入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
1、Backbone(主干网络)—— modified aligned Xception改进后的ResNet-101
2、ASPP(Atrous Spatial Pyramid Pooling)
一、deeplab-v3+提出原因与简单介绍
deeplab-v3+是一个语义分割网络,它基于deeplab-v3,添加一个简单有效的Decoder来细化分割结果,尤其是沿着目标对象边界的分割结果,以及采用空间金字塔池模块或编解码结构二合一的方式进行实现。
二、deeplab-v3+网络结构图
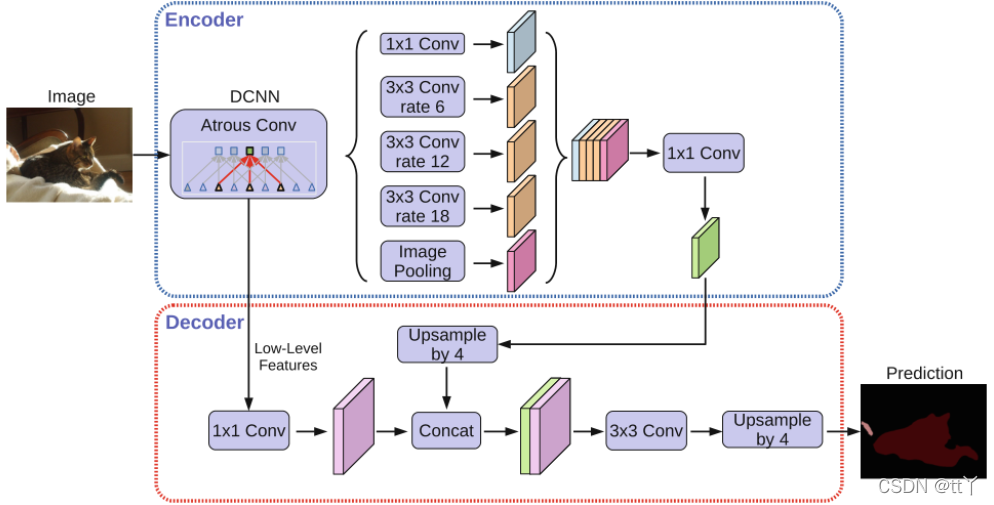
可以看到他是Encoder-Decoder网络结构。接下来我们分成Encoder和Decoder进行解析。
三、Encoder
1、Backbone(主干网络)—— modified aligned Xception改进后的ResNet-101
想了解ResNet的可以康康博主往期文章的介绍
深度学习之Resnet详解|CSDN创作打卡_tt丫的博客-CSDN博客
这里对应的是上面网络结构图中的DCNN(深度卷积神经网络)部分
backbone主要是为了提取特征
改进点:
(1)更深的Xception结构,不同的地方在于不修改entry flow network的结构,这是为了快速计算和有效使用内存
(2)所有的最大池化结构都被stride=2的深度可分离卷积代替
(3)每个3×3的深度卷积后都跟着BN和Relu
2、ASPP(Atrous Spatial Pyramid Pooling)
ASPP是在SPP的基础上,采用了Atrous Convolution(空洞卷积),在上面的网络结构图中对应大括号那一块块
?SPP
如果想了解SPP,可以康康博主往期文章
YOLOv5中的SPP/SPPF结构详解_tt丫的博客-CSDN博客_yolov5中的spp
?Atrous Convolution(空洞卷积)
如果想了解空洞卷积的可以看看博主往期博文
空洞卷积详解_tt丫的博客-CSDN博客
?deeplab-v3+中的ASPP
高级特征经过ASPP的5个不同的操作得到5个不同的输出
5个操作包括1个1×1卷积,3个不同rate的空洞卷积,1个ImagePooling(全局平均池化之后再上采样到原来大小)。卷积可以局部提取特征,ImagePooling可以全局提取特征,这样就得到了多尺度特征
特征融合在这里用concatenate的方法叠加,而不是直接相加
3、Encoder最终输出
我们看网络结构图中Decorder中的“Upsample by 4”和“Concat”可以推出backbone的两个输出:一个是低级特征(low-level feature),这是个output=4x的输出;另一个是高级特征,给ASPP的输入,这是个output=16x的输出
四、Decorder
低级特征经过1×1卷积调整维度(output stride=4x)(论文表明低级特征调整到48 channels时效果最好)
高级特征进行上采样4倍(双线性插值),让output stride从16x变为4x
然后将两个4x特征concatenate,后面接一些3×3卷积(论文表明后面接2个输出channels=256的3×3卷积,输出效果较好),再上采样4倍(双线性插值)得到输出Dense Prediction
欢迎大家在评论区批评指正,谢谢~