详细解析
使用
jupternotebook
作为编译软件进行代码实现(当然也可以用Pycharm):
-
导入需要使用的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
# 魔法方法,可以将matplotlib的图表直接嵌入到Notebook之中
%matplotlib inline
-
导入数据
data = pd.read_excel('C:/Users/Desktop/Lab_01_data.xlsx')
-
数据处理
data=pd.DataFrame(data)
-
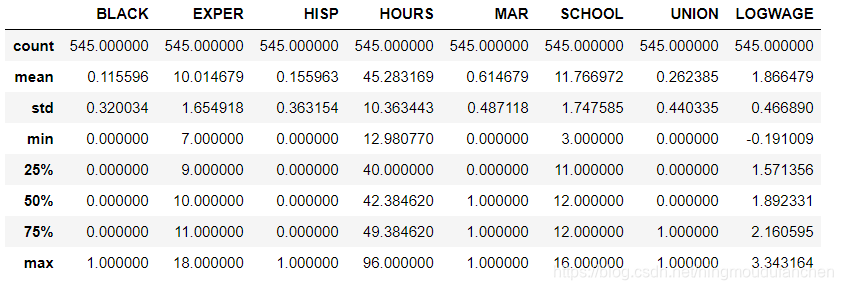
对总体数据进行
描述性统计
data.describe()
描述性统计输出结果
-
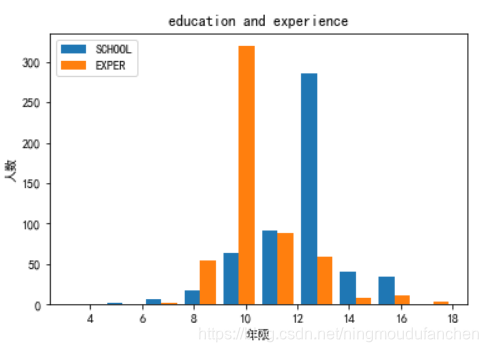
绘制受教育年限和工作经验(年限)的
直方图
#解决中文字体显示的问题,直接复制运行
plt.rcParams['font.sans-serif']=['simhei']
plt.rcParams['axes.unicode_minus']=False
#x值
newx=[data['SCHOOL'],data['EXPER']]
labels=['SCHOOL','EXPER']
plt.hist(newx,label=labels)
#设置图例
plt.legend(loc='upper left')
#x、y轴标签
plt.xlabel("年限")
plt.ylabel("人数")
#表标题
plt.title('education and experience')
直方图输出结果
-
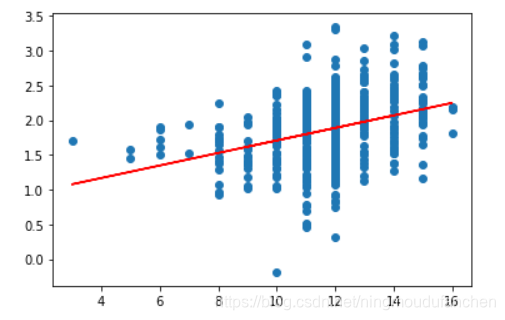
绘制工资和受教育年限的
散点图
并添加
拟合回归线
x=data['SCHOOL']
y=data['LOGWAGE']
z1 = np.polyfit(x, y, 1) # 1表示用1次多项式拟合
p1 = np.poly1d(z1)#拟合方程
f=p1(x)
plt.scatter(data['SCHOOL'],data['LOGWAGE'])
plot2=plt.plot(x, f, 'r',label='polyfit values')#画拟合线
散点图输出结果
-
最小二乘回归(
OLS
)
x = data[['BLACK','EXPER','HISP','MAR','SCHOOL','UNION']]
y = data[['LOGWAGE']]
x=sm.add_constant(x) #添加常数项
est=sm.OLS(y,x)
model=est.fit()#建立最小二乘回归模型
print(model.summary())
回归结果

说明
回归方程为:
LO
G
W
A
G
E
i
=
β
1
+
β
2
S
C
H
O
O
L
i
+
β
3
E
X
P
E
R
i
+
β
4
U
N
I
O
N
i
+
β
5
M
A
R
i
+
β
6
B
L
A
C
K
i
+
β
7
H
I
S
P
i
+
ϵ
i
LOGWAGE_i = \beta_1 + \beta_2SCHOOL_i +\beta_3EXPER_i + \beta_4UNION_i + \beta_5MAR_i + \beta_6BLACK_i + \beta_7HISP_i +\epsilon_i
L
O
G
W
A
G
E
i
=
β
1
+
β
2
S
C
H
O
O
L
i
+
β
3
E
X
P
E
R
i
+
β
4
U
N
I
O
N
i
+
β
5
M
A
R
i
+
β
6
B
L
A
C
K
i
+
β
7
H
I
S
P
i
+
ϵ
i