
训练、验证(开发)、测试集
我们通常会将我们的数据划分为以下几部分:

一部分作为训练集(training set
),一部分作为简单交叉验证集(hold-out cross validation set
)有时也称为开发集(development set
),最后一部分作为测试集(test set
)。
我们通过训练集训练我们的模型,然后通过验证集对我们的模型进行调优,最后通过测试集对我们调整好的模型进行无偏测试。在数据量较小(100-10000
)的情况下,一般进行7/3
划分或6/2/2
划分,即70%
训练集30%
测试集或者60%
训练集20%
验证集20%
测试集。当数据量增大时,我们可以逐步缩小验证集与测试集的规模,因为我们不需要过多数据就能对我们的模型性能进行评估。
有时我们的训练集和验证、测试集来自于不同的数据集,这时我们务必保证,
验证集和训练集必须来自同一数据集,有同一分布
。因为我们优化方向是用验证集调整的,我们的优化目标是测试集指定的,我们需要优化方向指向优化目标。但因为训练我们模型的书序量需要很大,为了获取更大规模的数据集,我们可能需要加入不同分布的类似数据集来扩大训练集,但必须保证验证、测试集分布一致。

偏差与方差
假设我们有如下数据集,并通过三种拟合方式进行分类:
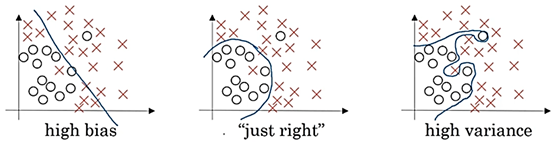
左边的函数不能很好的拟合我们的数据集,这时这个函数模型偏差高,我们称之为
欠拟合(
underfitting
)
。相反的,如果我们如右图一样,通过一个非常复杂的函数对其进行拟合,我们可能可以将该数据集的每一个数据都分类正确,但是放到其他数据集中,拟合效果不是很好,泛化性不强,因为它将一些异常数据也分类正确了,这时我们称之为
过拟合(
overfitting
)
。中间的通过较简单函数较好拟合我们的数据集,是我们的目标模型。
对于高维数据,我们很难通过画图形式看出偏差与方差,那么我们如何量化偏差与方差呢?实际上,我们可以对比在训练、验证、测试集中的错误率,来确定我们偏差与方差的相对大小。
假设我们要建立一个猫分类器,其中的训练集错误率和验证集错误率如下图所示。


其中高训练集错误率说明高偏差(high bias
),说明我们的模型在训练的时候就没训练得很好,一开始就偏离了我们的优化目标;而训练集错误率低,而验证集错误率高,也就是验证集错误率比训练集错误率高得多,称为高方差(high variance
),说明我们可能过拟合了训练集,泛化性能不够好。如果验证集错误率与训练集错误率都很小,说明我们的模型偏差和方差都比较低,这时我们的模型就比较优秀。
上述分析是建立在训练、验证集同分布的情况下的,在之后我们还会了解当训练、验证集分布不同时,我们该如何分析偏差与方差,并确定我们模型进一步优化的方向。
在数学上偏差被定义为:
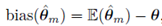
θ是我们数据的真实分布,而真实分布往往是不可知的,所以我们会用人类表现来代替,这在后边会进一步提到。偏差就是我们模型估计整体期望分布与真实分布的差值。
我们在高中学习的方差计算方法是:
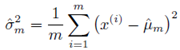
但这种方式通过计算可以证明是
有偏的
,我们可以对这个方差的计算值进行计算:
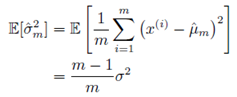
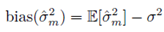
最终可以得到这样计算的方差与实际方差产生了-σ
2
/m
的偏差,只有在加大我们抽取的样本量m时才能近似为实际方差。
因此引入了无偏样本方差估计:
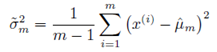
尽管无偏估计显然是令人满意的(因为没有偏差),但它并不总是最好的估计方式,实际中经常会使用其他具有重要性质的有偏估计。
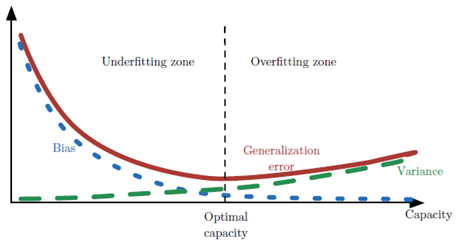
在我们实际训练模型的情况中,当数据集容量增大(x
轴)时,偏差(蓝线)随之减小,而方差(绿线)随之增大,使得泛化误差(加粗曲线)产生了另一种U
形。如果我们沿着轴改变容量,会发现最佳容量,当容量小于最佳容量会呈现欠拟合,大于时导致过拟合。
在人的表现部分,会具体讲解
如何根据偏差与方差决定我们的模型优化方向
。
Reference
深度学习课程 –吴恩达
Deep learing –Ian Goodfellow,Yoshua bengio,Aaron Courville
