1.进程的堆栈
内核在创建进程的时候,在创建task_struct的同事,会为进程创建相应的堆栈。每个进程会有两个栈,一个用户栈,存在于用户空间,一个内核栈,存在于内核空间。当进程在用户空间运行时,cpu堆栈指针寄存器里面的内容是用户堆栈地址,使用用户栈;当进程在内核空间时,cpu堆栈指针寄存器里面的内容是内核栈空间地址,使用内核栈。
2.进程用户栈和内核栈的切换
当进程因为中断或者系统调用而陷入内核态之行时,进程所使用的堆栈也要从用户栈转到内核栈。
进程陷入内核态后,先把用户态堆栈的地址保存在内核栈之中,然后设置堆栈指针寄存器的内容为内核栈的地址,这样就完成了用户栈向内核栈的转换;当进程从内核态恢复到用户态之行时,在内核态之行的最后将保存在内核栈里面的用户栈的地址恢复到堆栈指针寄存器即可。这样就实现了内核栈和用户栈的互转。
那么,我们知道从内核转到用户态时用户栈的地址是在陷入内核的时候保存在内核栈里面的,但是在陷入内核的时候,我们是如何知道内核栈的地址的呢?
关键在进程从用户态转到内核态的时候,进程的内核栈总是空的。这是因为,当进程在用户态运行时,使用的是用户栈,当进程陷入到内核态时,内核栈保存进程在内核态运行的相关信心,但是一旦进程返回到用户态后,内核栈中保存的信息无效,会全部恢复,因此每次进程从用户态陷入内核的时候得到的内核栈都是空的。所以在进程陷入内核的时候,直接把内核栈的栈顶地址给堆栈指针寄存器就可以了。
3.内核栈的实现
内核栈在kernel-2.4和kernel-2.6里面的实现方式是不一样的。
在kernel-2.4内核里面,内核栈的实现是:
Union task_union {
Struct task_struct task;
Unsigned long stack[INIT_STACK_SIZE/sizeof(long)];
};其中,INIT_STACK_SIZE的大小只能是8K。
内核为每个进程分配task_struct结构体的时候,实际上分配两个连续的物理页面,底部用作task_struct结构体,结构上面的用作堆栈。使用current()宏能够访问当前正在运行的进程描述符。
注意:这个时候task_struct结构是在内核栈里面的,内核栈的实际能用大小大概有7K。
内核栈在kernel-2.6里面的实现是(kernel-2.6.32):
Union thread_union {
Struct thread_info thread_info;
Unsigned long stack[THREAD_SIZE/sizeof(long)];
};
其中THREAD_SIZE的大小可以是4K,也可以是8K,thread_info占52bytes。
具体结构见图:
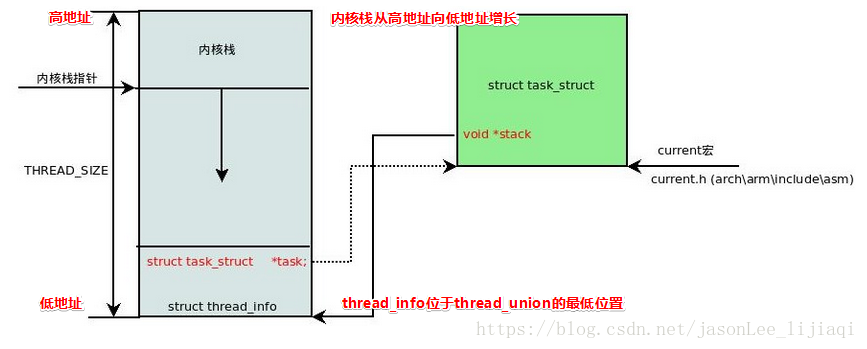
当内核栈为8K时,Thread_info在这块内存的起始地址,内核栈从堆栈末端向下增长。所以此时,kernel-2.6中的current宏是需要更改的。要通过thread_info结构体中的task_struct域来获得于thread_info相关联的task。更详细的参考相应的current宏的实现。
struct thread_info {
struct task_struct *task;
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
… ..
};注意:此时的task_struct结构体已经不在内核栈空间里面了。
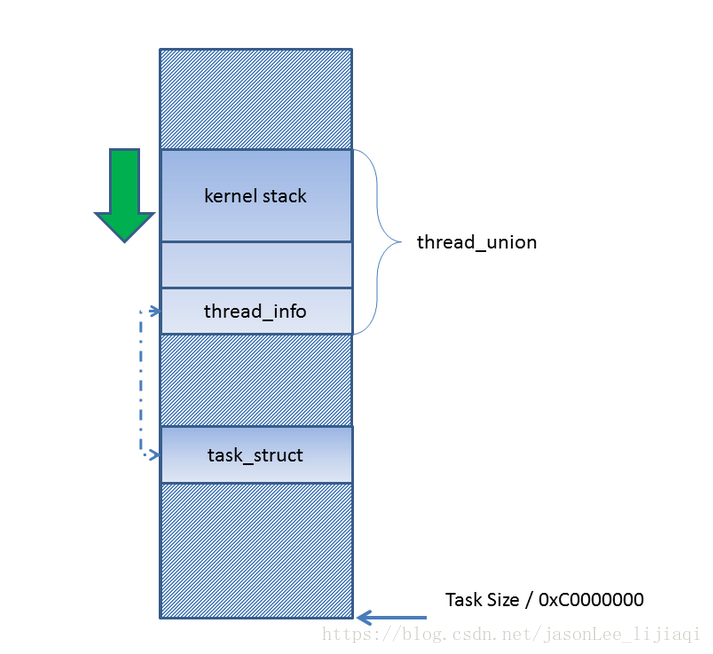
一个实际的内核栈的结构将如下图所示。由于栈总是由高地址向低地址延伸的,所以栈底位于thread_union联合体的最末端,而thread_info结构则位于thread_union联合体的开始处,而且所占用的空间比较少。只要不出现内核栈特别大的极端情况,栈与thread_info可以互不干扰。该图为内核地址空间示意图。
用户栈
用户栈就是应用程序直接使用的栈。如下图所示,它位于应用程序的用户进程空间的最顶端。
当用户程序逐级调用函数时,用户栈从高地址向低地址方向扩展,每次增加一个栈帧,一个栈帧中存放的是函数的参数、返回地址和局部变量等,所以栈帧的长度是不定的。
用户栈的栈底靠近进程空间的上边缘,但一般不会刚好对齐到边缘,出于安全考虑,会在栈底与进程上边缘之间插入一段随机大小的隔离区。这样,程序在每次运行时,栈的位置都不同,这样黑客就不大容易利用基于栈的安全漏洞来实施攻击。
用户栈的伸缩对于应用程序来说是透明的,应用程序不需要自己去管理栈,这是操作系统提供的功能。应用程序在刚刚启动的时候(由fork()系统调用复制出新的进程),新的进程其实并不占有任何栈的空间。当应用程序中调用了函数需要压栈时,会触发一个page fault,内核在处理这个异常里会发现进程需要新的栈空间,于是建立新的VMA并映射内存给用户栈。

内核栈和用户栈区别:
intel的cpu分为四个运行级别ring0~ring3
内核创建进程,创建进程的同时创建进程控制块,创建进程自己的堆栈
一个进程有两个堆栈,用户栈和系统栈
用户堆栈的空间指向用户地址空间,内核堆栈的空间指向内核地址空间。
有个CPU堆栈指针寄存器,进程运行的状态有用户态和内核态,当进程运行在用户态时。CPU堆栈指针寄存器指向的是用户堆栈地址,使用的是用户堆栈;当进程运行在内核态时,CPU堆栈指针寄存器指向的是内核堆栈地址,使用的是内核堆栈。
1、堆栈切换
当系统因为系统调用(软中断)或硬件中断,CPU切换到特权工作模式,进程陷入内核态,进程使用的栈也要从用户栈转向系统栈。
从用户态到内核态要两步骤,首先是将用户堆栈地址保存到内核堆栈中,然后将CPU堆栈指针寄存器指向内核堆栈。
当由内核态转向用户态,步骤首先是将内核堆栈中得用户堆栈地址恢复到CPU堆栈指针寄存器中。
2、内核栈和用户栈区别
2.1
栈是系统运行在内核态的时候使用的栈,用户栈是系统运行在用户态时候使用的栈。
当进程由于中断进入内核态时,系统会把一些用户态的数据信息保存到内核栈中,当返回到用户态时,取出内核栈中得信息恢复出来,返回到程序原来执行的地方。
用户栈就是进程在用户空间时创建的栈,比如一般的函数调用,将会用到用户栈。
2.2
内核栈是属于操作系统空间的一块固定区域,可以用于保存中断现场、保存操作系统子程序间相互调用的参数、返回值等。
用户栈是属于用户进程空间的一块区域,用户保存用户进程子程序间的相互调用的参数、返回值等。
2.3.
每个Windows 都有4g的进程空间,系统栈使用进程空间的地段部分,用户栈是高端部分如果用户要直接访问系统栈部分,需要有特殊的方式。
为何要设置两个不同的栈?
共享原因:
内核的代码和数据是为所有的进程共享的,如果不为每一个进程设置对应的内核栈,那么就不能实现不同的进程执行不同的代码。
安全原因:
如果只有一个栈,那么用户就可以修改栈内容来突破内核安全保护。