导读
Pandas可能是广大Python数据分析师最为常用的库了,其提供了从数据读取、数据预处理到数据分析以及数据可视化的全流程操作。其中,在数据读取阶段,应用pd.read_csv读取csv文件是常用的文件存储格式之一。今天,本文就来分享关于pandas读取csv文件时2个非常有趣且有用的参数。

打开jupyter lab,键入pd.read_csv?并运行即可查看该API的常用参数注解,主要如下:
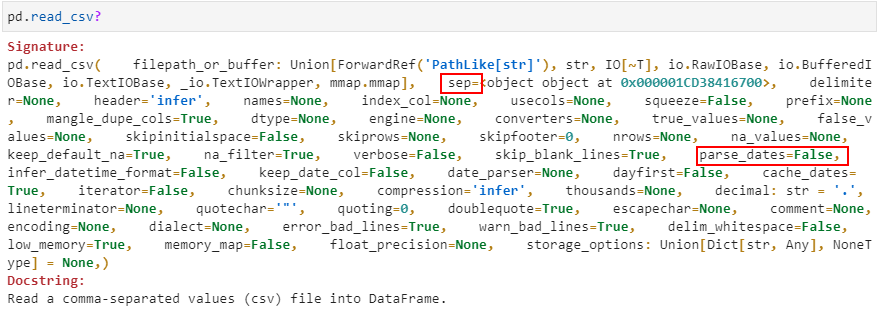
其中大部分参数相信大家都应该已经非常熟悉,本文来介绍2个参数的不一样用法。
给定一个模拟的csv文件,其中主要数据如下:
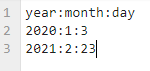
可以看到,这个csv文件主要有3列,列标题分别为year、month和day,但特殊之处在于其分隔符不是常规的comma,而是一个冒号。另外也显而易见的是这三列拼凑起来是一个正常的年月日的日期格式。所以今天本文就来分享如何通过这两个参数来实现巧妙的加载和自动解析。
01 sep设置None触发自动解析
既然是csv文件(Comma-Separated Values),所以read_csv的默认sep是”,”,然而对于那些不是”,”分隔符的文件,该默认参数下显然是不能正确解析的。此时,当然可以简单的通过传入正确的分隔符作为sep参数来实现正确加载,但如果文件的分隔符是未知的呢?实际上,我们可以无需传入分隔符,而交由解析器自动解析。
查看pd.read_csv中关于sep参数的介绍,可以看到如下说明:

其中,值得注意的有两点:
-
sep默认为”,”,如果传入None,则C引擎由于不能自动检测和解析分隔符,所以Python引擎将会自动应用于解析和检测(当然,C引擎的解析速度要更快一些,所以实际上这两种解析引擎是各有利弊)
-
如果sep传入参数超过1个字符,则其将会被视作正则表达式。实际上这也是一个强大的功能,但应用场景不如前者实用
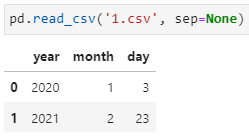
基于上述对sep参数的理解,为了正确加载和解析前述的示例文件,只需将传入sep=None即可:
02 parse_dates实现日期多列拼接
在完成csv文件正确解析的基础上,下面通过parse_dates参数实现日期列的拼接。首先仍然是查看API文档中关于该参数的注解:

其中,可以看出parse_dates参数默认为False,同时支持4种自定义格式的参数的传递,包括:
-
传入bool值,若传入True值,则将尝试解析索引列
-
传入列表,并将列表中的每一列尝试解析为日期格式;
-
传入嵌套列表,并尝试将每个子列表中的所有列拼接后解析为日期格式;
-
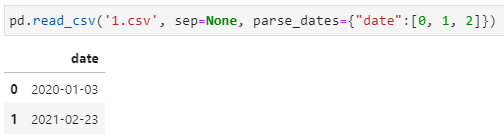
出啊如字典,其中key为解析后的新列名,value为原文件中的待解析的列索引的列表,例如示例中{‘foo’: [1, 3]}即是用于将原文件中的1和3列拼接解析,并重命名为foo
基于上述理解,完成前面的特殊csv文件中三列拼接解析为日期的需求就非常容易,即将0/1/2列拼接解析就可以了。实现如下:
不得不说,pandas提供的这些函数的参数可真够丰富的了!
相关阅读: