1.在schoolInfo数据库中创建一个studentinfo 表,表结构如下:
|
列名 |
含义 |
数据类型 |
长度 |
能否取空值 |
备注 |
|
xh |
学号 |
int |
|
no |
主码 |
|
xm |
姓名 |
char |
8 |
yes |
|
|
xb |
性别 |
char |
2 |
yes |
|
|
nl |
年龄 |
tinyint |
|
yes |
|
|
zy |
专业 |
char |
16 |
yes |
|
|
jtzz |
家庭住址 |
char |
50 |
yes |
|
请按照下列要求进行表定义操作:
(1)首先创建数据库schoolinfo。
create database schoolinfo;

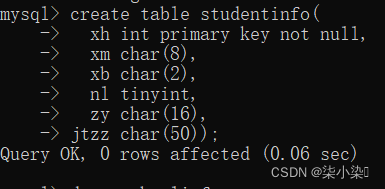
(2)创建 studeninfo 表。
建表之前要选择数据库:
use schoolinfo;
![]()
create table studentinfo(
xh int primary key not null,
xm char(8),
xb char(2),
nl tinyint,
zy char(16),
jtzz char(50))
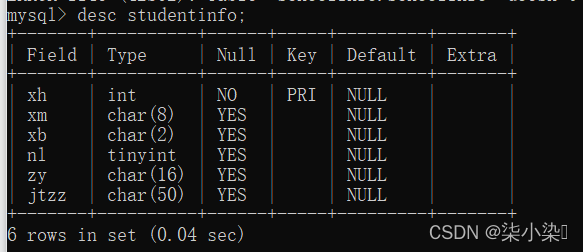
(3)查看表结构
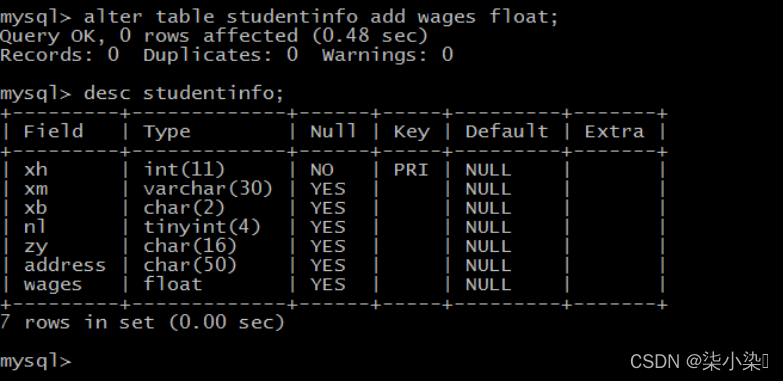
desc studentinfo;
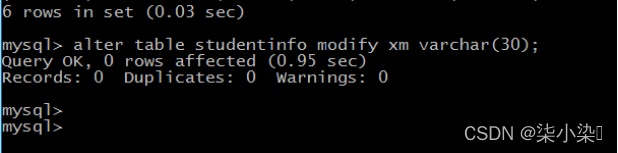
(4)将 studentinfo 表的xm字段的数据类型改为 VARCHAR(30)。
alter table studentinfo modify xm varchar(30);
(5)将studentinfo 表中jtzz字段改名为address,类型与长度不变。
alter table studentinfo change jtzz address char(50);

(6)在 studentinfo 表中增加名为wages的字段,数据类型为FLOAT。
alter table studentinfo add wages float;
(7) 向表格studentinfo中添加如下记录
|
xh (学号) |
xm (姓名) |
xb (性别) |
nl (年龄) |
zy (专业) |
jtzz (家庭住址) |
|
200809412 |
庄小燕 |
女 |
24 |
计算机 |
上海市中山北路12号 |
|
200809415 |
洪波 |
男 |
25 |
计算机 |
青岛市解放路105号 |
|
200109102 |
肖辉 |
男 |
23 |
计算机 |
杭州市凤起路111号 |
|
200109103 |
柳嫣红 |
女 |
22 |
计算机 |
上海市邯郸路1066号 |
|
200307121 |
张正正 |
男 |
20 |
应用数学 |
上海市延安路123号 |
|
200307122 |
李丽 |
女 |
21 |
应用数学 |
杭州市解放路56号 |
insert into studentinfo values(200809412,"庄晓燕","女",21,"计算机","上海市中山北路12号");
insert into studentinfo(xh,xm,xb,nl,zy,jtzz) values(200809415,"洪波","男",25,"计算机","青岛市解放路105号"),
(200109102,"肖辉","男",23,"计算机","杭州市凤起路111号"),
(200109103,"柳嫣红","女",22,"计算机",“null”),
(200307121,"张正正","男",20,"应用数学","上海市延安路123号"),
(200307122,"李丽","女",21,"应用数学","null");

(8)所有男同学的年龄加1岁
update studentinfo set nl=nl+1 where xb="男";

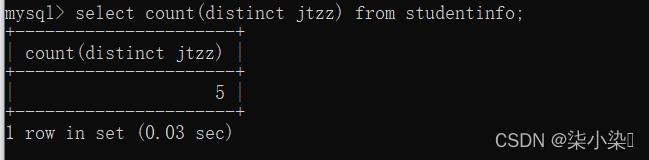
(9)count(*)、count(列名)、count(distinct 列名)三者的区别是什么?通过一个实例说明。
count(字段名):返回select语句检索的行中字段名的值不为NULL的数量。
count(*):统计结果中会包含值为NULL的行数,即所有行数。
count(distinct 列名):查询所查列名的行数,取掉重复的数据,且不允许值为NULL的行数。
例:
表数据如下:
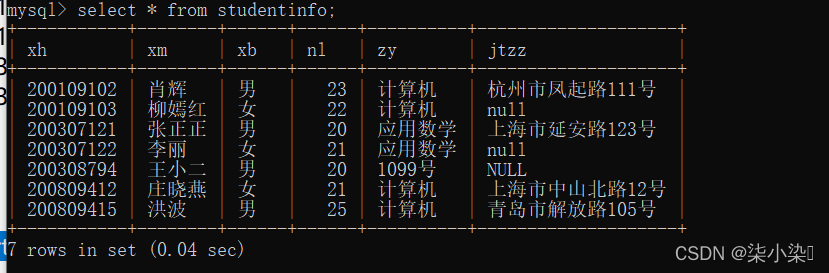
select count(*) from studentinfo;

select count(jtzz) from studentinfo;
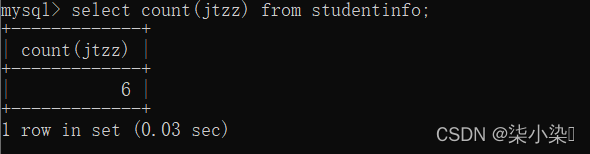
select count(distinct jtzz) from studentinfo;