最近读了hashmap的源码,以下简单谈谈我对于hashmap源码的理解。
java标准库中hashmap就是基于拉链法,底层是一个数组,数组每一项又是一个链表。
拉链法解释:拉链法是解决哈希冲突的一种行之有效的方法,某些哈希地址可以被多个关键字值共享,这样可以针对每个哈希地址建立一个单链表。在拉链(单链表)的哈希表中搜索一个记录是容易的,首先计算哈希地址,然后搜索该地址的单链表。
效果图如下:
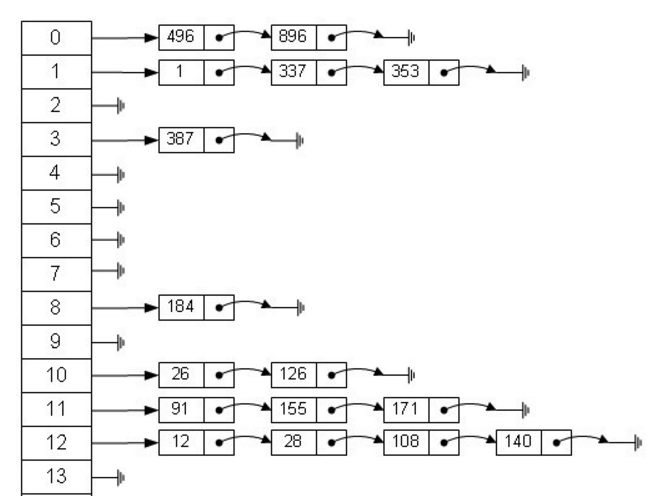
但在jdk1.8以后,当链表中节点数量超过边界(TREEIFY_THRESHOLD=8)并且满足表长>MIN_TREEIFY_CAPACITY=64时,就会将桶中节点存储的形式由链表变成红黑树,其目的主要在于节约put以及get等操作的时间。
桶(bucket):hash的格子
默认负载因子(
DEFAULT_LOAD_FACTOR
)为0.75,
负载因子:键值对数/桶数。
扩容阈值(threshold):为负载因子乘以表长,当hashmap的size大于该值时就会进行resize扩容。
接下来简单看看put,主要核心代码如下:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}可以得知主要是先判断如果表没初始化就进行resize,resize在这里主要是给这个表创建一个默认的容量(DEFAULT_INITIAL_CAPACITY=16),接着通过对key取hash值再和表长求余找到相应的桶,如果相应的桶中没东西,就创建并放入。如果有则判断是list形式还是tree形式,进行查找,没有则put进去。注意在list形式下当满足上文所提到的树化条件时,就会将list形式变为tree形式。最后进行判断put了之后是否超过了临界值(threshold),超过了就会进行resize扩容。所以可以看出
看到这里大家应该会想考虑resize中的细节,我会在最后写出,先放一下,接着来看get方法。
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}可以发现get方法中代码相对而言比较好理解,主要是先判断桶中第一个节点是不是key值,如果不是就根据节点的存放形式进行遍历取值。
接下来谈一下 resize
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}可以看到resize的扩容是创建一个新的列表来替代旧的表,并且通过( newCap = oldCap << 1)可以看出扩容是每次扩容两倍。重点在于原来桶里面的东西如何放入新的表中。源码是先判断桶中只有一个节点的话就直接让hash值与新容量求余,如果桶中存在多个节点的话,就判断是以树的结构还是链表的结构。先说链表结构的情况:注意这一句话if ((e.hash & oldCap) == 0)实际上将节点均匀的分成了两部分,一部分放入了原来那个序号(j)的桶中,另一部分放入了原来那个序号加上原容量(j+oldcap)的桶中。就是判断那个hash值容量的那一位二进制是0还是1,这实际上是一种十分巧妙的办法,不需要重新计算hash值就可以实现很好的分配。这个时候我想如果oldCap的二进制不是“1000….”这种格式而是“10101…”这种格式怎么办,那结果为0和不为0就不是很均匀的各为1/2的概率了,然后我去看了hashmap设初始容量的代码,发现有这个方法保证了容量一定是2的整数次幂。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}注意如果对于那个构造函数中threshold = tableSizeFor(t); 有疑问,可以看一下看一下resize就是以这个作为容量,修改threshold为容量乘以负载因子进行替换。
所以操作的结果为把原来桶的链表均匀的分为原来桶位置链表和原位置加上容量的桶链表。
接下来看一下树型存放的源码:
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}和链表型式大致是相同的,就是多了判别如果低于阈值(UNTREEIFY_THRESHOLD=6)时,就进行链表化。
以上为我对于hashmap源码的简单理解,如果有错误请在评论区指出,我马上改正,谢谢观看。