下载独立安装版 Eclipse Memory Analyzerhttps://www.eclipse.org/mat/
写了些啥?
Eclipse Memory Analyzer 的介绍和使用说明.基本上是帮助文档的中文翻译版本
什么是 Heap Dump ?
Heap dump 的中文名称是 堆转储.
堆转储是Java进程在某个时间点的内存快照。持久化此数据有不同的格式,根据格式的不同,它可能包含不同的信息片段,但通常快照包含关于触发快照时堆中的java对象和类的信息。通常,在写堆转储之前会触发一个完整的GC,因此它包含关于剩余对象的信息。
可以在堆转储中找到的典型信息(取决于堆转储类型)是:
所有对象
类、字段、原始值和引用
所有类
类加载器,名称,超类,静态字段
垃圾收集根
被定义为JVM可以访问的对象
线程堆栈和本地变量
快照时刻的线程调用堆栈,以及关于本地对象的每帧信息
浅堆与保留堆(shallow vs Retained Heap)
浅堆是一个对象自身消耗的内存。一个对象每个引用需要32位或64位(取决于OS体系结构),Integer 4个字节,Long 8个字节等。根据堆转储格式,可以调整大小(例如,对齐到8字节等等),以更好地模拟VM的实际消耗。
Retained Set of X是当X被垃圾收集时由GC移除的对象集。
Retained heap of X 是Retained Set 中所有对象的浅堆大小的总和,即由X持有的存活内存。
一般来说,对象的shallow heap是其在堆中的大小,并且同一对象的retained size是当对象被垃圾收集时将释放的堆内存量。
一组对象的Retained Set (包括这些对象以及只能通过这些对象访问的所有其他对象) 的大小是包含在集合中的所有对象的总堆大小。
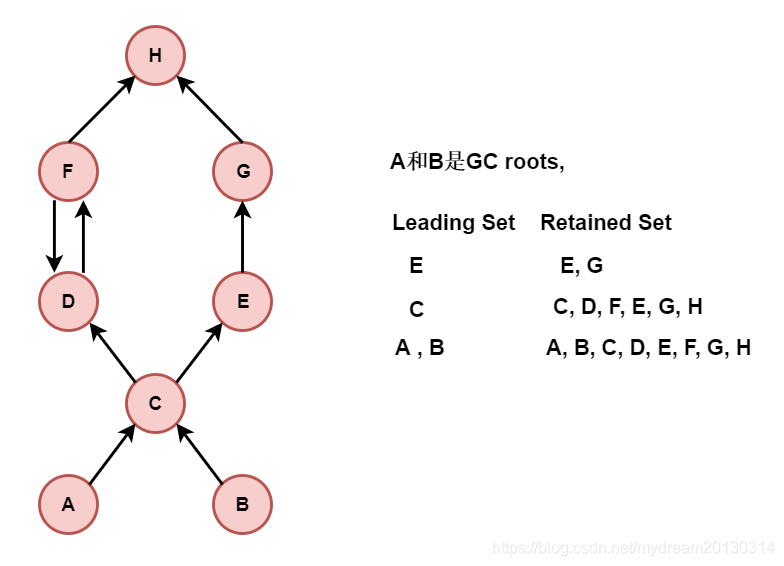

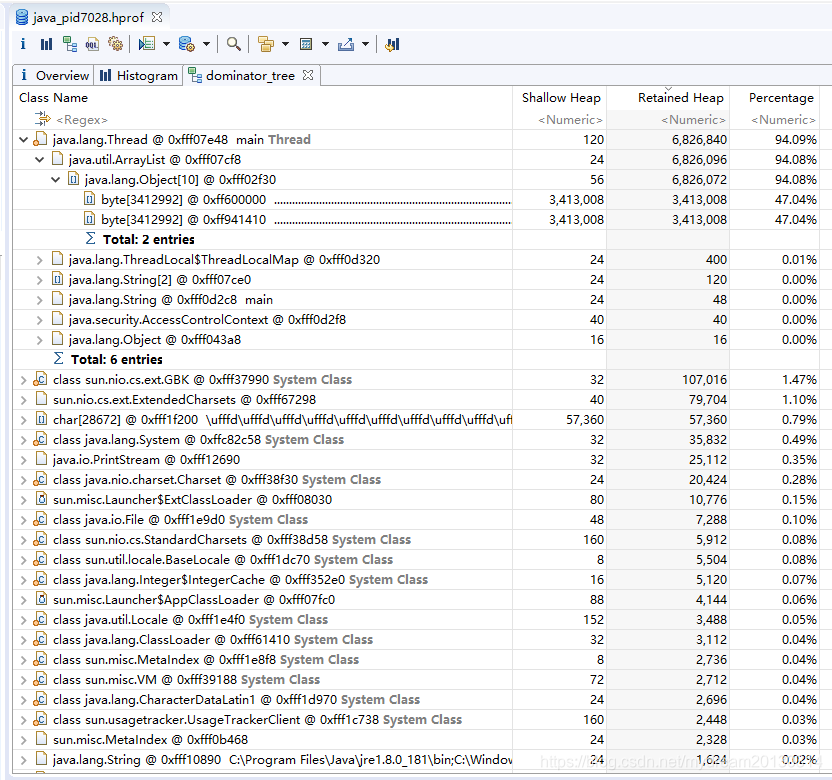
例如上图的堆转储文件的 domainator_tree 图 . ArrayList 持有 两个 byte[] 的数组.
代码形式为 List<byte[]> list;
-
ArrayList 的
shallow heap = 12(对象头)+4(ArrayList的内部数组的头(size))+4(存有一个对象的引用地址)B=24B retained heap = 24B + 56B + 3413008 * 2 B = 6,826,096 B (如果释放 ArrayList这个对象 , 那么堆中将被释放的所有内存量) -
Object[10] shallow heap = 12(对象头) + 4(数组头) + 4*10(10个地址引用) = 56B
获取 Heap Dumps 的方式
使用JVM参数在程序崩溃时,当前工作目录自动生成 Dumps 文件
#默认生成 java_pid<pid>.hprof文件在当前工作目录
-XX:+HeapDumpOnOutOfMemoryError
#可以指定dump文件位置,值可以是目录或者文件
-XX:HeapDumpPath=./dumps
使用 jmap 工具生成 heap dump
jmap -dump:format=b,file=<filename.hprof>
使用 JConsole 工具
使用 Memory Analyzer 工具生成见下文
使用 Memory Analyzer 工具 生成 heap dumps

Querying Heap Objects (OQL) 查询堆对象
分析器使用类似于SQL的查询语法查询堆转储的对象. OQL 中 classes 作为 tables, objects 做为行数据,以及 fields 作为列.
SELECT *
FROM [ INSTANCEOF ] <class name="name">
[ WHERE <filter-expression> ]
</filter-expression></class>
#查询 ArrayList size=2 的所有对象
select * from java.util.ArrayList where size = 2
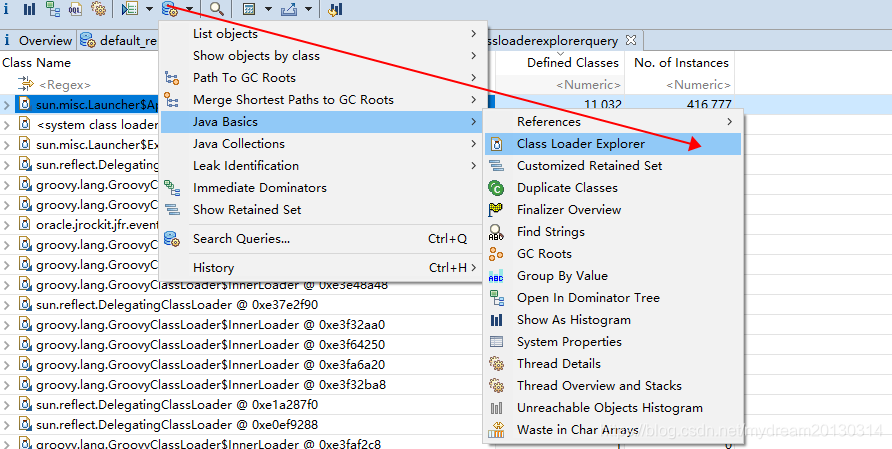
分析类加载 Analyze Class Loader
类加载器将类加载到JVM的内存中。在分析堆时,类加载器非常重要,原因有二:首先,应用程序通常使用单独的类加载器加载组件。其次,加载的类通常存储在单独的空间中(例如 perm space),也会被耗尽。
内存分析器在类加载器上附加一个有意义的标签——在OSGi bundles 的情况下,它是bundle id。
在类加载器名称旁边,表包含已定义的类和活动实例的数量。如果一个组件和相同的组件被多次加载,那么活动实例的数量可以指示哪个类加载器更活跃,哪个应该被垃圾收集。
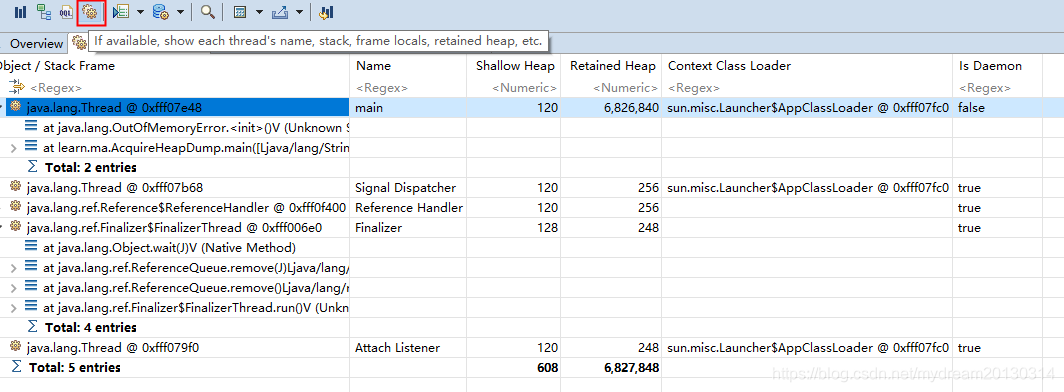
分析线程 Analyzing Threads
线程概览视图
分析集合 Analyzing Collections
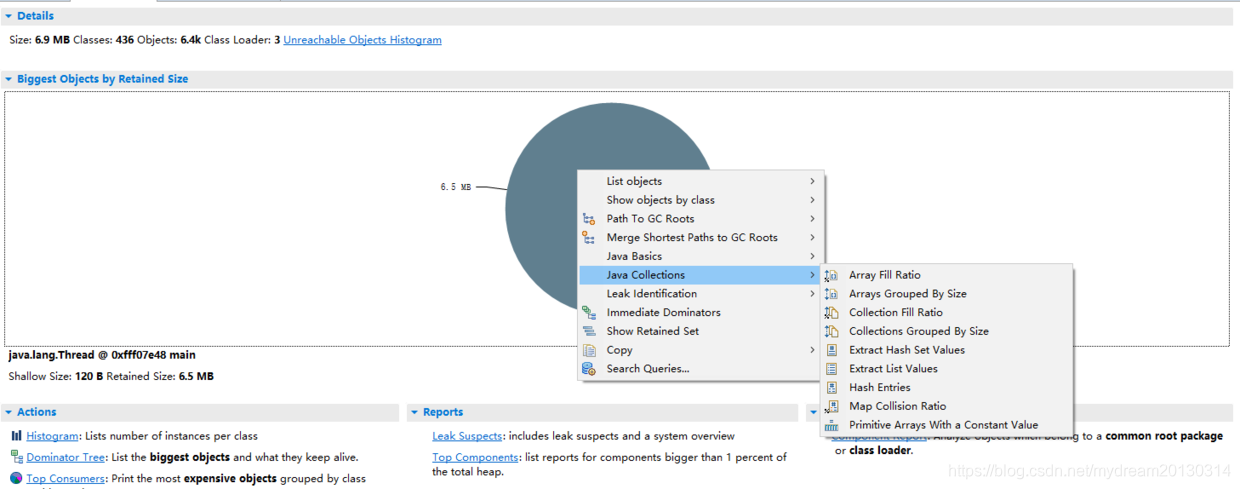
如上图 选中饼图得最大对象,单击选择 Java Collections 就可以对该对象持有的集合进行分析,分别是:
Array Fill Ratio数组填充率
Arrays Grouped By Size 对数组按大小分组
Collections Group By Size 对集合按大小分组
Extract Hash Set Values提取哈希集值
Extract List Values提取列表值
Hash Entries哈希条目
Map Collision Ratio MapHash碰撞率
Primitive Arrays With a Constant Value具有常量值的基本数组
使用时可以看到详细的操作说明提示
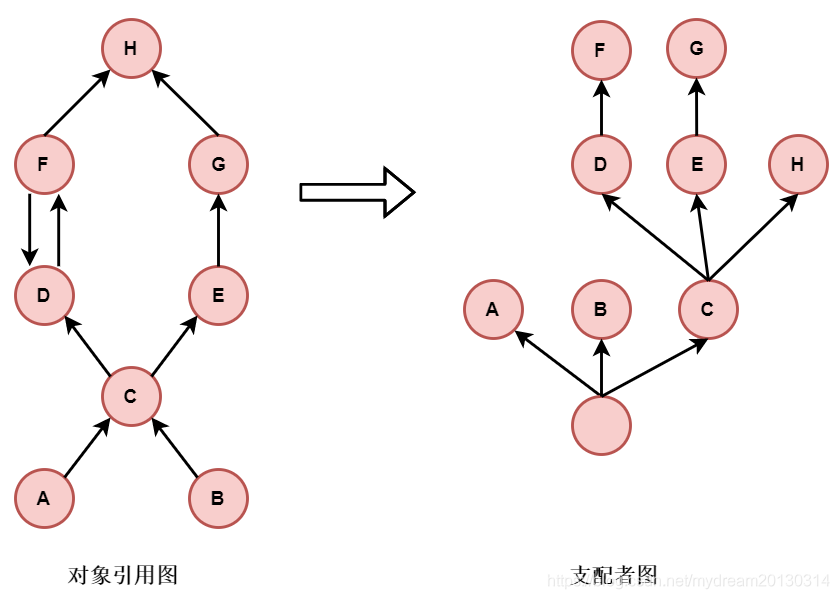
Dominator Tree (支配树)
内存分析器提供对象图的支配树。将对象引用图转换为一个dominator树可以轻松地识别最大的保留内存块(retained heap)和对象之间的keep-alive依赖关系。Bellow是对这些术语的非正式定义。
如果对象图中从开始(或节点)到y的每个路径都必须经过x,则对象x支配对象y。
某对象y的直接主导者x是离对象y最近的支配者。
从对象图构建一个dominator树。在dominator树中,每个对象都是其子对象的直接控制器,因此对象之间的依赖关系很容易识别。
支配树具有以下重要属性:
•属于x子树的对象(即由x控制的对象)表示 Retained Set of X。
•如果x是y的直接支配者,那么x的直接支配者也支配y,依此类推。
•dominator树中的边不直接对应对象图中的对象引用。
如下图:
垃圾收集根(GC Roots)
垃圾收集根是从堆外部访问的对象。以下原因使对象成为GC根:
System class 系统类
由引导程序/系统类装入器装入的类。例如,从rt.jar到java.util的所有内容
JNI Local
本地代码中的本地变量,如用户定义的JNI代码或JVM内部代码。
JNI Global
本地代码中的全局变量,如用户定义的JNI代码或JVM内部代码。
Thread Block
从当前活动线程块引用的对象。
Thread
启动的线程,而不是终止的
Busy Monitor
调用 wait() 或 notify() 或 synchronized 的一切。例如,通过调用synchronized(obj)或调用同步方法(静态方法表示同步Class,非静态方法表示同步对象实例)
Java Local
局部变量。例如,输入参数或本地创建的方法对象仍然在线程堆栈中。
Native Stack 本地堆栈
本地代码中的输入或输出参数,如用户定义的JNI代码或JVM内部代码。这种情况经常发生,因为许多方法都有本地部分,而作为方法参数处理的对象成为GC根。例如,用于文件/网络I/O方法或反射的参数。
Finalizable
在队列中等待结束程序运行的对象。
Unfinalized
具有finalize方法但尚未最终确定且尚未在finalizer队列上的对象。
Unreachable 遥不可及的
无法从任何其他根访问的对象,但由MAT标记为根以保留不包含在分析中的对象。
Java Stack Frame Java堆栈帧
一个Java堆栈帧,包含本地变量。仅在使用首选项集解析转储时生成,该首选项集将Java堆栈帧视为对象。
Unknow 未知的
未知根类型的对象。一些转储文件,例如IBM可移植堆转储文件,没有根信息。对于这些转储,MAT解析器将没有入站引用或无法从任何其他根访问的对象标记为这种类型的根。这确保MAT保留了转储中的所有对象。
MAT 的几种常用视图
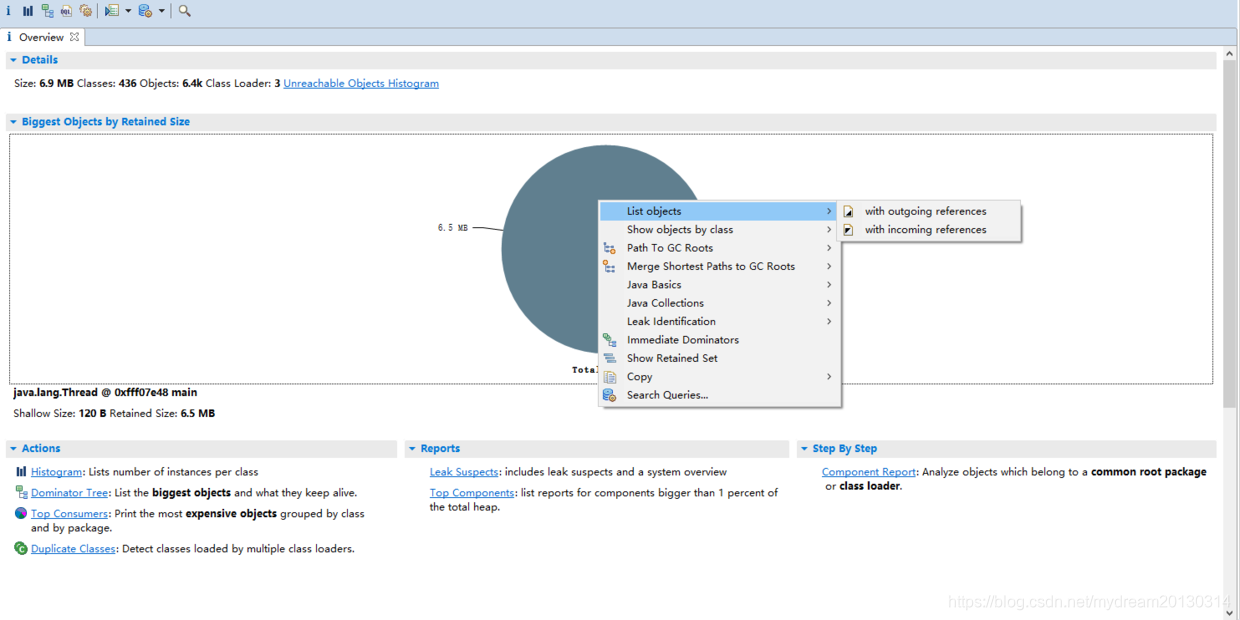
1. 概览视图
概览视图 Details 显示了 heap 总大小 , 加载的Class数 , 实例对象数 类加载器个数
Biggest Objects by Retained Size 显示了对象 Retained size 的 饼图 , 可以很方便找出持有内存最大的对象组 , 然后进行具体分析 , 例如列出 该对象持有其他对象等
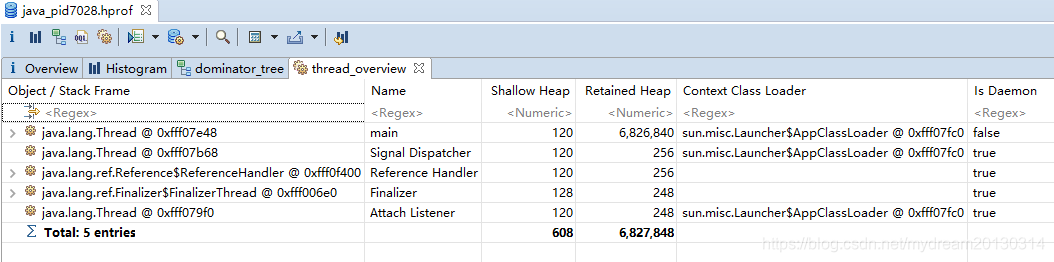
下图显示的是 主线程占用保留堆大小 6.5M , 而总大小是 6.9M , 所以如果发生了内存溢出,很大程度是该线程的问题,或者持有对象的问题
2. 直方图 Histogram
直方图显示按类分组的对象 shallow heap size 和 retained heap size 表格视图,便于查询哪个具体的对象组占用内存最多.同样点击后,有菜单可以具体分析
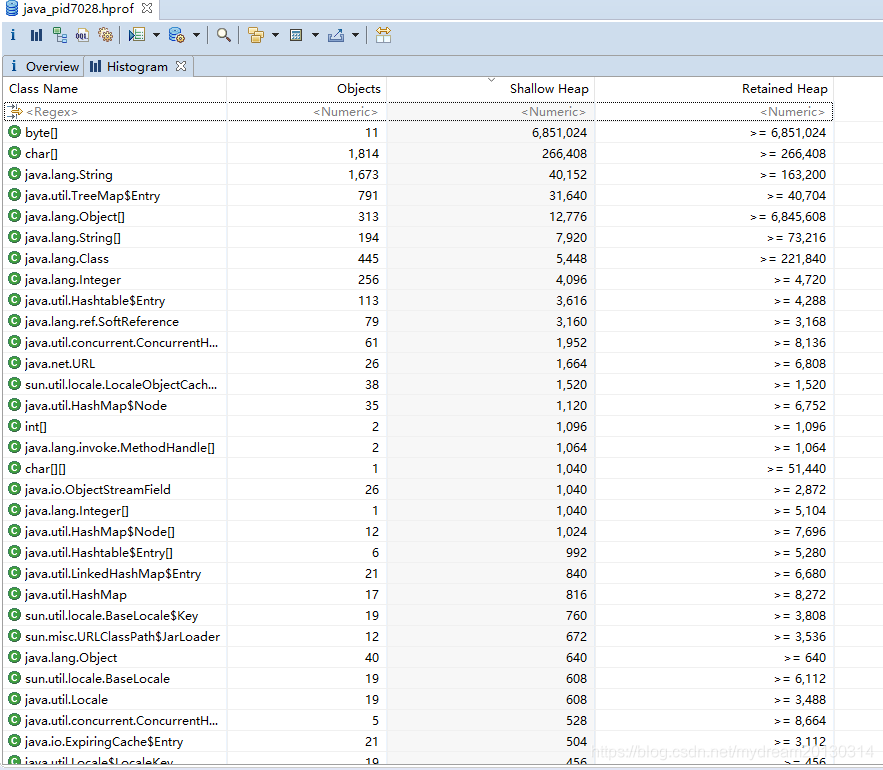
可以按 包名分组 , 类加载器分组

3. 支配树 dominator tree
支配关系见上文的分析.
可以按 包名分组 , 类加载器分组
4. 线程概览图