通过GAT简单建模实战
前言
近年来,注意力机制的受欢迎程度迅速上升,成为许多自然语言处理和计算机视觉任务的最先进方法。它们的优势在于注意力允许神经网络有效地选择一个输入子集,这些输入似乎能够判断任务重要性,这使我们能够为最重要的特征保留我们的网络表现力。
通过实现图注意网络或GAT(
论文
)来构建图卷积网络,以对图结构化数据进行节点分类。
一、GAT数学表达
GAT的构建块是图形注意层,它是我们以前提到的聚合函数的变体。在 GAT 中,每个图层的输入是一组 N 个节点要素,其中 N 是节点数。每个图层的输出同样是一组 N 节点要素,但这些节点要素可能具有新的维度。然后,我们现在要做的就是应用一个共享注意力函数,该函数计算注意力系数,捕获每个输入节点的特征对每个节点的重要性。
数学形式:
然后将来自邻居的嵌入聚合在一起,并根据图的结构属性(节点度)按注意力分数进行缩放。GAT 模型使用归一化注意力系数计算相邻节点变换特征的加权平均值(后跟非线性),作为 i 的新表示形式:
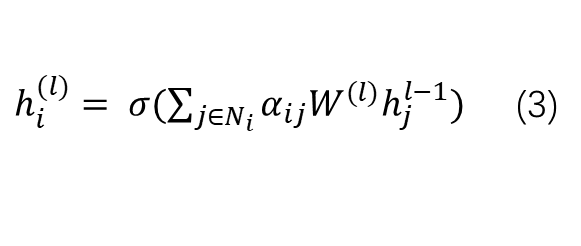
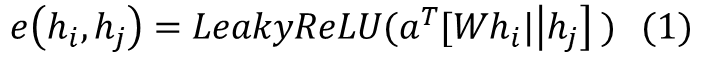
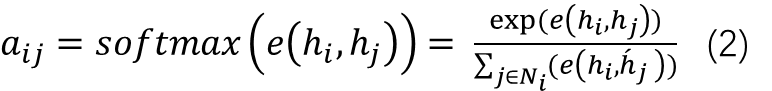
其中a_i表示共享注意力函数,W_i表示应用于每个节点的权重矩阵,h_i表示节点 i 的节点特征。
借鉴论文中的图例:
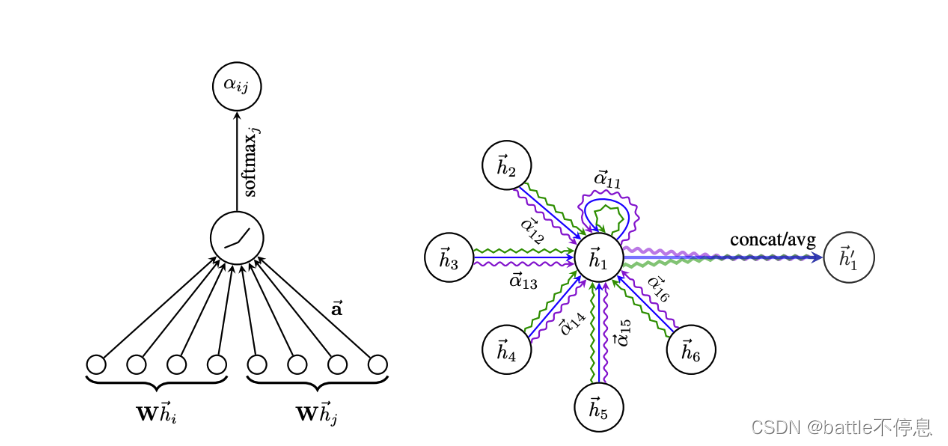
左图,模型采用的注意力机制。右图,多头注意力(K = 3 个头)由其邻域上的节点 1 绘制。
注意力机制具有可训练的参数并且是动态的,与标准的图形卷积网络/ GraphSAGE相比,它们所有消息的权重相等。
接下来将使用Pytorch Geometric PyG,这是建立在Pytorch之上的最受欢迎的图形深度学习框架。PyG适用于快速实现GNN模型,并且已经为与结构化数据相关的各种应用实现了大量的图形模型。
PyG 提供了 MessagePassing 基类,它通过自动处理消息传播来帮助创建此类消息传递图神经网络。基类提供了一些有用的函数。
二、模型建立
1.GAT
我们将使用这些卷积层来创建一个神经网络供我们使用。每一层都由运行卷积层组成,后跟 Relu 非线性函数和 dropout。它们可以多次堆叠形成卷积块,最后我们可以添加一些输出层。

import numpy as np
import pandas as pd
import torch
import matplotlib.pyplot as plt
import torch.nn.functional as F
from torch_geometric.data import Data, DataLoader
import scipy.sparse as sp
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
from sklearn.model_selection import train_test_split
import torch.nn.functional as F
from sklearn.metrics import roc_auc_score
from torch.nn as nn
from torch_geometric.nn import GATConv
class GATv1(nn.Module):
def __init__(self,in_channels,hidden_dim,out_channels,args):
super(GATv1,self).__init__()
self.conv1 = GATConv(in_channels,hidden_dim,heads=args['heads'])
self.conv2 = GATConv(args['heads'] * hidden_dim,hidden_dim,heads=args['heads'])
self.mlp = nn.Sequential(nn.Linear(args['heads'] * hidden_dim,hidden_dim),
nn.Dropout(args['dropout']),
nn.Linear(hidden_dim,out_channels))
def forward(self,data,adj=None):
x, edge_index = data.x, data.edge_index
x = self.conv1(x,edge_index)
x = F.dropout(F.relu(x),p = args['dropout'],training=self.training)
x = self.conv2(x,edge_index)
x = F.dropout(F.relu(x),p = args['dropout'],training=self.training)
x = self.mlp(x)
return F.sigmoid(x)
2.读入数据
代码如下(示例):
数据来自kaggle免费数据,https://www.kaggle.com/ellipticco/elliptic-data-set.
数据处理主要包括读入数据,节点特征,边连接,分类标签处理。未知数据标签为2,非法交易1,正常交易标签为2
features = pd.read_csv('../datasets/archive/elliptic_bitcoin_dataset/elliptic_txs_features.csv',header=None)
classes = pd.read_csv('../datasets/archive/elliptic_bitcoin_dataset/elliptic_txs_classes.csv')
edge_list = pd.read_csv('../datasets/archive/elliptic_bitcoin_dataset/elliptic_txs_edgelist.csv')
## 合并数据集将node_features与classes结合,根据txId列合并
df_merge = features.merge(classes,how='left',right_on='txId',left_on=0)
del features
del classes
import gc
gc.collect()
## 将0列排序,因为0列是节点数据。为下面的映射做准备
df_merge = df_merge.sort_values(0).reset_index(drop=True)
df_merge['class'] = df_merge['class'].map({'unknown': 2, '1':1, '2':0})
nodes = df_merge[0].values
## 将节点数据映射为1,2,3,...
map_id = {j:i for i, j in enumerate(nodes)}
edge_list.txId1 = edge_list.txId1.map(map_id)
edge_list.txId2 = edge_list.txId2.map(map_id)
labels = df_merge['class'] ##标签数据提取
node_features = df_merge.drop([0,1,'txId'],axis=1)
classify_id = node_features['class'].loc[node_features['class'] != 2].index ##分类的数据标签,因为数据中包含未知数据,未知数据是用来测试的
unclassify_id = node_features['class'].loc[node_features['class'] == 2].index ##未知数据标签
llic_classify_id = node_features['class'].loc[node_features['class'] == 0].index ##在分类数据标签的基础上包含非法交易和正常交易数据,把他们分出来
illic_classify_id = node_features['class'].loc[node_features['class'] == 1].index
weights = torch.ones(edge_list.shape[0],dtype=torch.double)##边的权重随机初始化为1
## edge_index转化为 [2,E]形状的tensor 类型为torch.long
edge_index = np.array(edge_list.values).T
edge_index = torch.tensor(edge_index,dtype=torch.long).contiguous()
node_features.drop(['class'],axis=1,inplace=True)
node_features = torch.tensor(np.array(node_features.values),dtype=torch.float)
train_idx,valid_idx = train_test_split(classify_id,test_size=0.2)
## 下面建立数据集
data_train = Data(x = node_features, edge_index=edge_index, edge_attr=weights,y = torch.tensor(labels,dtype=torch.float))
data_train.train_idx = train_idx
data_train.valid_idx = valid_idx
data_train.test_idx = unclassify_id
3.训练数据
class GATtrain(object):
def __init__(self, model):
self.model = model
def train(self, data_train, loss_fn, optimizer,scheduler, args):
for epoch in range(args['epochs']):
self.model.train()
optimizer.zero_grad()
out = self.model(data_train)
out = out.reshape((data_train.x.shape[0]))
loss = loss_fn(out[data_train.train_idx],data_train.y[data_train.train_idx])
target_labels = data_train.y.detach().cpu().numpy()[data_train.train_idx]
pred_scores = out.detach().cpu().numpy()[data_train.train_idx]
pred_labels = pred_scores > 0.5
train_aucroc = roc_auc_score(target_labels, pred_scores)
loss.backward()
optimizer.step()
self.model.eval()
target_labels = data_train.y.detach().cpu().numpy()[data_train.valid_idx]
pred_scores = out.detach().cpu().numpy()[data_train.valid_idx]
pred_labels = pred_scores > 0.5
val_aucroc = roc_auc_score(target_labels, pred_scores)
if epoch % 1 == 0:
print('epoch {} - loss: {:.4f} - accuracy roc: {:.4f} - val roc: {:.4f}'.format(epoch+1,loss.item(), train_aucroc, val_aucroc))
def predict(self, data=None, unclassified_only=True, threshold=0.5):
self.model.eval()
if data is not None:
self.data_train = data
out = self.model(self.data_train)
out = out.reshape((self.data_train.x.shape[0]))
if unclassified_only:
pred_scores = out.detach().cpu().numpy()[self.data_train.test_idx]
else:
pred_scores = out.detach().cpu().numpy()
pred_labels = pred_scores > threshold
return {"pred_scores":pred_scores, "pred_labels":pred_labels}
##配置文件
args={"epochs":10,
'lr':0.01,
'weight_decay':1e-5,
'prebuild':True,
'heads':3,
'hidden_dim': 128,
'dropout': 0.5
}
model = GATv1(data_train.num_node_features, args['hidden_dim'], 1, args)
optimizer = torch.optim.Adam(model.parameters(), lr=args['lr'], weight_decay=args['weight_decay'])
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
loss_fn = torch.nn.BCELoss()
gnn_trainer_gat = GATtrain(model)
gnn_trainer_gat.train(data_train,loss_fn, optimizer, scheduler, args)
结果
epoch 1 - loss: 0.7144 - accuracy roc: 0.5320 - val roc: 0.5362
epoch 2 - loss: 0.9135 - accuracy roc: 0.8391 - val roc: 0.8404
epoch 3 - loss: 0.5545 - accuracy roc: 0.8651 - val roc: 0.8649
epoch 4 - loss: 0.2688 - accuracy roc: 0.8771 - val roc: 0.8800
epoch 5 - loss: 0.2396 - accuracy roc: 0.8875 - val roc: 0.8907
epoch 6 - loss: 0.2668 - accuracy roc: 0.8922 - val roc: 0.8943
epoch 7 - loss: 0.2756 - accuracy roc: 0.8918 - val roc: 0.8889
epoch 8 - loss: 0.2549 - accuracy roc: 0.8868 - val roc: 0.8895
epoch 9 - loss: 0.2324 - accuracy roc: 0.8846 - val roc: 0.8820
epoch 10 - loss: 0.2359 - accuracy roc: 0.8862 - val roc: 0.8808
总结
自己电脑配置问题,所以训练10个epoch,可以后续调参,增加准确度。
后续数据会上传,可能有人下不下来。