导读
本文继续PyTorch学习系列教程,来介绍在深度学习中最为基础也最为关键的数据结构——Tensor。一方面,Tensor之于PyTorch就好比是array之于Numpy或者DataFrame之于Pandas,都是构建了整个框架中最为底层的数据结构;另一方面,Tensor又与普通的数据结构不同,具有一个极为关键的特性——自动求导。今天,本文就来介绍Tensor这一数据结构。

作为Tensor的入门介绍篇,本文主要探讨三大”哲学”问题:何为Tensor?Tensor如何创建?Tensor有哪些特性?
01 何为Tensor
什么是Tensor?Tensor英文原义是张量,在PyTorch官网中对其有如下介绍:

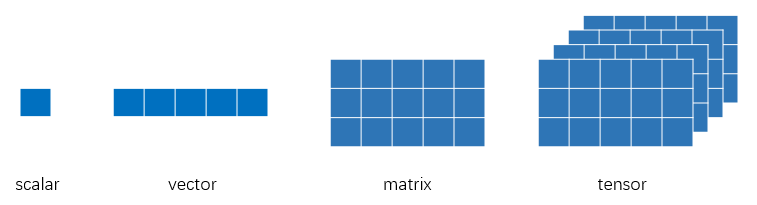
也就说,一个Tensor是一个包含单一数据类型的高维矩阵,简言之Tensor其实和Numpy里的array是一样的。那么,高维矩阵,几维算高维呢(类似于深度学习,多深的网络才算是深度的?)?一般而言,描述Tensor的高维特性通常用三维及以上的矩阵来描述,例如下图所示:单个元素叫标量(scalar),一个序列叫向量(vector),多个序列组成的平面叫矩阵(matrix),多个平面组成的立方体叫张量(tensor)。当然,就像矩阵有一维矩阵和二维矩阵乃至多维矩阵一样,张量也无需严格限制在三维以上才叫张量,在深度学习的范畴内,标量、向量和矩阵都统称为张量。
熟悉机器学习的都知道,有监督机器学习模型的标准输入通常是多个特征列组成的输入矩阵和单个特征列组成的标签向量(多输出时,标签也可以是二维矩阵),用sklearn的约定规范就是训练数据集为(X, y),其中大写X表示特征是一个二维的矩阵,小写y表示标签是一个一维的向量。那么,在深度学习领域中,为何要约定高维数组——Tensor呢?
其实这是出于应用方向的实际需要,以深度学习当前最成熟的两大应用方向莫过于CV和NLP两大领域,前者面向图像和视频,后者面向语音和文本,二者分别以卷积神经网络和循环水神经网络为核心基础模块。而在这两个应用方向中,标准的输入数据集都至少是三维以上,例如:
-
图像数据集至少包含三个维度:N×H×W,即样本数×图像高×图像宽;如果是彩色图像,那么还要增加一个通道C,变为N×C×H×W;如果是视频图像,那么可能还要再增加一个维度T;
-
文本数据集典型的输入包含三个维度:N×L×H,即样本数×序列长度×特征数;
源于这些应用的需要,所以深度学习模型的输入数据结构一般都要3维以上,这也就直接促使了Tensor的出现。更进一步的,Tensor也不是PyTorch特有的定义,而是众多深度学习框架广泛使用的数据结构,例如TensorFlow更是形象的将Tensor加入了框架的命名之中。
小结一下
:PyTorch中的Tensor是深度学习中广泛使用的数据结构,本质上就是一个高维的矩阵,甚至将其理解为NumPy中array的推广和升级也不为过。但由于其支持的一些特殊特性(详见后文第3小节),Tensor在用于支撑深度学习模型和训练时更为便利。
02 如何创建Tensor
前面介绍了何为Tensor,那么接下来就需要了解如何创建Tensor。一般而言,创建一个Tensor大体有三种方式:
-
从已有其他数据结构转化创建为Tensor
-
随机初始化一个Tensor
-
从已保存文件加载一个Tensor
当然,这大概也是一段计算机程序中所能创建数据的三种通用方式了,比如基于NumPy创建一个Array其实大体也是这三种方式。
下面依次予以介绍。
1.从已有其他数据结构转化创建为Tensor
这可能是实际应用中最常用的一种形式,比如从一个列表、从一个NumPy的array中读取数据,而后生成一个新的Tensor。为了实现这一目的,常用的有两种方式:
-
torch.tensor
-
torch.Tensor
没错,二者的区别就是前者用的是tensor函数(t是小写),后者用的是Tensor类(T是大写)。当然,二者也有一些区别,比如在创建Tensor的默认数据类型、支持传参以及个别细节的处理方面。举个例子,首先是创建的Tensor默认数据类型不同:

其次,应用Tensor类初始化输入一个整数将返回一个以此为长度的全零一维张量,而tensor函数则返回一个只有该元素的零维张量:

当然,上述有一个细节需要优先提及:应用Tensor类接收一个序列创建Tensor时,返回的数据类型为float型,这是因为Tensor是FloatTensor的等价形式,即除此之外还有ByteTensor,IntTensor,LongTensor以及DoubleTensor等不同的默认数据类型。
基于已有数据创建Tensor还有两个常用函数:
-
from_numpy
-
as_tensor
二者与上述方法最大的不同在于它们返回的Tensor与原有数据是共享内存的,而前述的tensor函数和Tensor类则是copy后创建一个新的对象。举个例子来说:

2.随机初始化一个Tensor
随机初始化也是一种常用的形式,比如在搭建一个神经网络模型中,其实在添加了一个模块的背后也自动随机初始化了该模块的权重。整体而言,这类方法大体分为两种形式:
-
torch.xxxx,创建一个特定类型的tensor,例如torch.ones,torch.randn等等
-
torch.xxx_liek,即根据一个已有Tensor创建一个与其形状一致的特定类型tensor,例如torch.ones_like,torch.randn_like等等
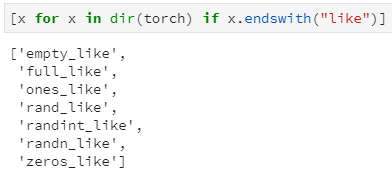
例如,随机构建一个PyTorch中的全连接单元Linear,其会默认创建相应的权重系数和偏置(注意,由于网络参数一般是需要参与待后续的模型训练,所以默认requires_grad=True):
整体来看,这两类方法与NumPy中的相应方法特性几乎一致,基本可以从函数名中get到其相应的含义,这里也不再展开。
3.从已保存文件加载一个Tensor
文件作为交互数据的常用形式,PyTorch中自然也不会缺席。实际上,PyTorch不会刻意区分要保存和加载的对象是何种形式,可以是训练好的网络,也可以是数据,这在Python中就是pickle。实现这一对互逆功能的函数是torch.save和torch.load。另外,值得指出的是,保存后的文件没有明确的后缀格式要求,常用的后缀格式有三种:
-
.pkl
-
.pth
-
.pt
举个例子:

小结一下
:PyTorch中创建一个Tensor大体可分为三种方法,即:1)从一个已有数据结构转换为Tensor,2)随机初始化生成一个Tensor,3)将已保存的文件加载为Tensor。其中,第一种方法主要用于构建训练数据集,第二种方法隐藏于网络模块参数的初始化,而第三种方法则可用于大型数据集的保存和跨环境使用。
03 Tensor的特性
PyTorch之所以定义了Tensor来支持深度学习,而没有直接使用Python中的一个list或者NumPy中的array,终究是因为Tensor被赋予了一些独有的特性。这里,我也将Tensor的特性概括为三个方面:
-
丰富的常用操作函数
-
灵活的dtype和CPU/GPU自由切换存储
-
自动梯度求解
下面分别予以介绍。
1.丰富的常用函数操作
Tensor本质上是一个由数值型元素组成的高维矩阵,而深度学习的过程其实也就是各种矩阵运算的过程,所以Tensor作为其基础数据结构,自然也就需要支持丰富的函数操作。构建一个Tensor实例,通过Python中的dir属性获取tensor实例支持的所有API,过滤以”_”开头的系统内置方法外(例如”__str__”这种),剩余结果仍有567种,其支持的函数操作之丰富程度可见一斑。

这些函数有的是对自身进行操作,例如tensor.max(), tensor.abs()等等,有的是用于与其他tensor进行相关操作,例如tensor.add()用于与另一个tensor相加,tensor.mm()用于与另一个tensor进行矩阵乘法等等。当然,这里的相加和相乘对操作的两个tensor尺寸有所要求。
除了支持的函数操作足够丰富外,tensor的API函数还有另一个重要的便利特性:绝大多数函数都支持两个版本:带下划线版和不带下划线版,例如tensor.abs()和tensor.abs_(),二者均返回操作后的Tensor,但同时带下划线版本属于inplace操作,即调用后自身数据也随之改变。
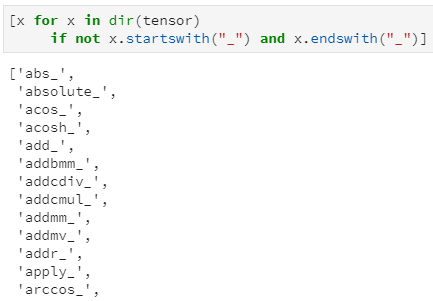
inplace版函数共有159种
2.灵活的dtype和CPU/GPU自由切换
前面在介绍Tensor的创建时已提到了dtype的概念,其类似于NumPy和Pandas中的用法,用于指定待创建Tensor的数据结构。PyTorch中定义了10种不同的数据结构,包括不同长度的整型、不同长度的浮点型,整个Tesor的所有元素必须数据类型相同,且必须是数值类型(NumPy中的array也要求数组中的元素是同质的,但支持字符串类型的):
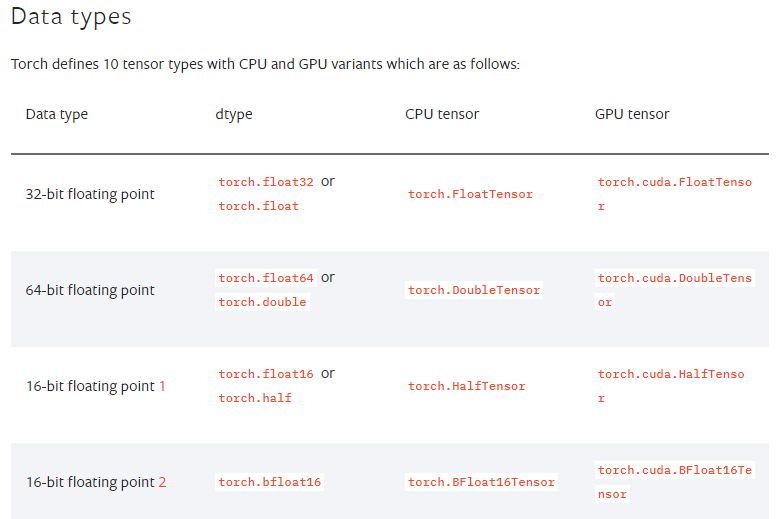
Tensor中的10种数据类型(不完整版)
除了支持不同的数值数据类型外,Tensor的另一大特色是其支持不同的计算单元:CPU或GPU,支持GPU加速也是深度学习得以大规模应用的一大关键。为了切换CPU计算(数据存储于内存)或GPU计算(数据存储于显存),Tensor支持灵活的设置存储设备,包括如下两种方式:
-
创建tensor时,通过device参数直接指定
-
通过tensor.to()函数切换

to()既可用于切换存储设备,也可切换数据类型
当然,能够切换到GPU的一大前提是运行环境带有独立显卡并已配置CUDA……此外,除了dtype和device这两大特性之外,其实Tensor还有第三个特性,即layout,布局。主要包括strided和sparse_coo两种,该特性一般不需要额外考虑。
3.自动梯度求解
如果说支持丰富和函数操作和灵活的特性,那么Tensor还不足以支撑深度学习的基石,关键是还需要自动梯度求解。
深度学习模型的核心是在于神经元的连接,而神经元之间连接的关键在于网络权重,也就是各个模块的参数。正因为网络参数的不同,所以才使得相同的网络结构能实现不同的模型应用价值。那么,如何学习最优网络参数呢?这就是深度学习中的的优化利器:梯度下降法,而梯度下降法的一大前提就是支持自动梯度求解。
简言之,Tensor为了支持自动梯度求解,大体流程如下:
-
Tensor支持grad求解,即requires_grad=True
-
根据Tensor参与计算的流程,将Tensor及相应的操作函数记录为一个树结构(或称之为有向无环图:DAG),计算的方向为从叶节点流向根节点
-
根据根节点Tensor与目标值计算相应的差值(loss),然后利用链式求导法则反向逐步计算梯度(也即梯度的反向传播)
Tensor中的自动梯度求导有很多细节值得展开,这里仅稍加介绍,并留待后续单独推文加以分享。
小结一下
:Tensor具有很多特性,这使得其可以支撑深度学习的复杂操作,个人认为比较重要的包括三个方面,即:1)丰富的操作函数,2)三大特性(dtype、device和layout),以及3)自动梯度求导。
04 小结
本文从何为Tensor—如何构建Tensor—Tensor有何特性三个方面入手,简要介绍了PyTorch中的核心数据结构——Tensor。理解并熟练运用Tensor的常用操作是深度学习的基石,就像”站在岸上学不会游泳”一样,学习Tensor的重点在于实践,毕竟“无他,唯手熟尔”!
交流群限时推广
:
【小数志】公众号唯一读者交流群还有100个左右坑位,广泛招募热衷技术交流的大佬和萌新,欢迎添加个人微信:
luanhz
,我会拉你入群。名额有限,错过不再。

相关阅读: