是删除里面的包含’缺失数据’,‘大学’,’本科’等内容数据,最后按照’关注’字段进行排序并选取前20条数据
df_edu = after_data.groupby("教育经历").sum()[['关注','关注者']].\
drop(['缺失数据','大学','本科',]).\
sort_values("关注",ascending = False)[:20]
–> 输出的结果为:(截取部分数据)
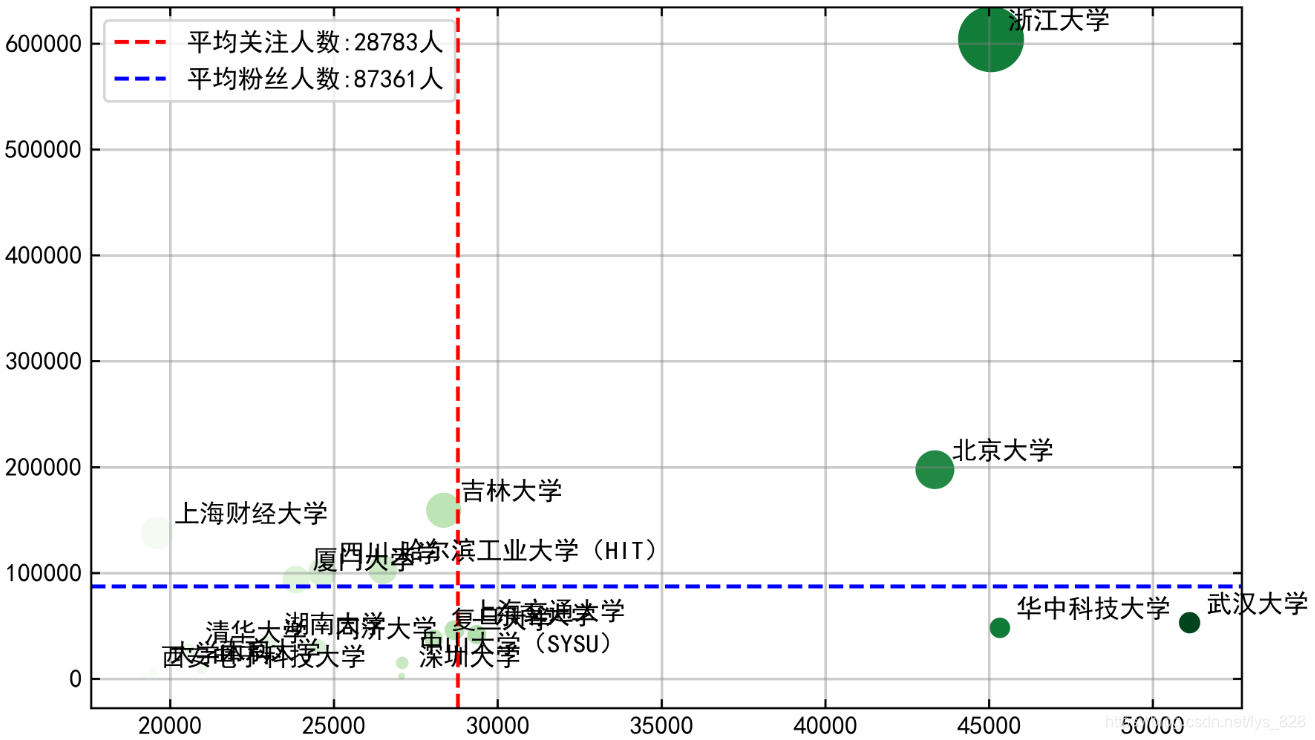
绘制各大高校知友的关注人数和粉丝人数情况散点图
y = df_edu['关注者']
x = df_edu['关注']
follow_u = df_edu['关注'].mean()
fan_u = df_edu['关注者'].mean()
plt.figure(figsize=(8,5))
plt.scatter(x,y,s =y/1000,c=x,cmap = 'Greens')
plt.axvline(follow_u, label = '平均关注人数:{:.0f}人'.format(follow_u), color = 'r', linestyle = '--')
plt.axhline(fan_u, label = '平均粉丝人数:{:.0f}人'.format(fan_u), color = 'b', linestyle = '--')
plt.legend(loc= 'upper left' )
plt.grid(linestyle = "-",color='gray', linewidth=1,alpha = 0.4)
for i,j,n in zip(x,y,df_edu.index):
plt.text(i+500,j+10000,n)
plt.savefig("C:/Users/86177/Desktop/3.png",dpi=500)
–> 输出的结果为:(可以出图中看出浙江大学的知友关注的和被关注的人数都是很多的,武汉大学和华科的知友关注的人数较多,但是粉丝人数却低于平均水平,北京大学的知友则处于这两类之间,剩下的几乎都是在平均值上下左右徘徊)