一、存储器与CPU的连接
1.1 单块存储芯片与CPU的连接

**问题:**数据总线宽度>存储芯片字长无法直接进行读取!
解决方法:通过多块存储芯片的连接解决字长不匹配的问题!请看下节
1.2 多块存储芯片与CPU的连接
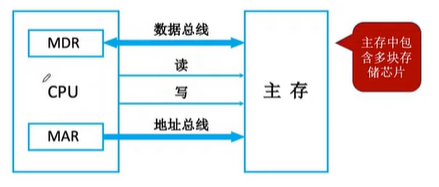
与上一节中的主存结构不同的地方:将MAR和MDR都集成在了CPU中,MDR通过数据总线与主存进行交互,MAR通过地址总线与主存进行交互,
主存中会包含多块存储芯片
1.2.1 位扩展法
Ai:地址总线
Di:数据总线
WE:使能信号
CS:片选信号

-
这里的8Kx1bit的存储芯片,说明了每一块存储芯片都只能够传送一位数据出来,这里只能够连接到CPU中的一位Di上,通过扩展将
相同的
存储芯片也同样连接Ai和Di,
人类的本质是复读机~
-
这里注意这个CS都是置为1的,所以他们都可以直接进行工作;

- 这里将存储字长由1bit存储字长扩张为8bit;
- 8片8Kx1bit的存储芯片->1个8kx8位的存储器,容量8k8
1.2.2 字扩展法

-
8kx8位的存储,与CPU的8bit的数据总线是
匹配的
,可以直接传输,不需要进行位扩展; -
CPU有16位地址总线,而存储芯片只有13位地址总线,有3位被浪费了,这里会同样进行
复读机扩展
,这里使用相同的存储芯片进行扩展,数据总线与CPU相连接,但是容易造成片选信号的冲突;

-
使用3-8译码器可以将浪费的3位都利用起来,并且不会出现上面线选法的存储空间不连续的情况;

1.2.1 字位扩展法

- 由上面两种方法进行扩展,将两个16kx4bit的芯片通过位扩展方法进行扩展,然后形成16kx8bit的一组芯片;
-
字扩展是通过2-4译码器进行扩展;

二、存储周期过长的问题及后续的解决方法
2.1存储周期
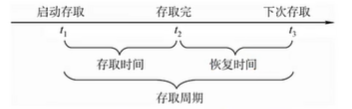
**存取周期:**可以连续读/写的最短时间间隔;
-
由于DRAM是电容存储,它在存取时是破环性的,并且它的恢复时间比较长,例如存取时间为r,存取周期为T,T=4r;
问题
:多核CPU都要访问,但是主存的恢复时间太长怎么办?
2.2 双口RAM
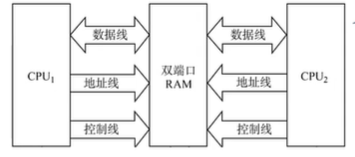
作用:
优化
多核CPU访问一根内存条的
速度
组成:两组完全独立的数据线、地址线、控制线、CPU、RAM中也要由更复杂的控制电路
两个端口对同一主存的操作:
-
两个端口
同时
对
不同地址单元存取数据
; -
两个端口
同时
对
同一地址单元读出数据
; -
两个端口
同时
对
不同地址单元写入数据
; -
两个端口
同时
对
同一地址单元,一个写入,另一个读出数据
2.3 多体并行存储器

- 低位交叉编址方式是以流水线的形式进行读取的,这样能够不改变每个模块存取周期的前提下,采用流水线并行存取,提高存储器的带宽;
- 模块数:m>=T/r
三、cache
3.1 局部性原理
空间局部性
:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息存储空间上是临近的;
时间局部性
:在最近的未来要用到的信息,很可能是现在正在使用到的信息,例如循环语句;
基于局部性原理,可以将CPU目前访问的地址“周围”的部分数据放到Cache中
3.2 性能分析
cache会从主存中拿到数据和指令,但是这个是否是CPU想要要的指令和数据是不一定的。为此有一个参数来说明cache所拿到的指令和数据站CPU想要拿的指令的比例(也就是命中率)

这里有一个例题

3.3cache进行将cpu访问的数据选定问题
一般是将主存的存储空间“分块”,如:1KB为一块,主存和cache之间以块为单位进行数据交换;

- cache是从主存中取得数据,这个取得是通过复制的方式进行的,所以需要将复制之后如何将cache和主存之间的数据块关系对应起来是需要我们考虑cache和主存的映射方式
- cache容量很小,而主存很大,很容易造成cache满了,所以需要替换算法
- CPU修改了cache中的数据副本需要确保主存中数据母本的一致性
3.4映射方式
3.4.1 全相连映射

为了区分cache中存放的是哪个主存块,给每个cache块增加了一个标记,记录对应的主存块号
但是只有标记位的话容易造成标记位位进行映射的部分会只指向0这个位置,所以我们需要有效位来说明标记位的实际上指的是什么地方。


CPU在访问cache过程中会先将标记位进行比较,然后看有效位是否可以之后命中之后将数据进行传递给主存之中。
3.4.2 直接映射(只能放到固定的位置)
通过将主存块在cache中的
位置=主存块号%cache的总块数
,这里对应主存块中如果是8位的cache是直接将主存块号的最后三位留下来即可,不需要做别的什么计算操作。

3.4.3 组相连映射(可放到特定的分组)


3.5替换算法
3.5.1 随机算法RAND
若cache已满,随机选择一块进行替换

这种方法容易产生命中率低的问题
3.5.2 FIFO
若cache已满,则替换最先被调入cache块

FIFO没有考虑局部性原理,最先被调入的cache的块也有可能是被频繁访问的
3.5.3 近期最少使用算法(LRU)
为每一个cache块设置一个“计数器”,用于记录每个cache以及由多久没有被访问了,当cache满后替换计算器最大的
- 命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变;
- 未命中且还有空闲行时,新装入的行的计数器置0,其余全加1;
- 未命中且无空闲行时,计数为3的行的信息块被淘汰,新装行的块的计数器置0,其余全加1;
3.5.4 近期最少使用算法(LFU)
最不经常使用算法,为每一个cache块设置一个计数器,用于记录每个cache块被访问次数,当cache满后替换计数器最小的
3.6 cache写策略
3.6.1 写回法
当CPU对cache写命中时,只修改cache的内容,而不立即写入主存,只有当此块被替换时才写回主存。但是这种方法可能导致数据不一致的情况;
3.6.2 全写法
当CPU对Cache写命中时,必须把数据同时写入cache和主存,一般使用写缓存;但是会导致访问过多导致访问数据慢;
3.7 虚拟存储器
3.7.1 虚拟存储器
3.7.1.1 涉及的相关概念
-
虚拟存储器
:主存和辐存共同构成虚拟存储器,两者通过硬件+系统软件共同作用下进行工作 -
为什么要有虚拟存储器
:面对的对象不同,对与
程序员
,虚拟存储器是看得到的 -
虚地址/逻辑地址
:用户(程序员)编程允许使用的地址称为虚地址或逻辑地址,
虚地址=虚页页号+页内字地址
; -
虚拟空间/
:虚地址对应的存储空间称为虚拟空间或者程序空间; -
实地址
:实际的主存单元地址,
实地址=主页页号+页内字地址
; -
实地址空间
:实地址对应的主存空间;
3.7.1.2 CPU如何使用虚拟存储器的方法
-
CPU想要使用虚拟存储器中的数据或者指令时,需要通过辅助硬件找到虚地址和实地址之间的
对应关系
; -
找到对应关系后进行判断
虚地址和对应的存储单元内容
是否已经在主存中,如果已经在主存中,通过
地址转换
,CPU直接访问主存所指示的实际单元; - 如果不存在主存中,那就将包含这个字的一页(存储单位,下节说到)都调入主存中在进行访问;
- 如果主存满了,将通过替换算法进行置换主存中的一页;
3.7.2 页式存储
一个程序(进程)在逻辑上被分为若干个大小相等的页面,页面大小与块的大小相同,每个页面可以离散地放到不同地主存块中;
3.7.2.1 页表
页表
:记录每个
逻辑页号->主存块号
之间的对应关系,页表一般长久保存在内存中;
页表基址寄存器
:指明页表在主存中的存放地址;
页表项
:页表中的每一行,包括逻辑页号和主存块号;
有效位
:表示对应的页面是否存在主存,如果为1表示虚拟也已从外存调入主存,
3.7.2.2 地址转换过程

- 首先将虚拟地址转换为主存物理地址,其中会根据进行查找;
- 每个进程都页表基址寄存器,存放进程对应的页表基址寄存器,CPU就会根据这个虚拟地址高位部分找到对应页表项。
- 根据装入位是否为1,确定是否取出物理页号,取出之后与虚拟地址低位部分的页内地址进行拼接,然后形成实际的物理地址。
- 然后在查找过程中会需要先在cache中进行查找,如果在cache中找到那直接在cache中副本数据进行访问物理地址,如果没有那就去主存中进行访问;
- 由于** 局部性原理**,后续很有可能会多次访问首次进行访问的界面,为了使得访问更加方便,将**近期访问的页表项放入更高速的存储器,**可以加快地址访问速度,也就是下节的快表;
3.7.2.3 块表TLB
TLB由高速缓冲器组成,在地址转换时,首先会查找快表,若命中,则无需访问主存中的页表;
cache和TLB的区别
:cache存储的是主存块的副本,TLB存储的是页表项的副本;
快表和页表的区别
:TLB采用的是SRAM且采用的相联存储器,页表采用的是DRAM。

3.7.3 段式虚拟存储器

与页式存储器相类似的地方:页式存储器(页号+页内地址),而段式存储器(段号+段内地址);
